

Il colonialismo digitale si riferisce al dominio dei giganti tecnologici e delle entità potenti sul paesaggio digitale, che plasmano il flusso di informazioni, conoscenza e cultura per servire i loro interessi.
Questo dominio non riguarda solo il controllo dell'infrastruttura digitale, ma anche l'influenza sulle narrazioni e sulle strutture di conoscenza che definiscono la nostra era digitale.
Il colonialismo digitale, e ora anche il colonialismo dell'intelligenza artificiale, sono termini ampiamente riconosciuti, e istituzioni come Il MIT ha svolto ricerche e scritto su ampiamente.
Ricercatori di spicco di Anthropic, Google, DeepMind e altre aziende tecnologiche hanno discusso apertamente della portata limitata dell'IA nel servire persone provenienti da contesti diversi, in particolare in riferimento a sbieco nei sistemi di apprendimento automatico.
Sistemi di apprendimento automatico friflettono fondamentalmente i dati su cui sono stati addestrati, dati che cotrebbe essere visto come un prodotto del nostro Zeitgeist digitale - un insieme di narrazioni, immagini e idee prevalenti che dominano il mondo online.
Ma chi può dare forma a queste forze informative? Quali voci vengono amplificate e quali attenuate?
Quando l'IA apprende dai dati di addestramento, eredita specifiche visioni del mondo che potrebbero non necessariamente risuonare o rappresentare le culture e le esperienze globali. Inoltre, i controlli che governano l'output degli strumenti di IA generativa sono modellati da vettori socioculturali sottostanti.
Questo ha portato gli sviluppatori come Anthropic a cercare metodi democratici di modellare il comportamento dell'IA utilizzando le opinioni pubbliche.
Come ha descritto Jack Clark, responsabile delle politiche di Anthropic, un esperimento recente della sua azienda: "Stiamo cercando di trovare un modo per sviluppare una costituzione che sia sviluppata da un gruppo di terze parti, piuttosto che da persone che lavorano in un laboratorio di San Francisco".
Gli attuali paradigmi di addestramento dell'IA generativa rischiano di creare una camera d'eco digitale in cui le stesse idee, gli stessi valori e le stesse prospettive vengono continuamente rafforzati, consolidando ulteriormente il dominio di coloro che sono già sovrarappresentati nei dati.
Man mano che l'IA si inserisce in processi decisionali complessi, da assistenza sociale e reclutamento a decisioni finanziarie e diagnosi medicheLa rappresentazione sbilanciata porta a pregiudizi e ingiustizie nel mondo reale.
I set di dati sono situati geograficamente e culturalmente
Un recente studio della Data Provenance Initiative ha analizzato 1.800 dataset popolari destinati all'elaborazione del linguaggio naturale (NLP), una disciplina dell'IA che si concentra sul linguaggio e sul testo.
La PNL è la metodologia di apprendimento automatico dominante alla base dei modelli linguistici di grandi dimensioni (LLM), tra cui ChatGPT e i modelli Llama di Meta.
Lo studio rivela un'inclinazione occidentale-centrica nella rappresentazione delle lingue nei set di dati, con l'inglese e le lingue dell'Europa occidentale che definiscono i dati di testo.
Le lingue delle nazioni asiatiche, africane e sudamericane sono nettamente sottorappresentate.
Di conseguenza, i LLM non possono sperare di rappresentare accuratamente le sfumature linguistico-culturali di queste regioni nella stessa misura delle lingue occidentali.
Anche quando le lingue del Sud globale appaiono rappresentate, la fonte e il dialetto della lingua provengono principalmente da creatori e fonti web nordamericani o europei.

A precedente Esperimento antropico hanno scoperto che il cambio di lingua in modelli come ChatGPT produceva ancora opinioni e stereotipi occidentali nelle conversazioni.
I ricercatori antropici hanno concluso: "Se un modello linguistico rappresenta in modo sproporzionato alcune opinioni, rischia di imporre effetti potenzialmente indesiderabili, come la promozione di visioni del mondo egemoniche e l'omogeneizzazione delle prospettive e delle credenze delle persone".
Lo studio sulla Data Provenance ha anche analizzato il panorama geografico della cura dei dataset. Le organizzazioni accademiche emergono come i principali motori, contribuendo a 69% dei set di dati, seguite dai laboratori industriali (21%) e dagli istituti di ricerca (17%).
