

Los investigadores de Google DeepMind desarrollaron NATURAL PLAN, una prueba de referencia para evaluar la capacidad de los LLM de planificar tareas del mundo real basándose en instrucciones de lenguaje natural.
La próxima evolución de la IA es hacer que abandone los confines de una plataforma de chat y asuma funciones de agente para completar tareas a través de plataformas en nuestro nombre. Pero eso es más difícil de lo que parece.
Las tareas de planificación, como programar una reunión o elaborar un itinerario de vacaciones, pueden parecernos sencillas. Los humanos somos buenos razonando a través de múltiples pasos y prediciendo si un curso de acción logrará el objetivo deseado o no.
Puede que te parezca fácil, pero incluso los mejores modelos de IA tienen problemas con la planificación. Podríamos compararlos para ver qué LLM es mejor planificando?
La evaluación comparativa NATURAL PLAN pone a prueba los LLM en 3 tareas de planificación:
- Planificación del viaje - Planificación de un itinerario de viaje con restricciones de vuelo y destino
- Planificación de reuniones - Programar reuniones con varios amigos en distintos lugares
- Programación del calendario - Programar reuniones de trabajo entre varias personas en función de los calendarios existentes y de diversas limitaciones.
El experimento comenzó con una serie de instrucciones en las que los modelos recibían 5 ejemplos de instrucciones con sus correspondientes respuestas correctas. A continuación, se les pedía que planificaran tareas de dificultad variable.
He aquí un ejemplo de pregunta y solución facilitado como ejemplo a los modelos:

Resultados
Los investigadores probaron GPT-3.5, GPT-4, GPT-4oGemini 1.5 Flash, y Gemini 1,5 Proninguno de los cuales obtuvo muy buenos resultados en estas pruebas.
Sin embargo, los resultados deben de haber sentado muy bien en la oficina de DeepMind, ya que Gemini 1.5 Pro se alzó con la victoria.

Como era de esperar, los resultados empeoran exponencialmente con preguntas más complejas en las que aumenta el número de personas o ciudades. Por ejemplo, fíjate en lo rápido que empeoraba la precisión a medida que se añadían más personas a la prueba de planificación de reuniones.
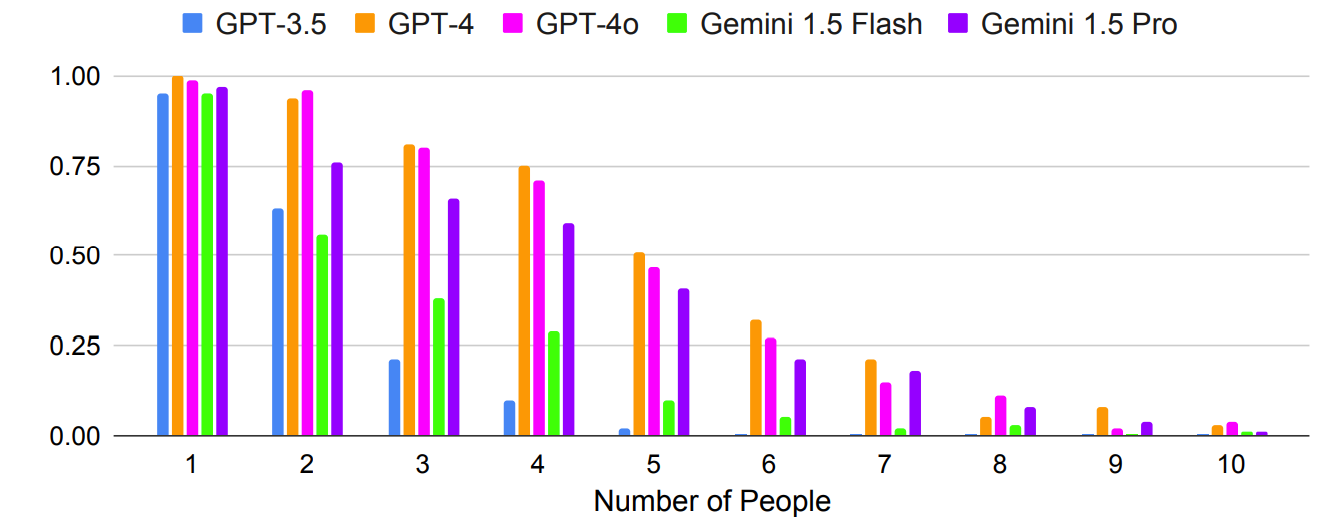
¿Podría mejorar la precisión si se realizaran varios disparos? Los resultados de la investigación indican que sí, pero sólo si el modelo dispone de una ventana de contexto lo suficientemente amplia.
La mayor ventana contextual de Gemini 1.5 Pro le permite aprovechar más ejemplos en contexto que los modelos GPT.
Los investigadores descubrieron que, en Planificación de viajes, aumentar el número de disparos de 1 a 800 mejora la precisión de Gemini Pro 1.5 de 2,7% a 39,9%.
El periódico señaló: "Estos resultados muestran lo prometedor de la planificación en contexto, donde las capacidades de contexto largo permiten a los LLM aprovechar más el contexto para mejorar la planificación".
Un resultado extraño fue que GPT-4o era realmente malo en la planificación de viajes. Los investigadores descubrieron que le costaba "entender y respetar las restricciones de conectividad de vuelos y fechas de viaje."
Otro resultado extraño fue que la autocorrección provocó un descenso significativo del rendimiento en todos los modelos. Cuando se pedía a los modelos que revisaran su trabajo y lo corrigieran, cometían más errores.
Curiosamente, los modelos más potentes, como GPT-4 y Gemini 1.5 Pro, sufrieron mayores pérdidas que GPT-3.5 al autocorregirse.
La IA agenética es una perspectiva apasionante y ya estamos viendo algunos casos prácticos de uso en Microsoft Copilot agentes.
Pero los resultados de las pruebas comparativas de NATURAL PLAN muestran que aún queda camino por recorrer antes de que la IA pueda gestionar una planificación más compleja.
Los investigadores de DeepMind concluyeron que "PLAN NATURAL es muy difícil de resolver para los modelos más avanzados."
Parece que la IA aún no sustituirá a las agencias de viajes ni a los asistentes personales.



