

Genie de Google DeepMind est un modèle génératif qui traduit de simples images ou des invites textuelles en mondes dynamiques et interactifs.
Genie a été entraîné sur un vaste ensemble de données comprenant plus de 200 000 heures de séquences vidéo de jeux, y compris des jeux de plateformes en 2D et des interactions robotiques dans le monde réel.
Ce vaste ensemble de données a permis à Genie de comprendre et de générer la physique, la dynamique et l'esthétique de nombreux environnements et objets.
Le modèle finalisé, documenté dans un document de recherchecontient 11 milliards de paramètres permettant de générer des mondes virtuels interactifs à partir d'images de formats multiples ou d'invites textuelles.
Ainsi, vous pouvez envoyer à Genie une image de votre salon ou de votre jardin et la transformer en un niveau de plate-forme 2D jouable.
Ou encore griffonner un environnement 2D sur une feuille de papier et le convertir en un environnement de jeu jouable.
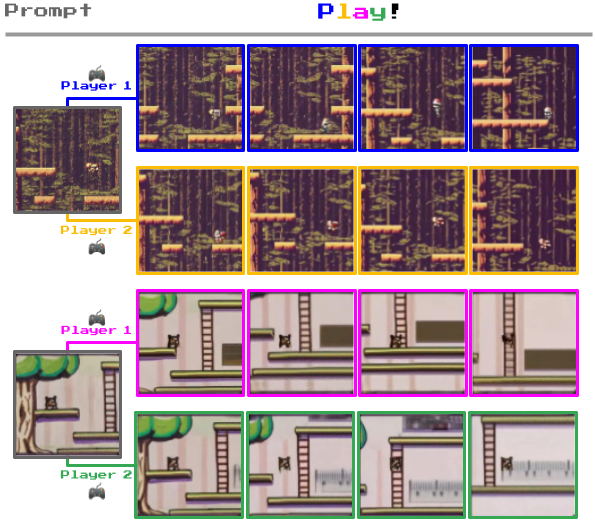
Ce qui distingue Genie des autres modèles de monde, c'est sa capacité à permettre aux utilisateurs d'interagir avec les environnements générés, image par image.
Par exemple, vous pouvez voir ci-dessous comment Genie prend des photos d'environnements réels et les transforme en niveaux de jeu en 2D.

Comment fonctionne Genie
Genie est un "modèle de monde de base" composé de trois éléments clés : un tokenizer vidéo spatio-temporel, un modèle dynamique autorégressif et un modèle d'action latente (LAM) simple et évolutif.
Voici comment cela fonctionne :
- Transformateurs spatio-temporels: Les transformateurs spatiotemporels (ST), qui traitent des séquences d'images vidéo, sont au cœur de Genie. Contrairement aux transformateurs traditionnels qui traitent du texte ou des images statiques, les transformateurs ST sont conçus pour comprendre la progression des données visuelles dans le temps, ce qui les rend idéaux pour la génération de vidéos et d'environnements dynamiques.
- Modèle d'action latente (LAM): Genie comprend et prédit les actions dans les mondes qu'il génère grâce au LAM. Il déduit les actions potentielles qui pourraient se produire entre les images d'une vidéo, en apprenant un ensemble d'"actions latentes" directement à partir des données visuelles. Cela permet à Genie de contrôler la progression des événements dans les environnements interactifs, malgré l'absence d'étiquettes d'action explicites dans les données d'apprentissage.
- Modèle d'encodage et de dynamique de la vidéo: Pour gérer les données vidéo, Genie fait appel à un système de codage vidéo qui compresse les images vidéo brutes dans un format plus facile à gérer de jetons discrets. Après la compression, le modèle dynamique prédit l'ensemble suivant de jetons d'images, générant ainsi les images suivantes dans l'environnement interactif.
L'équipe DeepMind explique que "Genie pourrait permettre à un grand nombre de personnes de générer leurs propres expériences de jeu. Cela pourrait être positif pour ceux qui souhaitent exprimer leur créativité d'une nouvelle manière, par exemple les enfants qui pourraient concevoir et pénétrer dans leurs propres mondes imaginaires".
Dans une expérience parallèle, lorsqu'on lui a présenté des vidéos de vrais bras de robots s'engageant dans des objets réels, Genie a fait preuve d'une capacité étonnante à déchiffrer les actions que ces bras pouvaient effectuer. Cela démontre les possibilités d'utilisation dans le domaine de la recherche en robotique.
Tim Rocktäschel, de l'équipe Genie, a décrit le potentiel illimité de Genie : "Il est difficile de prédire quels cas d'utilisation seront possibles. Nous espérons que des projets comme Genie offriront aux gens de nouveaux outils pour exprimer leur créativité".
DeepMind était conscient des risques liés à la publication de ce modèle de base et a déclaré dans l'article : "Nous avons choisi de ne pas publier les points de contrôle du modèle entraîné, l'ensemble de données d'entraînement du modèle ou des exemples tirés de ces données pour accompagner cet article ou le site web".
"Nous aimerions avoir l'occasion de nous engager plus avant avec la communauté de la recherche (et des jeux vidéo) et de veiller à ce que toute diffusion future de ce type soit respectueuse, sûre et responsable".
Utiliser des jeux pour simuler des applications du monde réel
DeepMind a utilisé des jeux vidéo pour plusieurs projets d'apprentissage automatique.
Par exemple, en 2021, DeepMind a construit XLandLe projet de recherche sur l'apprentissage par renforcement, un terrain de jeu virtuel permettant de tester les approches d'apprentissage par renforcement pour les agents d'intelligence artificielle généralistes, a été lancé. Ici, les modèles d'IA maîtrisent la coopération et la résolution de problèmes en effectuant des tâches telles que le déplacement d'obstacles dans des environnements de jeu ouverts.
Puis, le mois dernier, LMSI (Scalable, Instructable, Multiworld Agent) a été conçu pour comprendre et exécuter des instructions en langage humain dans différents jeux et scénarios.
SIMA a été formé à l'aide de neuf jeux vidéo nécessitant différentes compétences, de la navigation de base au pilotage de véhicules.
Les environnements de jeu offrent un bac à sable contrôlable et évolutif pour l'entraînement et le test des modèles d'IA.
L'expertise de DeepMind en matière de jeux remonte à 2014-2015, lorsqu'elle a mis au point un algorithme capable de vaincre les humains dans des jeux tels que Pong et Space Invaders, sans parler d'AlphaGo, qui a battu le joueur professionnel Fan Hui sur un plateau de 19×19 grandeur nature.