In particolare, i maggiori contributori sono AI2 (12,3%), l'Università di Washington (8,9%) e Facebook AI Research (8,4%).
A studio separato 2020 evidenzia che la metà dei set di dati utilizzati per la valutazione dell'IA in circa 26.000 articoli di ricerca provengono da appena 12 università e aziende tecnologiche di alto livello.
Anche in questo caso, aree geografiche come l'Africa, l'America meridionale e centrale e l'Asia centrale sono risultate tristemente sottorappresentate, come illustrato di seguito.
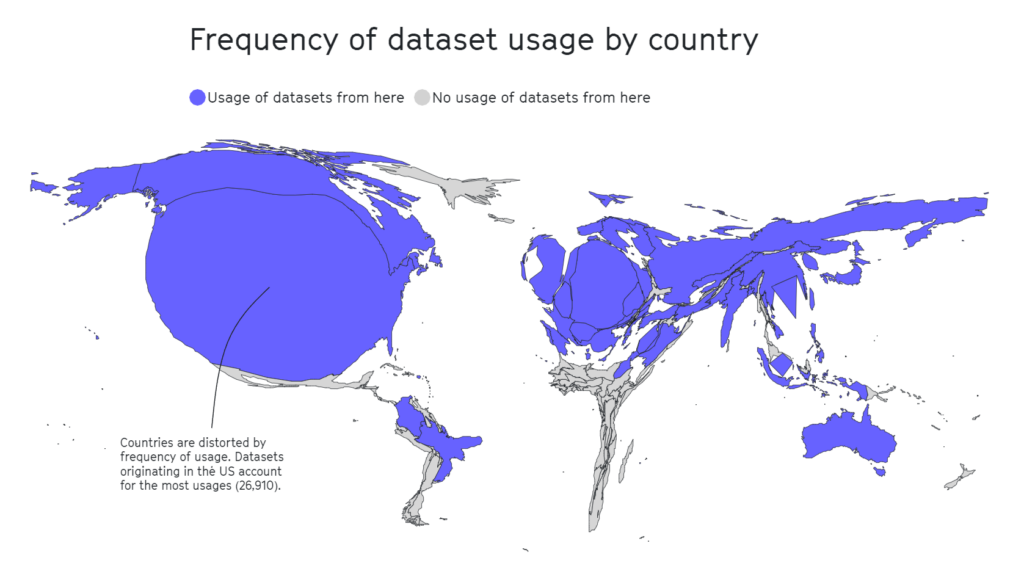
In altre ricerche, dataset influenti come Tiny Images del MIT o Labeled Faces in the Wild contenevano principalmente immagini di uomini bianchi occidentali, con circa 77,5% maschi e 83,5% individui dalla pelle bianca nel caso di Labeled Faces in the Wild.
Nel caso di Tiny Images, un 2020 analisi di The Register ha rilevato che molte Tiny Images contenevano etichette oscene, razziste e sessiste.
Antonio Torralba del MIT ha dichiarato che non erano a conoscenza delle etichette e che il set di dati è stato cancellato. Torralba ha dichiarato: "È chiaro che avremmo dovuto controllarli manualmente".
L'inglese domina l'ecosistema dell'IA
Pascale Fung, informatico e direttore del Center for AI Research dell'Università di Scienza e Tecnologia di Hong Kong, ha discusso i problemi associati all'IA egemonica.
Fung fa riferimento a più di 15 ricerche che indagano sulla competenza multilingue dei LLM e che li trovano costantemente carenti, in particolare quando traducono l'inglese in altre lingue. Ad esempio, le lingue con scritture non latine, come il coreano, evidenziano i limiti dei LLM.
Oltre allo scarso supporto multilingue, altri studi suggeriscono che la maggior parte dei benchmark e delle misure di bias sono stati sviluppati tenendo conto dei modelli in lingua inglese.
I parametri di riferimento per i bias non inglesi sono pochi e molto distanti tra loro, il che comporta una lacuna significativa nella nostra capacità di valutare e correggere i bias nei modelli linguistici multilingue.
