

Une nouvelle étude montre que l'entraînement des générateurs d'images par l'IA avec des images générées par l'IA conduit finalement à une réduction significative de la qualité des résultats.
Baraniuk et son équipe ont démontré comment cette boucle d'entraînement problématique affecte les IA génératives, notamment les modèles StyleGAN et de diffusion. Ces derniers font partie des modèles utilisés pour les générateurs d'images d'IA tels que Stable Diffusion, DALL-E et MidJourney.
Dans leur expérienceL'équipe a entraîné les IA sur des images générées par l'IA ou sur des images réelles. 70 000 visages humains réels provenant de Flickr.
Lorsque chaque IA a été entraînée sur ses propres images, les sorties du générateur d'images StyleGAN ont commencé à afficher des motifs visuels déformés et ondulés, tandis que les sorties du générateur d'images de diffusion sont devenues plus floues.
Dans les deux cas, la formation d'IA sur des images générées par l'IA a entraîné une perte de qualité.
L'un des étude Richard Baraniuk, de l'université Rice au Texas, met en garde les auteurs de l'étude : "L'utilisation de données synthétiques, volontairement ou involontairement, va devenir une pente glissante."
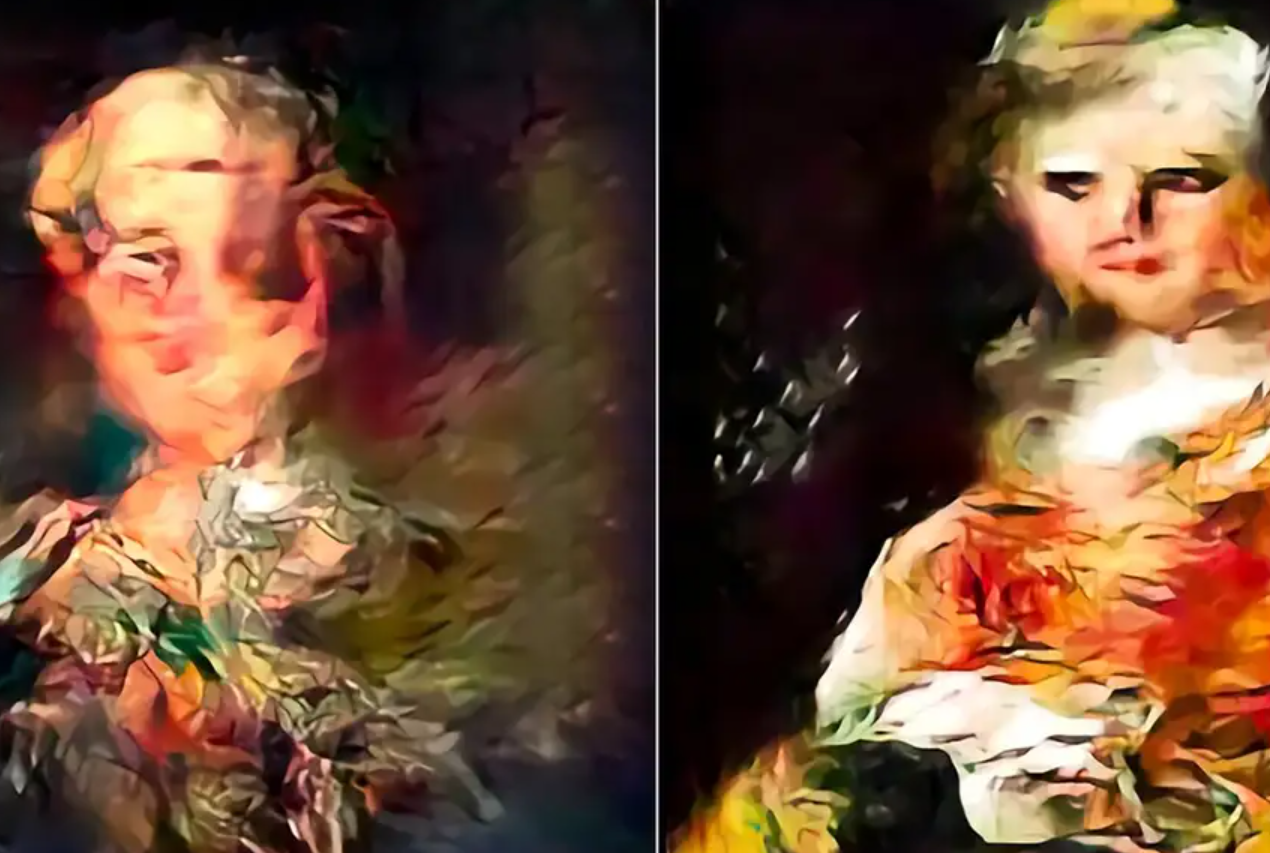
Bien que la baisse de la qualité des images ait été atténuée par la sélection d'images de meilleure qualité générées par l'IA pour l'entraînement, cela a entraîné une perte de diversité des images.
Les chercheurs ont également essayé d'incorporer un ensemble fixe d'images réelles dans des ensembles d'entraînement comprenant principalement des images générées par l'IA, une méthode parfois utilisée pour compléter de petits ensembles d'entraînement.
Cependant, cela n'a fait que retarder le déclin de la qualité des images - il semble inévitable que plus les données générées par l'IA entrent dans les ensembles de données d'entraînement, plus le résultat devient mauvais. Il s'agit simplement de savoir quand.
Des résultats raisonnables ont été obtenus lorsque chaque IA a été entraînée sur un mélange d'images générées par l'IA et d'un ensemble d'images authentiques en constante évolution. Cela a permis de maintenir la qualité et la diversité des images.
Il est difficile de trouver un équilibre entre quantité et qualité - les images synthétiques sont potentiellement illimitées par rapport aux images réelles, mais leur utilisation a un coût.
Les IA sont à court de données
Les IA sont avides de données, mais les données authentiques et de qualité sont une ressource limitée.
Les résultats de cette recherche font écho études similaires pour la génération de textesoù les résultats de l'IA ont tendance à souffrir lorsque les modèles sont formés sur du texte généré par l'IA.
Les chercheurs soulignent que les petites organisations ayant une capacité limitée à collecter des données authentiques sont confrontées aux plus grandes difficultés pour filtrer les images générées par l'IA de leurs ensembles de données.
En outre, le problème est aggravé par le fait que l'internet est inondé de contenus générés par l'IA, ce qui rend extrêmement difficile la détermination du type de données sur lesquelles les modèles sont formés.
Sina Alemohammad, de l'université de Rice, suggère que le développement de filigranes permettant d'identifier les images générées par l'IA pourrait être utile, mais prévient que le fait de ne pas tenir compte des filigranes cachés peut dégrader la qualité des images générées par l'IA.
Alemohammad conclut : "Vous êtes condamné si vous le faites et condamné si vous ne le faites pas. Mais il vaut mieux filigraner l'image que de ne pas le faire".
Les conséquences à long terme de la consommation des résultats de l'IA font l'objet de vifs débats, mais pour l'heure, les développeurs d'IA doivent trouver des solutions pour garantir la qualité de leurs modèles.



