

I ricercatori hanno presentato FANToM, un nuovo benchmark progettato per testare e valutare rigorosamente la comprensione e l'applicazione della Teoria della Mente (ToM) da parte dei modelli linguistici di grandi dimensioni (LLM).
La teoria della mente si riferisce alla capacità di attribuire credenze, desideri e conoscenze a se stessi e agli altri e di comprendere che gli altri hanno credenze e prospettive diverse dalle proprie.
La ToM è considerata fondamentale per la coscienza posseduta dagli animali intelligenti. Oltre agli esseri umani, si ritiene che i primati come gli oranghi, i gorilla e gli scimpanzé abbiano la ToM, così come alcuni non primati come i pappagalli e i membri della famiglia dei corvidi (corvi).
Man mano che i modelli di IA diventano più complessi, i ricercatori di IA cercano nuovi metodi per valutare abilità come la ToM.
Un nuovo benchmark chiamato FANToMcreato dai ricercatori dell'Allen Institute for AI, dell'Università di Washington, della Carnegie Mellon University e della Seoul National University, sottopone i modelli di apprendimento automatico a scenari dinamici che riflettono le interazioni della vita reale.
Con FANToM, i personaggi entrano ed escono dalle conversazioni, sfidando i modelli di intelligenza artificiale a mantenere una comprensione accurata di chi sa cosa in ogni momento.
Sottoponendo i modelli linguistici di grandi dimensioni (LLM) a FANToM è emerso che anche i modelli più avanzati hanno difficoltà a mantenere una ToM coerente.
Le prestazioni dei modelli sono state significativamente inferiori a quelle dei partecipanti umani, evidenziando i limiti dell'intelligenza artificiale nella comprensione e nella navigazione di interazioni sociali complesse.
In effetti, gli esseri umani hanno dominato tutte le categorie, come si può vedere di seguito.
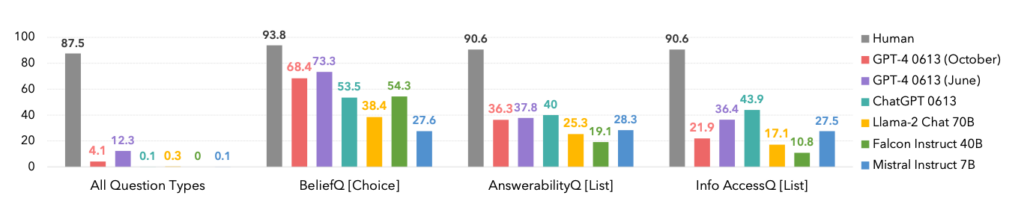
Un aspetto interessante è che la versione di ottobre dell'iterazione del modello GPT-4 è stata superata da una precedente versione di giugno, il che potrebbe avvalorare i recenti aneddoti degli utenti secondo cui ChatGPT sta peggiorando.
FANToM ha anche rivelato tecniche per migliorare la ToM di LLM, come il ragionamento a catena e altri metodi di messa a punto.
Tuttavia, il divario tra le competenze dell'IA e quelle umane in materia di ToM rimane elevato.
L'intelligenza artificiale si avvicina a capacità linguistiche simili a quelle umane
In un caso in qualche modo correlato ma separato studio pubblicato su NatureGli scienziati hanno sviluppato una rete neurale in grado di generalizzare il linguaggio in modo simile a quello umano.
Questa nuova rete neurale ha dimostrato un'impressionante capacità di integrare le parole appena apprese nel suo vocabolario esistente. In questo modo è in grado di utilizzare tali parole in vari contesti, un'abilità cognitiva nota come generalizzazione sistematica.
Gli esseri umani mostrano naturalmente una generalizzazione sistematica, incorporando senza problemi un nuovo vocabolario nel loro repertorio.
Per esempio, una volta imparato il termine "photobomb", si può applicarlo in varie situazioni quasi immediatamente. Il nuovo gergo spunta continuamente e gli esseri umani lo assorbono naturalmente nel loro vocabolario.
I ricercatori hanno sottoposto a una serie di test sia la loro rete neurale personalizzata che ChatGPT, scoprendo che ChatGPT è rimasto indietro rispetto al modello personalizzato.
Mentre i LLM come ChatGPT eccellono in molti scenari conversazionali, in altri presentano incongruenze e lacune evidenti, un problema che questa nuova rete neurale affronta.
Per indagare questo aspetto della comunicazione linguistica, i ricercatori hanno condotto un esperimento con 25 partecipanti umani, valutando la loro capacità di applicare parole appena apprese in contesti diversi. I soggetti sono stati introdotti a uno pseudolinguaggio composto da parole senza senso che rappresentano varie azioni e regole.
Dopo una fase di addestramento, i partecipanti si sono distinti nell'applicare queste regole astratte a nuove situazioni, dimostrando una generalizzazione sistematica.
Quando la rete neurale appena sviluppata è stata esposta a questo compito, ha rispecchiato le prestazioni umane. Tuttavia, quando ChatGPT è stato sottoposto alla stessa sfida, ha incontrato notevoli difficoltà, fallendo tra il 42 e l'86% del tempo, a seconda del compito specifico.
Questo dato è significativo per due motivi. In primo luogo, si può sostenere che questa nuova rete neurale abbia effettivamente superato il GPT-4 in questo compito specifico, il che è già abbastanza impressionante. In secondo luogo, questo studio espone nuovi metodi per insegnare ai modelli AI a generalizzare un nuovo linguaggio come gli esseri umani.
Come descrive Elia Bruni, specialista in elaborazione del linguaggio naturale presso l'Università di Osnabrück, in Germania, "Infondere sistematicità nelle reti neurali è un'impresa non da poco".
Insieme, questi due studi offrono nuovi approcci all'addestramento di modelli di intelligenza artificiale più intelligenti, in grado di competere con gli esseri umani in aree critiche come la linguistica e la teoria della mente.



