

Microsoft a lancé Phi-3 Mini, un minuscule modèle de langage qui s'inscrit dans la stratégie de l'entreprise visant à développer des modèles d'IA légers et spécifiques à certaines fonctions.
La progression des modèles de langage s'est traduite par des paramètres, des ensembles de données d'apprentissage et des fenêtres contextuelles de plus en plus grands. L'augmentation de la taille de ces modèles a permis d'obtenir des capacités plus puissantes, mais à un certain coût.
L'approche traditionnelle de la formation d'un LLM consiste à lui faire consommer des quantités massives de données, ce qui nécessite d'énormes ressources informatiques. On estime que la formation d'un LLM tel que le GPT-4, par exemple, a pris environ 3 mois et a coûté plus de $21m.
Le GPT-4 est une excellente solution pour les tâches qui nécessitent un raisonnement complexe, mais il est excessif pour des tâches plus simples comme la création de contenu ou un chatbot de vente. C'est comme si vous utilisiez un couteau suisse alors que vous n'avez besoin que d'un simple coupe-papier.
Avec seulement 3,8 milliards de paramètres, la Phi-3 Mini est minuscule. Pourtant, Microsoft affirme qu'il s'agit d'une solution idéale, légère et peu coûteuse, pour des tâches telles que le résumé d'un document, l'extraction d'informations à partir de rapports et la rédaction de descriptions de produits ou de messages sur les réseaux sociaux.
Les chiffres du benchmark MMLU montrent que le Phi-3 Mini et les modèles Phi plus grands, qui n'ont pas encore été publiés, battent des modèles plus grands comme le Phi-3 Mini et le Phi-3 Mini. Mistral 7B et Gemma 7B.
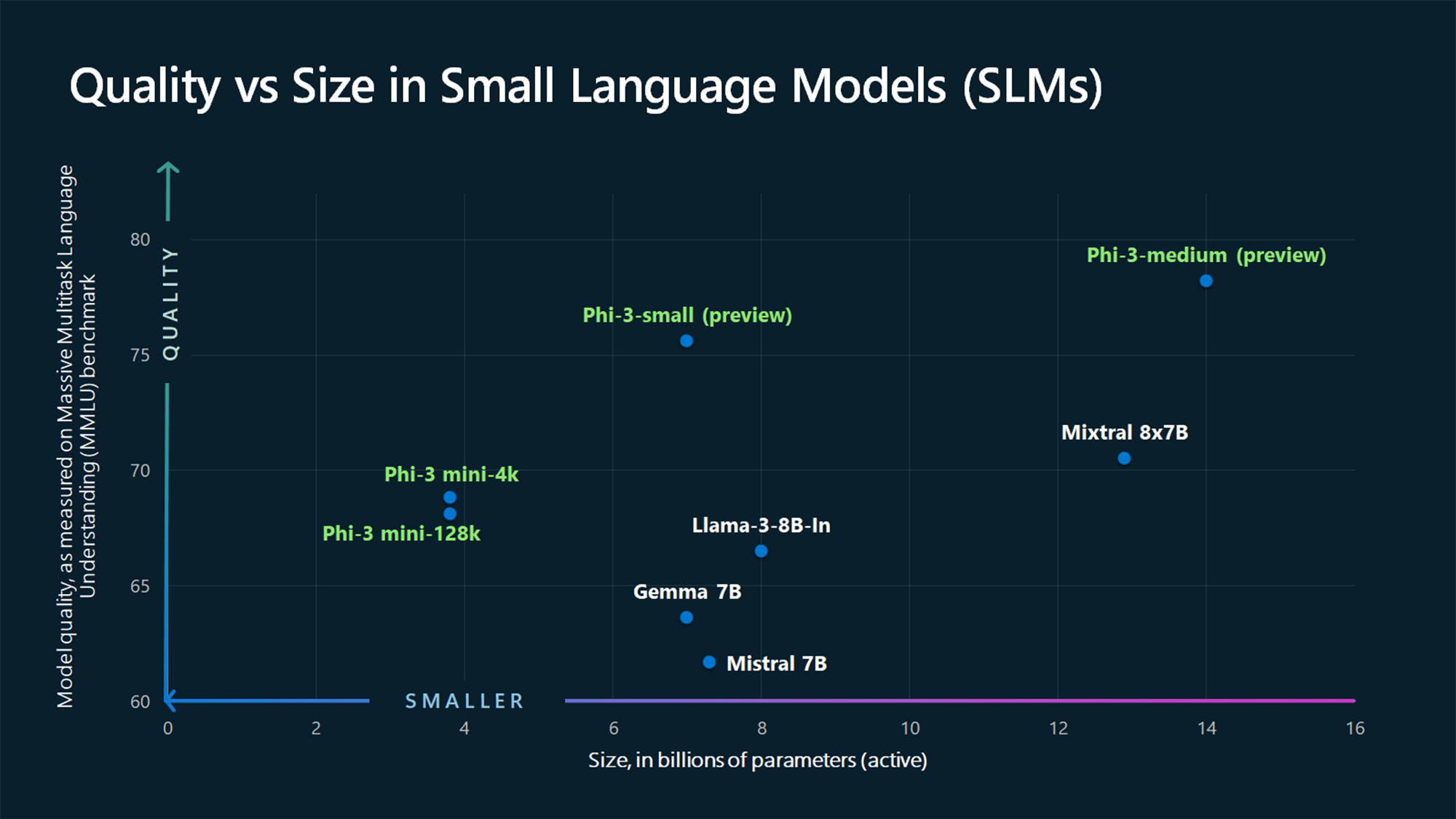
Microsoft indique que Phi-3-small (7B paramètres) et Phi-3-medium (14B paramètres) seront disponibles dans le Azure AI Model Catalog "prochainement".
Les grands modèles comme le GPT-4 restent la référence et nous pouvons probablement nous attendre à ce que le GPT-5 soit encore plus grand.
Les SLM comme le Phi-3 Mini offrent des avantages importants que les modèles plus grands n'ont pas. Les SLM sont moins chers à ajuster, nécessitent moins de calculs et peuvent fonctionner sur l'appareil même dans les situations où aucun accès à l'internet n'est disponible.
Le déploiement d'un SLM à la périphérie permet de réduire la latence et de maximiser la confidentialité, car il n'est pas nécessaire d'envoyer les données dans les deux sens vers le nuage.
