

OpenAI n'a pas présenté de nouveaux modèles lors de son événement Dev Day, mais les nouvelles fonctionnalités de l'API intéresseront les développeurs qui souhaitent utiliser leurs modèles pour créer des applications puissantes.
OpenAI a connu quelques semaines difficiles : son directeur technique, Mira Murati, et d'autres chercheurs en chef ont rejoint la liste des anciens employés, qui ne cesse de s'allonger. L'entreprise est soumise à une pression croissante de la part d'autres modèles phares, notamment les modèles à code source ouvert qui offrent aux développeurs des options moins chères et très performantes.
Les nouvelles fonctionnalités dévoilées par OpenAI sont l'API temps réel (en version bêta), l'optimisation de la vision et des outils d'amélioration de l'efficacité tels que la mise en cache des messages et la distillation des modèles.
API en temps réel
L'API en temps réel est la nouvelle fonctionnalité la plus intéressante, bien qu'elle soit en version bêta. Elle permet aux développeurs de créer des expériences de synthèse vocale à faible latence dans leurs applications sans utiliser de modèles distincts pour la reconnaissance vocale et la conversion du texte en synthèse vocale.
Grâce à cette API, les développeurs peuvent désormais créer des applications qui permettent des conversations en temps réel avec l'IA, comme les assistants vocaux ou les outils d'apprentissage des langues, le tout par le biais d'un seul appel à l'API. Ce n'est pas tout à fait l'expérience transparente qu'offre le mode vocal avancé de GPT-4o, mais cela s'en rapproche.
Il n'est cependant pas bon marché, avec environ $0,06 par minute d'entrée audio et $0,24 par minute de sortie audio.
La nouvelle API en temps réel de OpenAI est incroyable...
Regardez-le commander 400 fraises en appelant le magasin avec twillio. Le tout avec la voix. 🍓🎤 pic.twitter.com/J2BBoL9yFv
- Ty (@FieroTy) 1er octobre 2024
Affinage de la vision
Le réglage fin de la vision au sein de l'API permet aux développeurs d'améliorer la capacité de leurs modèles à comprendre et à interagir avec les images. En affinant GPT-4o à l'aide d'images, les développeurs peuvent créer des applications qui excellent dans des tâches telles que la recherche visuelle ou la détection d'objets.
