

Malgré les progrès rapides des LLM, notre compréhension de la manière dont ces modèles gèrent des entrées plus longues reste faible.
Mosh Levy, Alon Jacoby et Yoav Goldberg, de l'université Bar-Ilan et de l'Allen Institute for AI, ont étudié la manière dont les performances des grands modèles de langage (LLM) varient en fonction de la longueur du texte d'entrée qu'ils doivent traiter.
Ils ont développé un cadre de raisonnement spécialement à cette fin, ce qui leur a permis de disséquer l'influence de la longueur de l'entrée sur le raisonnement LLM dans un environnement contrôlé.
Le cadre de questionnement proposait différentes versions de la même question, chacune contenant les informations nécessaires pour répondre à la question, complétées par un texte supplémentaire non pertinent de longueur et de type variables.
Cela permet d'isoler la longueur de l'entrée en tant que variable, garantissant que les changements dans la performance du modèle peuvent être attribués directement à la longueur de l'entrée.
Principales conclusions
Levy, Jacoby et Goldberg ont découvert que les LLM présentent une baisse notable des performances de raisonnement à des longueurs d'entrée bien inférieures à ce que les développeurs affirment qu'ils peuvent gérer. Ils ont documenté leurs résultats dans cette étude.
Le déclin a été observé de manière cohérente dans toutes les versions de l'ensemble de données, ce qui indique un problème systémique lié au traitement d'entrées plus longues plutôt qu'un problème lié à des échantillons de données ou à des architectures de modèles spécifiques.
Comme le décrivent les chercheurs, "nos résultats montrent une dégradation notable des performances de raisonnement des LLM à des longueurs d'entrée beaucoup plus courtes que leur maximum technique. Nous montrons que la tendance à la dégradation apparaît dans chaque version de notre ensemble de données, bien qu'à des intensités différentes".

En outre, l'étude met en évidence la façon dont les mesures traditionnelles telles que la perplexité, couramment utilisées pour évaluer les LLM, ne sont pas en corrélation avec la performance des modèles sur les tâches de raisonnement impliquant de longues entrées.
Un examen plus approfondi a permis de constater que la dégradation des performances ne dépendait pas uniquement de la présence d'informations non pertinentes (remplissage), mais qu'elle était observée même lorsque le remplissage consistait en une duplication d'informations pertinentes.
Lorsque nous conservons les deux travées principales ensemble et que nous ajoutons du texte autour d'elles, la précision diminue déjà. En introduisant des paragraphes entre les travées, les résultats chutent encore plus. La baisse se produit à la fois lorsque les textes que nous ajoutons sont similaires aux textes de la tâche et lorsqu'ils sont complètement différents. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26 février 2024
Cela suggère que le défi pour les LLM réside dans le filtrage du bruit et le traitement inhérent des séquences de texte plus longues.
Ignorer les instructions
Un domaine critique du mode de défaillance mis en évidence dans l'étude est la tendance des LLM à ignorer les instructions intégrées dans l'entrée à mesure que la longueur de l'entrée augmente.
Les modèles génèrent également parfois des réponses indiquant une incertitude ou un manque d'informations suffisantes, telles que "Il n'y a pas assez d'informations dans le texte", en dépit de toutes les informations nécessaires.
Dans l'ensemble, les LLM semblent avoir du mal à hiérarchiser et à se concentrer sur les éléments d'information clés, y compris les instructions directes, au fur et à mesure que la longueur des données augmente.
Réponses biaisées
Un autre problème notable a été l'augmentation des biais dans les réponses des modèles à mesure que les entrées devenaient plus longues.
Plus précisément, les LLM avaient tendance à répondre "Faux" à mesure que la longueur de l'entrée augmentait. Ce biais indique une distorsion dans l'estimation des probabilités ou les processus de prise de décision au sein du modèle, peut-être comme un mécanisme défensif en réponse à l'incertitude accrue due à des entrées plus longues.
La tendance à favoriser les réponses "Faux" pourrait également refléter un déséquilibre sous-jacent dans les données d'apprentissage ou un artefact du processus d'apprentissage des modèles, où les réponses négatives peuvent être surreprésentées ou associées à des contextes d'incertitude et d'ambiguïté.
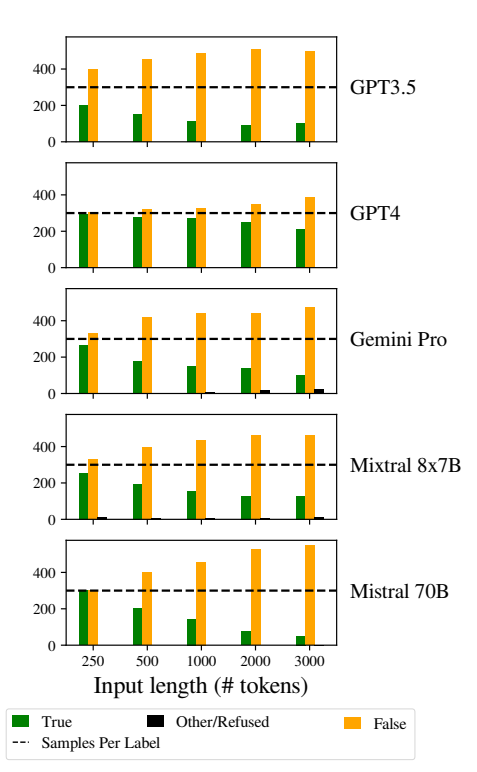
Ce biais affecte la précision des résultats des modèles et soulève des inquiétudes quant à la fiabilité et à l'équité des LLM dans des applications nécessitant une compréhension nuancée et de l'impartialité.
La mise en œuvre de stratégies robustes de détection et d'atténuation des biais au cours des phases de formation et d'ajustement des modèles est essentielle pour réduire les biais injustifiés dans les réponses des modèles.
Ee fait de s'assurer que les ensembles de données d'entraînement sont diversifiés, équilibrés et représentatifs d'un large éventail de scénarios peut également contribuer à minimiser les biais et à améliorer la généralisation des modèles.
Cela contribue à autres études récentes qui, de la même manière, mettent en évidence des problèmes fondamentaux dans le fonctionnement des LLM, conduisant ainsi à une situation où cette "dette technique" pourrait menacer la fonctionnalité et l'intégrité du modèle au fil du temps.



