

All'inizio del mese Google ha annunciato con orgoglio che il suo modello Gemini più potente ha battuto GPT-4 nei test di benchmark Massive Multitask Language Understanding MMLU. La nuova tecnica di prompting di Microsoft vede il GPT-4 riconquistare il primo posto, anche se di una frazione di punto percentuale.
Al di là del dramma legato al suo video di marketing, Gemini di Google è un grande affare per l'azienda e i risultati del benchmark MMLU sono impressionanti. Ma Microsoft, il maggiore investitore di OpenAI, non ha aspettato a lungo per gettare ombra sugli sforzi di Google.
Il titolo è che Microsoft ha fatto in modo che GPT-4 battesse i risultati MMLU di Gemini Ultra. La realtà è che ha battuto il punteggio di 90,04% di Gemini di appena 0,06%.
La storia di ciò che ha reso possibile questo risultato è più eccitante dell'incremento delle prestazioni che vediamo in queste classifiche. Le nuove tecniche di prompting di Microsoft potrebbero aumentare le prestazioni dei modelli di IA più vecchi.
Ricordate che Gemini Ultra di Google ha appena battuto GPT-4 per diventare la migliore AI?
Ebbene, Microsoft ha appena dimostrato che, con una richiesta adeguata, GPT-4 batte effettivamente Gemini nei benchmark.
C'è molto spazio per i guadagni anche con i modelli più vecchi. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12 dicembre 2023
Medprompt
Quando si parla di "pilotare" un modello, si intende semplicemente che, con un'attenta guida, è possibile orientare il modello in modo da ottenere un risultato più in linea con le proprie esigenze.
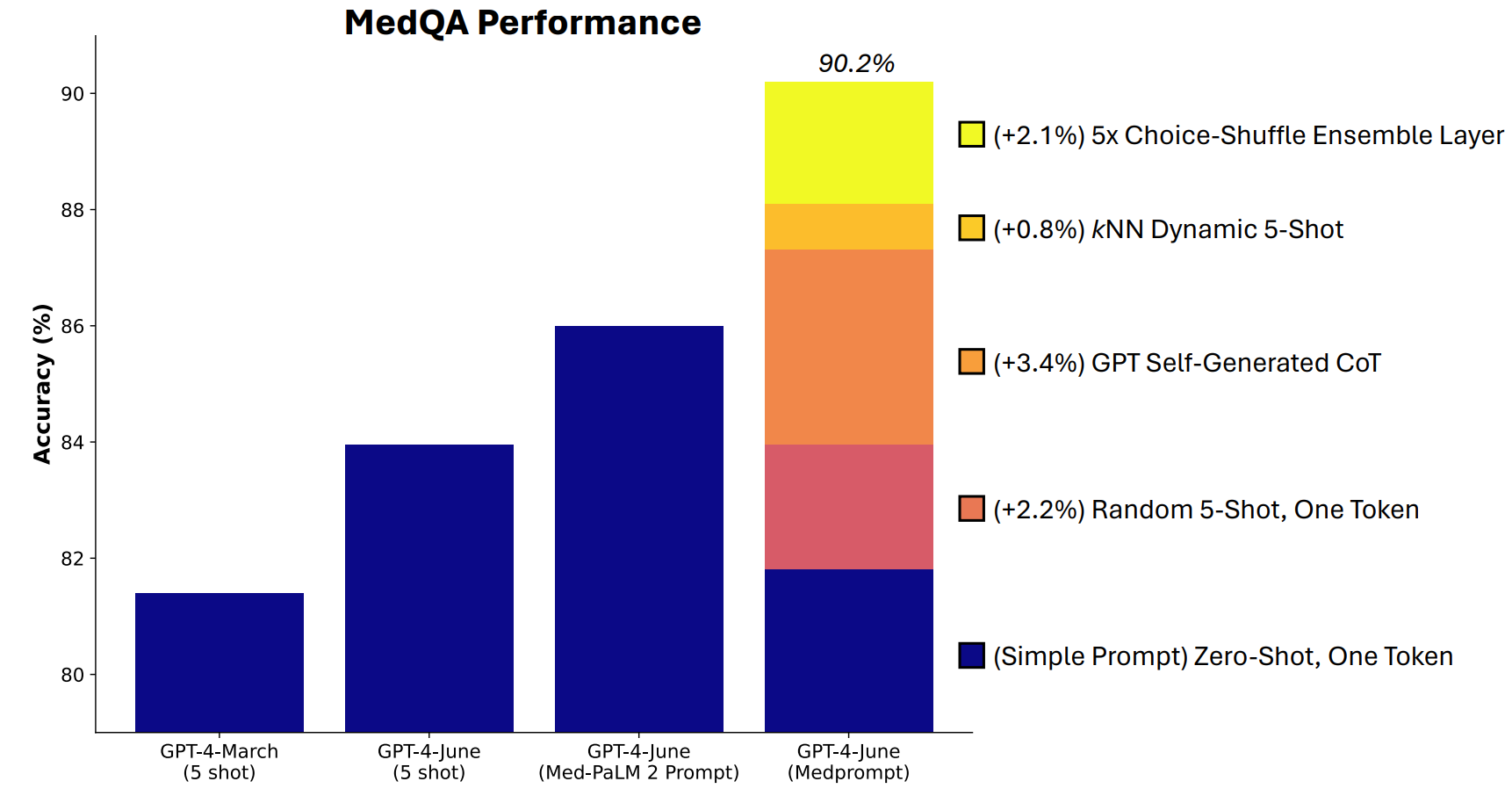
Microsoft ha sviluppato una combinazione di tecniche di prompting che si sono rivelate molto efficaci in questo senso. Medprompt è iniziato come un progetto per far sì che il GPT-4 fornisca risposte migliori su benchmark di sfide mediche come la suite di test MultiMedQA.