Cette fonctionnalité est déjà exploitée par des entreprises comme Grab, qui a amélioré la précision de son service de cartographie en affinant le modèle de reconnaissance des panneaux de signalisation à partir d'images prises au niveau de la rue.
OpenAI a également donné un exemple de la manière dont GPT-4o pouvait générer du contenu supplémentaire pour un site web après avoir été ajusté pour correspondre stylistiquement au contenu existant du site.
Mise en cache de l'invite
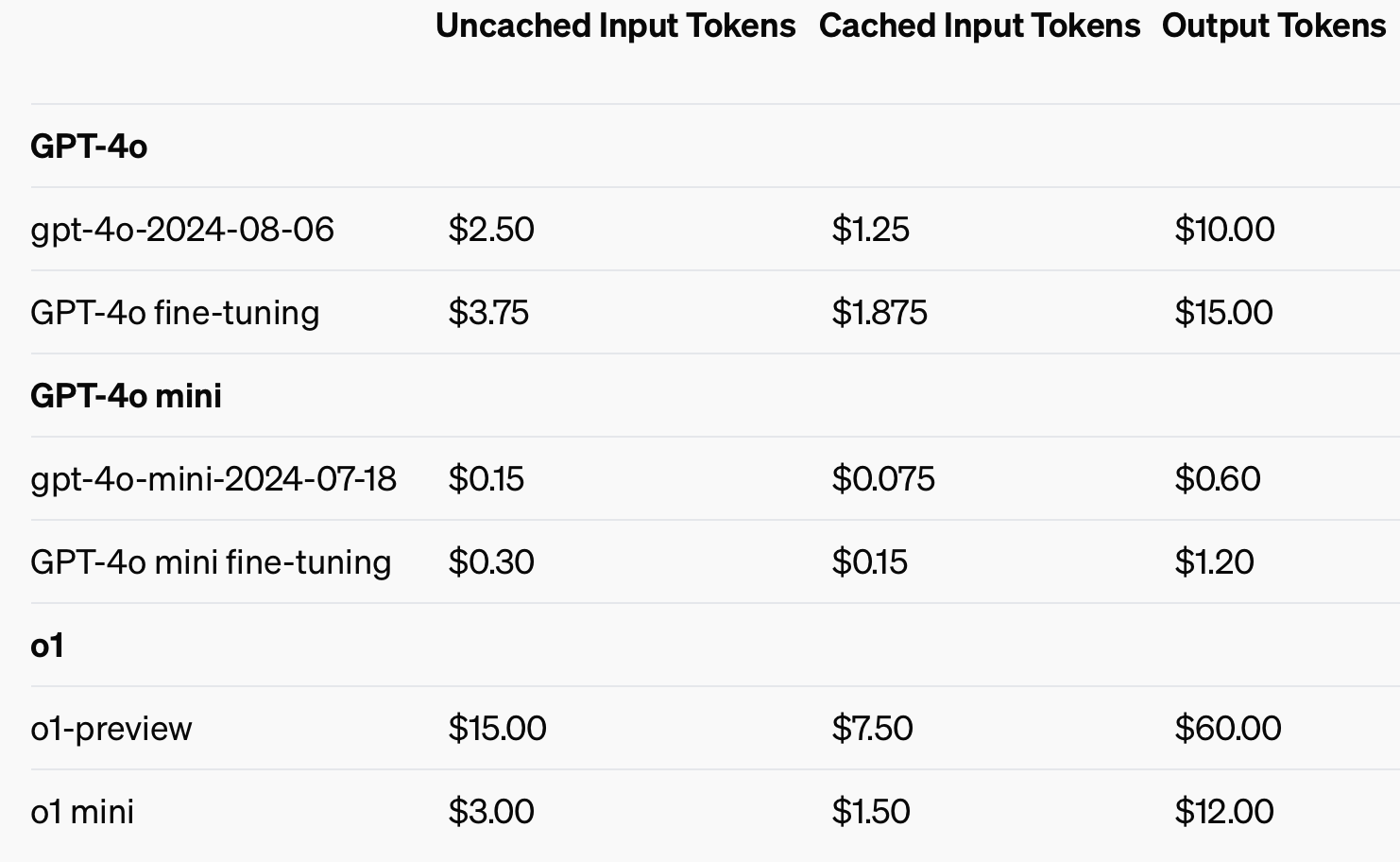
Afin d'améliorer la rentabilité, OpenAI a introduit la mise en cache rapide, un outil qui réduit le coût et la latence des appels d'API fréquemment utilisés. En réutilisant les données récemment traitées, les développeurs peuvent réduire les coûts de 50% et les temps de réponse. Cette fonctionnalité est particulièrement utile pour les applications nécessitant de longues conversations ou un contexte répété, comme les chatbots et les outils de service à la clientèle.
L'utilisation d'intrants mis en cache pourrait permettre d'économiser jusqu'à 50% sur les coûts des jetons d'intrants.
Distillation modèle
La distillation de modèles permet aux développeurs d'affiner des modèles plus petits et plus rentables, en utilisant les résultats de modèles plus grands et plus performants. Cela change la donne car, auparavant, la distillation nécessitait de multiples étapes et outils déconnectés, ce qui en faisait un processus long et sujet aux erreurs.
Avant la fonction intégrée de distillation de modèles d'OpenAI, les développeurs devaient orchestrer manuellement différentes parties du processus, comme la génération de données à partir de modèles plus vastes, la préparation d'ensembles de données de réglage fin et la mesure des performances à l'aide de divers outils.
Les développeurs peuvent désormais stocker automatiquement les paires de résultats provenant de modèles plus importants comme GPT-4o et utiliser ces paires pour affiner les modèles plus petits comme GPT-4o-mini. L'ensemble du processus de création d'ensembles de données, d'ajustement et d'évaluation peut être réalisé de manière plus structurée, automatisée et efficace.
La rationalisation du processus de développement, la réduction de la latence et des coûts feront du modèle GPT-4o d'OpenAI une perspective attrayante pour les développeurs qui cherchent à déployer rapidement des applications puissantes. Il sera intéressant de voir quelles applications les caractéristiques multimodales rendront possibles.



