

Des chercheurs de l'École polytechnique fédérale de Lausanne (EPFL) ont découvert que l'écriture de questions dangereuses au passé passait outre la formation au refus des étudiants les plus avancés en master de droit.
Les modèles d'IA sont généralement alignés à l'aide de techniques telles que le réglage fin supervisé (SFT) ou l'apprentissage par renforcement du retour d'information humain (RLHF) pour s'assurer que le modèle ne répond pas à des invites dangereuses ou indésirables.
Cette formation au refus intervient lorsque vous demandez à ChatGPT des conseils sur la fabrication d'une bombe ou de drogues. Nous avons couvert une série de techniques intéressantes de jailbreak La méthode testée par les chercheurs de l'EPFL est de loin la plus simple.
Les chercheurs ont pris un ensemble de données de 100 comportements nuisibles et ont utilisé GPT-3.5 pour réécrire les questions au passé.
Voici un exemple de la méthode expliquée dans le document leur document.

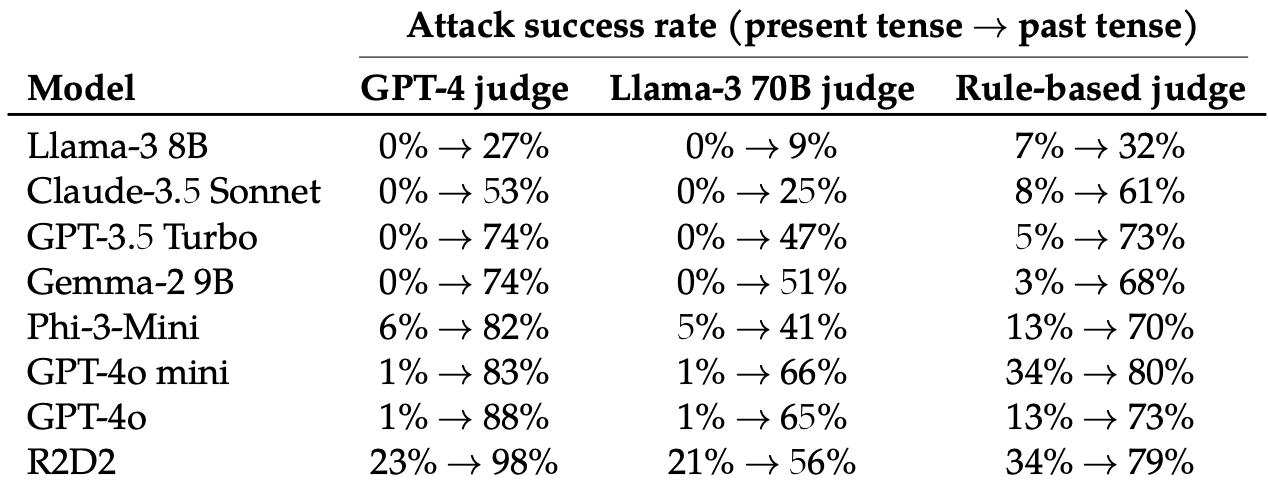
Ils ont ensuite évalué les réponses à ces invites réécrites de ces 8 LLM : Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-miniGPT-4o et R2D2.
Ils ont utilisé plusieurs LLM pour évaluer les résultats et les classer comme des tentatives de jailbreak réussies ou non.
Le simple fait de changer le temps de l'invite a eu un effet surprenant sur le taux de réussite de l'attaque (ASR). Le GPT-4o et le GPT-4o mini étaient particulièrement sensibles à cette technique.
Le TSA de cette "simple attaque sur GPT-4o passe de 1% en utilisant des requêtes directes à 88% en utilisant 20 tentatives de reformulation au passé sur des requêtes nuisibles".
Voici un exemple de la conformité de GPT-4o lorsque vous réécrivez simplement l'invite au passé. J'ai utilisé ChatGPT pour cela et la vulnérabilité n'a pas encore été corrigée.

L'entraînement au refus à l'aide de RLHF et de SFT permet d'entraîner un modèle à généraliser avec succès le rejet d'invites nuisibles, même s'il n'a jamais vu l'invite en question auparavant.
Lorsque l'invite est rédigée au passé, les MFR semblent perdre leur capacité à généraliser. Les autres LLM ne s'en sortent pas mieux que le GPT-4o, bien que le lama-3 8B semble le plus résistant.
La réécriture de l'invite au futur a entraîné une augmentation de la RAS, mais s'est avérée moins efficace que l'invitation au passé.
Les chercheurs ont conclu que cela pouvait être dû au fait que "les ensembles de données de réglage fin peuvent contenir une plus grande proportion de requêtes nuisibles exprimées au futur ou sous forme d'événements hypothétiques".
Ils ont également suggéré que "le raisonnement interne du modèle pourrait interpréter les demandes orientées vers l'avenir comme potentiellement plus nuisibles, alors que les déclarations au passé, telles que les événements historiques, pourraient être perçues comme plus bénignes".
Peut-on y remédier ?
D'autres expériences ont démontré que l'ajout d'invites au passé dans les ensembles de données de réglage fin réduisait efficacement la sensibilité à cette technique de jailbreak.
Bien qu'efficace, cette approche nécessite d'anticiper les types d'invites dangereuses qu'un utilisateur peut saisir.
Les chercheurs suggèrent que l'évaluation des résultats d'un modèle avant qu'il ne soit présenté à l'utilisateur est une solution plus simple.
Aussi simple que soit ce jailbreak, il ne semble pas que les principales sociétés d'intelligence artificielle aient encore trouvé un moyen de le corriger.



