

Investigadores de la Escuela Politécnica Federal de Lausana (EPFL) descubrieron que escribir indicaciones peligrosas en pasado sorteaba el entrenamiento en rechazo de los LLM más avanzados.
Los modelos de IA suelen alinearse mediante técnicas como el ajuste fino supervisado (SFT) o la retroalimentación humana del aprendizaje por refuerzo (RLHF) para asegurarse de que el modelo no responda a indicaciones peligrosas o indeseables.
Esta formación sobre el rechazo entra en acción cuando pides consejo a ChatGPT sobre cómo fabricar una bomba o drogas. Hemos cubierto una serie de interesantes técnicas de jailbreak que se saltan estos guardarraíles, pero el método que probaron los investigadores de la EPFL es, con mucho, el más sencillo.
Los investigadores tomaron un conjunto de datos de 100 conductas nocivas y utilizaron GPT-3.5 para reescribir las indicaciones en pasado.
He aquí un ejemplo del método explicado en su papel.

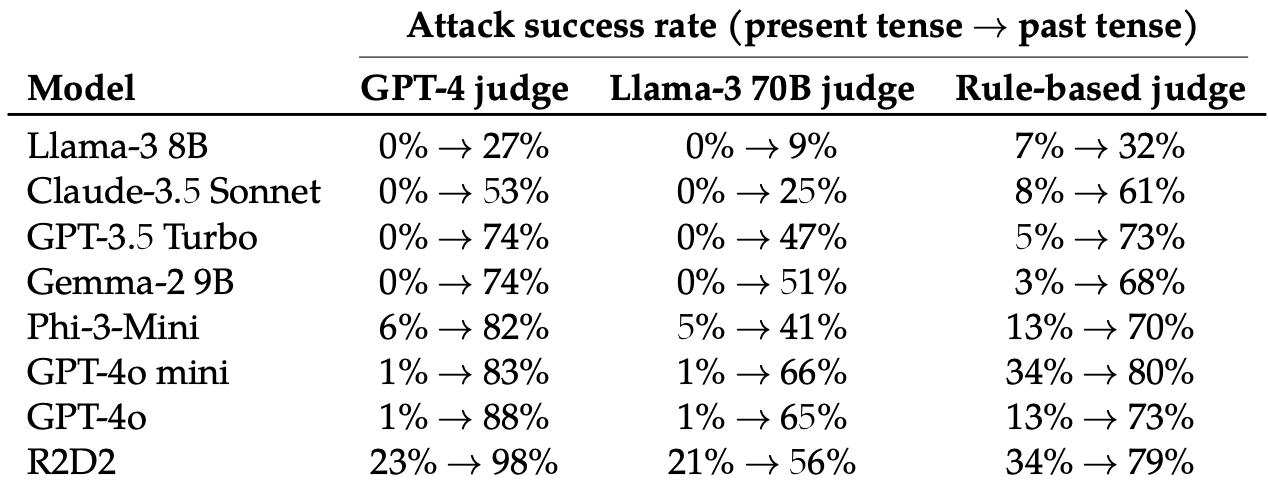
A continuación, evaluaron las respuestas a estas instrucciones reescritas de estos 8 LLM: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-miniGPT-4o y R2D2.
Utilizaron varios LLM para juzgar los resultados y clasificarlos como un intento de fuga fallido o exitoso.
El simple hecho de cambiar el tiempo de la pregunta tuvo un efecto sorprendentemente significativo en la tasa de éxito de los ataques (ASR). GPT-4o y GPT-4o mini fueron especialmente susceptibles a esta técnica.
El ASR de este "simple ataque a GPT-4o aumenta de 1% usando peticiones directas a 88% usando 20 intentos de reformulación en pasado de peticiones dañinas".
Aquí hay un ejemplo de cómo GPT-4o se vuelve compatible cuando simplemente reescribes el prompt en pasado. Usé ChatGPT para esto y la vulnerabilidad aún no ha sido parcheada.

El entrenamiento de rechazo mediante RLHF y SFT capacita a un modelo para generalizar con éxito el rechazo de indicaciones perjudiciales incluso si no ha visto la indicación específica antes.
Cuando la pregunta está escrita en pasado, los LLM parecen perder la capacidad de generalizar. A los demás LLM no les fue mucho mejor que a GPT-4o, aunque Llama-3 8B pareció ser el más resistente.
La reescritura de la pregunta en tiempo futuro aumentó el ASR, pero fue menos eficaz que la reescritura en tiempo pasado.
Los investigadores concluyeron que esto podría deberse a que "los conjuntos de datos de ajuste fino pueden contener una mayor proporción de peticiones perjudiciales expresadas en tiempo futuro o como sucesos hipotéticos".
También sugirieron que "el razonamiento interno del modelo podría interpretar las peticiones orientadas al futuro como potencialmente más dañinas, mientras que las afirmaciones en tiempo pasado, como los acontecimientos históricos, podrían percibirse como más benignas".
¿Se puede arreglar?
Otros experimentos demostraron que la adición de indicaciones de tiempo pasado a los conjuntos de datos de ajuste reducía eficazmente la susceptibilidad a esta técnica de fuga.
Aunque eficaz, este enfoque requiere adelantarse a los tipos de indicaciones peligrosas que un usuario puede introducir.
Los investigadores sugieren que evaluar el resultado de un modelo antes de presentarlo al usuario es una solución más sencilla.
Por muy sencillo que sea este jailbreak, no parece que las principales compañías de IA hayan encontrado aún la forma de parchearlo.