I ricercatori di Microsoft hanno pensato che se Medprompt funzionava bene nei test medici specialistici, avrebbe potuto migliorare anche le prestazioni generaliste di GPT-4. E così Microsoft e OpenAI hanno riconquistato i diritti di GPT-4 rispetto a Gemini Ultra.
Come funziona Medprompt?
Medprompt è una combinazione di tecniche di prompt intelligenti, tutte riunite in una sola. Si basa su tre tecniche principali.
Apprendimento dinamico a pochi colpi (DFSL)
L'"apprendimento a pochi colpi" si riferisce al fatto di fornire al GPT-4 alcuni esempi prima di chiedergli di risolvere un problema simile. Quando si vede un riferimento come "5-shot" significa che al modello sono stati forniti 5 esempi. "Zero-shot" significa che ha dovuto rispondere senza alcun esempio.
Il documento di Medprompt spiega che "per semplicità ed efficienza, gli esempi di pochi colpi applicati nel prompting per un particolare compito sono tipicamente fissi; sono invariati tra gli esempi di test".
Il risultato è che gli esempi che vengono presentati ai modelli sono spesso solo ampiamente rilevanti o rappresentativi.
Se il set di addestramento è sufficientemente grande, è possibile far sì che il modello esamini tutti gli esempi e scelga quelli che sono semanticamente simili al problema che deve risolvere. Il risultato è che gli esempi di apprendimento a pochi colpi sono più specificamente allineati con un particolare problema.
Catena di pensiero autogenerata (CoT)
Il suggerimento della catena di pensiero (CoT) è un ottimo modo per guidare un LLM. Quando lo si sollecita con "pensa attentamente" o "risolvi passo dopo passo", i risultati migliorano notevolmente.
Si può essere molto più specifici nel guidare la catena di pensiero che il modello deve seguire, ma questo comporta un'ingegneria manuale immediata.
I ricercatori hanno scoperto che "potevano semplicemente chiedere a GPT-4 di generare catene di pensiero per gli esempi di addestramento". In pratica, il loro approccio dice a GPT-4: "Ecco una domanda, le opzioni di risposta e la risposta corretta. Quali sono le CoT da includere in un prompt che porti a questa risposta?".
Scelta di un ensemble di mischia
La maggior parte dei test di benchmark MMLU sono domande a scelta multipla. Quando un modello di intelligenza artificiale risponde a queste domande, può essere preda di pregiudizi posizionali. In altre parole, potrebbe favorire l'opzione B nel tempo anche se non è sempre la risposta giusta.
L'ensembling delle scelte mescola le posizioni delle opzioni di risposta e fa sì che GPT-4 risponda nuovamente alla domanda. Questa operazione viene ripetuta più volte e la risposta più frequentemente scelta viene selezionata come risposta finale.
La combinazione di queste tre tecniche di prompt è ciò che ha dato a Microsoft l'opportunità di gettare un po' di ombra sui risultati di Gemini. Sarà interessante vedere quali risultati otterrebbe Gemini Ultra se utilizzasse un approccio simile.
Medprompt è interessante perché dimostra che i modelli più vecchi possono funzionare ancora meglio di quanto pensassimo se li sollecitiamo in modo intelligente. Tuttavia, la potenza di elaborazione necessaria per questi passaggi aggiuntivi potrebbe non renderlo un approccio praticabile nella maggior parte degli scenari.



