

Nvidia ha scalato e ottimizzato il suo supercomputer Eos AI per stabilire nuovi record di benchmark di addestramento MLPerf AI.
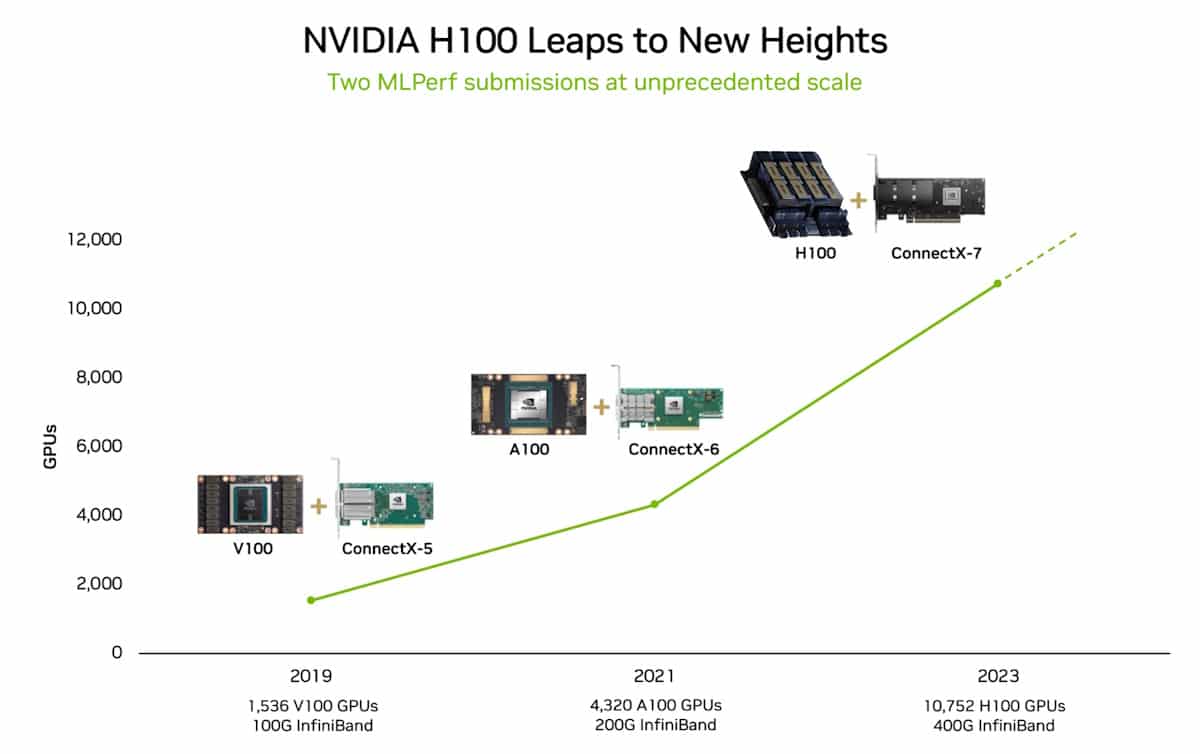
Quando Nvidia ha acceso il suo supercomputer di intelligenza artificiale Eos a maggio, 10.752 GPU NVIDIA H100 Tensor Core hanno preso vita e sono appena state sottoposte a test reali.
Questa potenza di elaborazione senza precedenti, insieme alle nuove ottimizzazioni del software, ha permesso a Eos di spingere l'MLPerf parametro di riferimento in un territorio da record.
Il benchmark open-source MLPerf è un insieme di test di addestramento e inferenza progettati per misurare le prestazioni dei carichi di lavoro di apprendimento automatico su insiemi di dati reali.
Uno dei risultati più significativi è che Eos è stato in grado di addestrare un modello GPT-3 con 175 miliardi di parametri su un miliardo di token in soli 3,9 minuti.
Quando Nvidia ha stabilito il record su questo benchmark, meno di 6 mesi fa, ha impiegato quasi 3 volte di più, con un tempo di 10,9 minuti.