Ci sono segnali di miglioramento, come gli sforzi di Google con il suo modello linguistico PaLM 2 e il suo modello linguistico PaLM. Meta's Discorso massicciamente multilingue (MMS) che può identificare più di 4.000 lingue parlate, 40 volte di più rispetto ad altri approcci. Tuttavia, l'MMS rimane sperimentale.
I ricercatori stanno creando insiemi di dati multilingue diversi, ma l'enorme quantità di dati testuali in inglese, spesso gratuiti e di facile accesso, li rende la scelta di fatto degli sviluppatori.
Oltre i dati: questioni strutturali nel lavoro dell'IA
La vasta rassegna del MIT sul colonialismo dell'IA ha richiamato l'attenzione su un aspetto relativamente nascosto dello sviluppo dell'IA: le pratiche di sfruttamento del lavoro.
L'intelligenza artificiale ha innescato un'intensa crescita della domanda di servizi di etichettatura dei dati. Aziende come Appen e Sama sono emerse come attori chiave, offrendo servizi di etichettatura di testi, immagini e video, ordinamento di foto e trascrizione di audio per alimentare i modelli di apprendimento automatico.
Gli specialisti di dati umani etichettano anche manualmente i tipi di contenuto, spesso per classificare i dati che contengono contenuti illegali, illeciti o non etici, come descrizioni di abusi sessuali, comportamenti dannosi o altre attività illegali.
Sebbene le aziende di IA automatizzino alcuni di questi processi, è comunque fondamentale mantenere gli "umani nel giro" per garantire l'accuratezza del modello e la conformità alla sicurezza.
Il valore di mercato di questo "lavoro fantasma", come lo definiscono l'antropologa Mary Gray e lo scienziato sociale Siddharth Suri, si prevede che sia pari a a $13,7 miliardi di euro entro il 2030..
Il lavoro fantasma spesso comporta lo sfruttamento di manodopera a basso costo, in particolare da Paesi economicamente vulnerabili. Il Venezuela, ad esempio, è diventato una fonte primaria di manodopera legata all'IA a causa della sua crisi economica.
Mentre il Paese era alle prese con la peggiore catastrofe economica del periodo di pace e con un'inflazione astronomica, una parte significativa della popolazione istruita e connessa a Internet si è rivolta alle piattaforme di crowd-working come mezzo di sopravvivenza.
La confluenza di una forza lavoro ben istruita e della disperazione economica ha reso il Venezuela un mercato interessante per le aziende di etichettatura dei dati.
Non si tratta di un punto controverso: quando il MIT pubblica articoli con titoli come "L'intelligenza artificiale sta creando un nuovo ordine coloniale mondialeriferendosi a scenari come questo, è chiaro che alcuni operatori del settore cercano di far calare il sipario su queste pratiche lavorative subdole.
Come riporta il MIT, per molti venezuelani la fiorente industria dell'intelligenza artificiale è stata un'arma a doppio taglio. Se da un lato ha fornito un'ancora di salvezza economica in mezzo alla disperazione, dall'altro ha esposto le persone allo sfruttamento.
Julian Posada, dottorando presso l'Università di Toronto, sottolinea gli "enormi squilibri di potere" di questi accordi di lavoro. Le piattaforme dettano le regole, lasciando ai lavoratori poca voce in capitolo e un compenso economico limitato nonostante le sfide sul lavoro, come l'esposizione a contenuti inquietanti.
Questa dinamica ricorda in modo inquietante le pratiche coloniali storiche, in cui gli imperi sfruttavano la manodopera di Paesi vulnerabili, estraendo profitti e abbandonandoli una volta esaurita l'opportunità, spesso perché "meglio" disponibili altrove.
Situazioni simili sono state osservate a Nairobi, in Kenya, dove un gruppo di ex moderatori di contenuti che lavoravano su ChatGPT ha presentato una petizione con il governo keniota.
I firmatari hanno denunciato "condizioni di sfruttamento" durante il loro periodo di lavoro presso Sama, una società di servizi di annotazione dei dati con sede negli Stati Uniti, appaltata da OpenAI. I firmatari hanno affermato di essere stati esposti a contenuti inquietanti senza un adeguato supporto psicosociale, causando gravi problemi di salute mentale, tra cui PTSD, depressione e ansia.