Voici Sebastien Bubeck, vice-président de la recherche GenAI chez Microsoft AI, avec une démonstration du Phi-3 Mini. Il est super rapide et impressionnant pour un si petit modèle.
phi-3 est là, et il est ... bon :-).
J'ai fait une petite démo rapide pour vous donner une idée de ce que phi-3-mini (3.8B) peut faire. Restez à l'écoute pour la publication des poids libres et d'autres annonces demain matin !
(Et bien sûr, cet article ne serait pas complet sans le tableau habituel des points de repère !) pic.twitter.com/AWA7Km59rp
- Sébastien Bubeck (@SebastienBubeck) 23 avril 2024
Données synthétiques sélectionnées
Phi-3 Mini est le résultat de l'abandon de l'idée que d'énormes quantités de données sont le seul moyen de former un modèle.
Sébastien Bubeck, vice-président de Microsoft chargé de la recherche sur l'IA générative, a posé la question suivante : "Au lieu de s'entraîner sur des données web brutes, pourquoi ne pas rechercher des données d'une qualité extrêmement élevée ?"
Ronen Eldan, expert en apprentissage automatique de Microsoft Research, lisait des histoires à sa fille lorsqu'il s'est demandé si un modèle de langage pouvait apprendre en utilisant uniquement des mots qu'un enfant de 4 ans peut comprendre.
Cela a conduit à une expérience où ils ont créé un ensemble de données commençant par 3 000 mots. En utilisant uniquement ce vocabulaire limité, ils ont incité un LLM à créer des millions de petites histoires pour enfants qui ont été compilées dans un ensemble de données appelé TinyStories.
Les chercheurs ont ensuite utilisé TinyStories pour entraîner un modèle extrêmement petit de 10 millions de paramètres, qui a ensuite été capable de générer des "récits fluides avec une grammaire parfaite".
Ils ont continué à itérer et à développer cette approche de génération de données synthétiques pour créer des ensembles de données synthétiques plus avancés, mais soigneusement conservés et filtrés, qui ont finalement été utilisés pour entraîner Phi-3 Mini.
Le résultat est un petit modèle qui sera plus abordable à utiliser tout en offrant des performances comparables à celles du GPT-3.5.
Des modèles plus petits mais plus performants permettront aux entreprises de s'éloigner des grands LLM tels que GPT-4. Nous pourrions aussi bientôt voir des solutions où un LLM s'occupe des tâches lourdes mais délègue les tâches plus simples à des modèles plus légers.