Nvidia è stata anche in grado di raggiungere un tasso di efficienza di 93% durante i test, il che significa che ha utilizzato quasi tutta la potenza di calcolo teoricamente disponibile in Eos.
Microsoft Azure, che utilizza più o meno la stessa configurazione H100 di Eos nella sua macchina virtuale ND H100 v5, è arrivata a 2% dai risultati di Nvidia nei suoi test MLPerf.
Nel 2018 Jensen Huang, il CEO di Nvidia, ha dichiarato che le prestazioni delle GPU raddoppieranno ogni due anni. Questa affermazione è stata coniata come legge di Haung e si è dimostrata vera, in quanto lascia Scomparsa della Legge di Moore nello specchietto retrovisore informatico.
E allora?
Il test di addestramento del benchmark MLPerf che Nvidia ha superato utilizza solo una porzione del dataset completo su cui è stato addestrato GPT-3. Se si prende il tempo stabilito da Eos nel test MLPerf e lo si estrapola per l'intero dataset GPT-3, si potrebbe addestrare l'intero modello in soli 8 giorni.
Se si tentasse di farlo utilizzando il precedente sistema all'avanguardia composto da 512 GPU A100, sarebbero necessari circa 170 giorni.
Se doveste addestrare un nuovo modello di intelligenza artificiale, riuscite a immaginare la differenza in termini di time to market e di costi che rappresenta 8 giorni rispetto a 170 giorni?
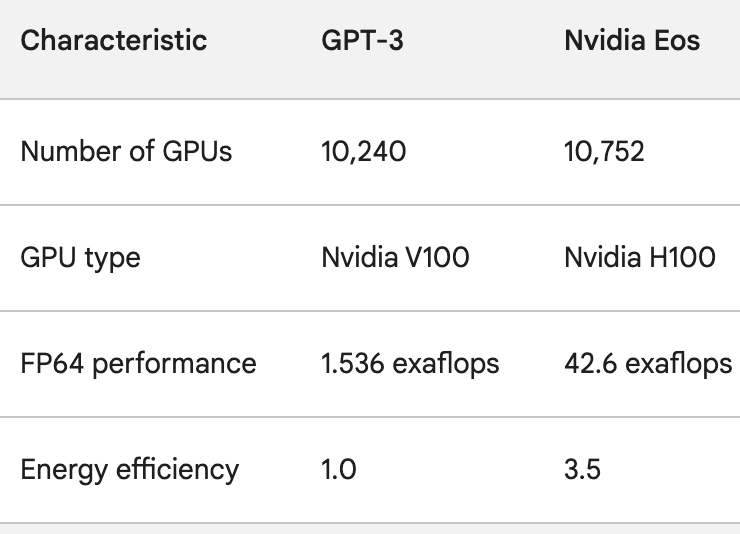
Le GPU H100 non solo sono molto più potenti delle GPU A100, ma sono anche fino a 3,5 volte più efficienti dal punto di vista energetico. Utilizzo di energia e L'impronta di carbonio dell'AI sono problemi reali che devono essere affrontati.
Per avere un'idea della rapidità con cui l'elaborazione dell'intelligenza artificiale sta migliorando, basti pensare a ChatGPT, che è stato lanciato poco meno di un anno fa. Il modello sottostante, GPT-3, è stato addestrato su 10.240 GPU Nvidia V100.
Meno di un anno dopo, Eos ha una potenza di elaborazione 28 volte superiore a quella configurazione, con un miglioramento dell'efficienza di 3,5 volte.
Quando Sam Altman di OpenAI ha concluso il recente DevDay, ha detto che i progetti a cui OpenAI stava lavorando avrebbero fatto sembrare pittoresche le sue ultime versioni.
Considerando il salto di potenza di elaborazione che aziende come Nvidia stanno ottenendo, l'affermazione di Altman probabilmente riassume il futuro dell'industria dell'IA nel suo complesso.