Documenti recensito da TIME ha indicato che OpenAI aveva firmato contratti con Sama per un valore di circa $200.000. Questi contratti prevedevano l'etichettatura di descrizioni di abusi sessuali, discorsi di odio e violenza.
L'impatto sulla salute mentale dei lavoratori è stato profondo. Mophat Okinyi, un ex moderatore, ha parlato del tributo psicologico, descrivendo come l'esposizione a contenuti grafici abbia portato alla paranoia, all'isolamento e a significative perdite personali.
I salari per un lavoro così penoso erano scandalosamente bassi: un portavoce della Sama ha rivelato che i lavoratori guadagnavano tra $1,46 e $3,74 all'ora.
Resistere al colonialismo digitale
Se l'industria dell'intelligenza artificiale è diventata una nuova frontiera del colonialismo digitale, la resistenza sta già diventando più coesa.
Gli attivisti, spesso sostenuti dai ricercatori di IA, si battono per la responsabilità, per i cambiamenti politici e per lo sviluppo di tecnologie che diano priorità ai bisogni e ai diritti delle comunità locali.
Nanjala Nyabola Progetto per i diritti digitali in kiswahili offre un esempio innovativo di come i progetti di base su scala locale possano installare l'infrastruttura necessaria a proteggere le comunità dall'egemonia digitale.
Il progetto considera l'egemonia delle normative occidentali nel definire i diritti digitali di un gruppo, poiché non tutti sono protetti dalle leggi sulla proprietà intellettuale, sul copyright e sulla privacy che molti di noi danno per scontate. Ciò lascia una percentuale significativa della popolazione globale soggetta allo sfruttamento da parte delle aziende tecnologiche.
Riconoscendo che i dibattiti sui diritti digitali sono offuscati se le persone non possono comunicare le questioni nella loro lingua madre, Nyabola e il suo team hanno tradotto i termini chiave dei diritti digitali e della tecnologia nella lingua kiswahili, parlata principalmente in Tanzania, Kenya e Mozambico.
Nyabola Descrizione del progettoDurante il processo [dell'iniziativa Huduma Namba], non avevamo il linguaggio e gli strumenti per spiegare alle comunità non specializzate o non di lingua inglese in Kenya quali fossero le implicazioni dell'iniziativa".
In un progetto di base simile, Te Hiku Media, una stazione radio senza scopo di lucro che trasmette principalmente in lingua Māori, ha conservato un vasto database di registrazioni che coprono decenni, molte delle quali riecheggiano le voci di frasi ancestrali non più pronunciate.
I modelli di riconoscimento vocale tradizionali, simili agli LLM, tendono a non dare risultati quando vengono richiesti in lingue diverse o in dialetti inglesi.
Il Te Hiku Media ha collaborato con ricercatori e tecnologie open-source per addestrare un modello di riconoscimento vocale su misura per la lingua Māori. L'attivista māori Te Mihinga Komene ha contribuito con circa 4.000 frasi, insieme a innumerevoli altri partecipanti al progetto.
Il modello risultante e i dati sono protetti ai sensi della Licenza Kaitiakitanga - Kaitiakitanga è una parola Māori senza una specifica definizione inglese, ma è simile a "guardiano" o "custode".
Keoni Mahelona, cofondatore di Te Hiku Media, ha commentato in modo toccante: "I dati sono l'ultima frontiera della colonizzazione".
Questi progetti hanno ispirato altre comunità indigene e native sottoposte alla pressione del colonialismo digitale e di altre forme di sconvolgimento sociale, come i popoli Mohawk in Nord America e i nativi hawaiani.
Man mano che l'IA open-source diventa più economica e di più facile accesso, l'iterazione e la messa a punto dei modelli utilizzando set di dati unici e localizzati dovrebbe diventare più semplice, migliorando l'accesso interculturale alla tecnologia.
Sebbene l'industria dell'IA sia ancora giovane, è giunto il momento di portare alla ribalta queste sfide in modo che le persone possano evolvere collettivamente le soluzioni.
Le soluzioni possono essere sia a livello macro, sotto forma di regolamenti, politiche e approcci di formazione all'apprendimento automatico, sia a livello micro, sotto forma di progetti locali e di base.
Insieme, ricercatori, attivisti e comunità locali possono trovare metodi per garantire che l'IA vada a beneficio di tutti.



