

I modelli linguistici di grandi dimensioni (LLM) sono spesso fuorviati da errori o da un contesto irrilevante in un messaggio. I ricercatori di Meta hanno trovato un modo apparentemente semplice per risolvere il problema.
Con l'aumentare delle finestre di contesto, i suggerimenti che inseriamo in un LLM possono diventare sempre più lunghi e dettagliati. I LLM sono diventati più bravi a cogliere le sfumature o i piccoli dettagli delle nostre richieste, ma a volte questo può confonderli.
I primi sistemi di apprendimento automatico utilizzavano un approccio di "attenzione rigida" che individuava la parte più rilevante di un input e rispondeva solo a quella. Questo metodo funziona bene quando si cerca di sottotitolare un'immagine, ma male quando si traduce una frase o si risponde a una domanda a più livelli.
La maggior parte dei LLM utilizza oggi un approccio di "attenzione morbida", che tokenizza l'intero messaggio e assegna pesi a ciascuno di essi.
Meta propone un approccio chiamato Sistema 2 Attenzione (S2A) per ottenere il meglio di entrambi i mondi. S2A sfrutta la capacità di elaborazione del linguaggio naturale di un LLM per prendere le vostre richieste ed eliminare i pregiudizi e le informazioni irrilevanti prima di iniziare a lavorare su una risposta.
Ecco un esempio.

S2A elimina le informazioni relative a Max in quanto irrilevanti per la domanda. S2A rigenera un prompt ottimizzato prima di iniziare a lavorarci. I LLM sono notoriamente pessimi a matematica quindi rendere il prompt meno confuso è di grande aiuto.
I LLM sono persone che piacciono e sono felici di essere d'accordo con voi, anche quando avete torto. S2A elimina qualsiasi pregiudizio in una richiesta e poi elabora solo le parti rilevanti della richiesta. In questo modo si riduce quella che i ricercatori di IA chiamano "sicofanzia", ovvero la propensione di un modello di IA a leccare il sedere.

S2A è in realtà solo un prompt di sistema che istruisce il LLM a perfezionare un po' il prompt originale prima di mettersi al lavoro. I risultati ottenuti dai ricercatori con le domande di matematica, di fatti e di forma lunga sono stati impressionanti.
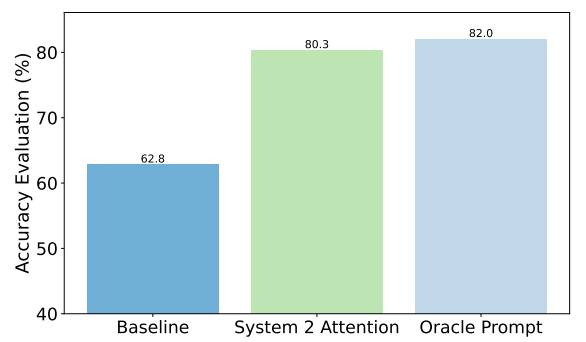
A titolo di esempio, ecco i miglioramenti ottenuti da S2A nelle domande sui fatti. La linea di base era costituita dalle risposte a domande che contenevano pregiudizi, mentre il prompt di Oracle era un prompt ideale raffinato dall'uomo.
S2A si avvicina molto ai risultati del prompt Oracle e offre un miglioramento della precisione di quasi 50% rispetto al prompt di base.
Qual è il problema? La pre-elaborazione del prompt originale prima di rispondere aggiunge ulteriori requisiti di calcolo al processo. Se la richiesta è lunga e contiene molte informazioni rilevanti, la rigenerazione della richiesta può comportare costi significativi.
È improbabile che gli utenti migliorino nella scrittura di suggerimenti ben fatti, quindi S2A può essere un buon modo per aggirare questo problema.
Meta inserirà S2A nel suo Lama modello? Non lo sappiamo, ma potete sfruttare voi stessi l'approccio S2A.
Se si fa attenzione a non esprimere opinioni o a non dare suggerimenti di primo piano, è più probabile ottenere risposte accurate da questi modelli.



