

A medida que avanza la era de la IA generativa, un amplio abanico de empresas se ha sumado a la batalla, y los propios modelos son cada vez más diversos.
En medio de este auge de la IA, muchas empresas han promocionado sus modelos como de "código abierto", pero ¿qué significa esto realmente en la práctica?
El concepto de código abierto tiene sus raíces en la comunidad de desarrollo de software. El software tradicional de código abierto pone el código fuente a disposición de cualquiera que desee verlo, modificarlo y distribuirlo.
En esencia, el código abierto es un dispositivo de colaboración para compartir conocimientos alimentado por la innovación en software, que ha dado lugar a desarrollos como el sistema operativo Linux, el navegador web Firefox y el lenguaje de programación Python.
Sin embargo, aplicar la ética del código abierto a los actuales modelos masivos de IA no es nada sencillo.
Estos sistemas se entrenan a menudo en vastos conjuntos de datos que contienen terabytes o petabytes de datos, utilizando complejas arquitecturas de redes neuronales con miles de millones de parámetros.
Los recursos informáticos necesarios cuestan millones de dólares, el talento es escaso y la propiedad intelectual suele estar bien protegida.
Podemos observarlo en OpenAI, que, como sugiere su nombre, solía ser un laboratorio de investigación de IA dedicado en gran medida a la ética de la investigación abierta.
Sin embargo ethos erosionado rápidamente una vez que la empresa olió el dinero y necesitó atraer inversiones para alimentar sus objetivos.
¿Por qué? Porque los productos de código abierto no tienen ánimo de lucro, y la IA es cara y valiosa.
Sin embargo, con la explosión de la IA generativa, empresas como Mistral, Meta, BLOOM y xAI están publicando modelos de código abierto para fomentar la investigación y evitar al mismo tiempo que empresas como Microsoft y Google acaparen demasiada influencia.
Pero, ¿cuántos de estos modelos son realmente de código abierto, y no sólo por su nombre?
Aclarar hasta qué punto son realmente abiertos los modelos de código abierto
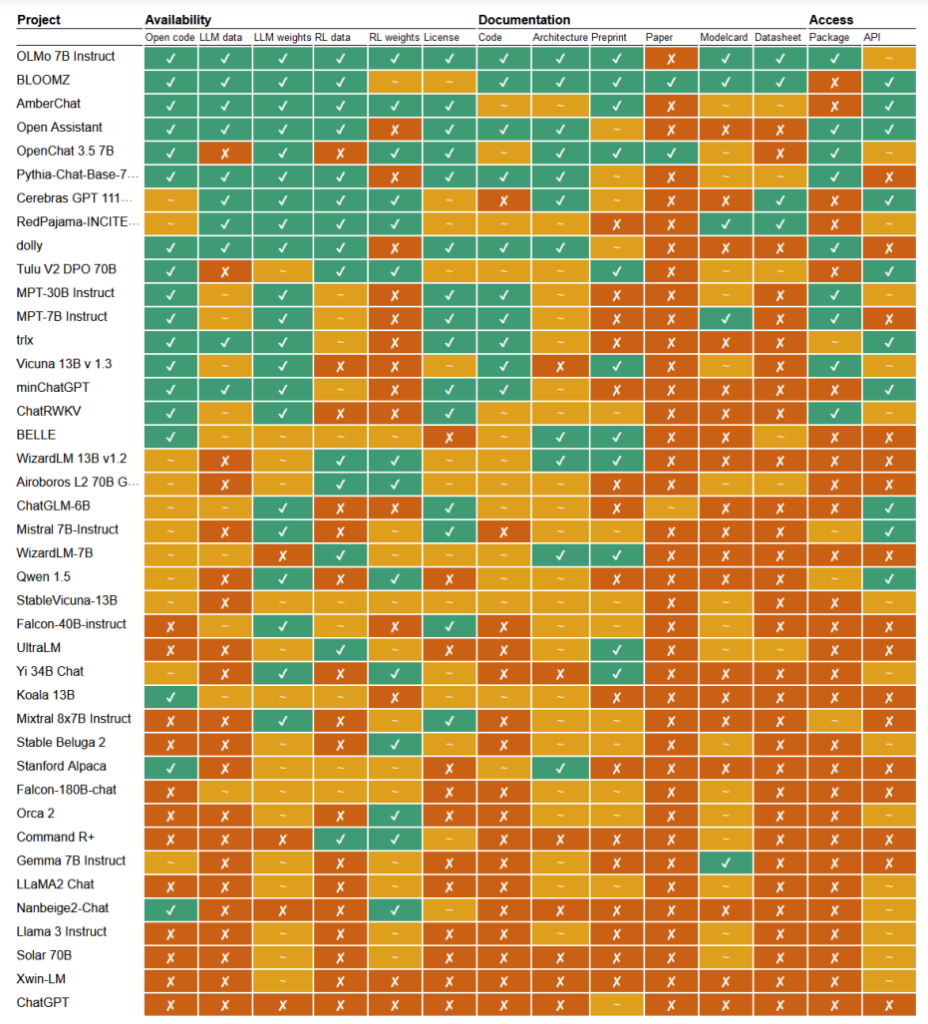
En un reciente estudiarLos investigadores Mark Dingemanse y Andreas Liesenfeld, de la Universidad de Radboud (Países Bajos), analizaron numerosos modelos de IA destacados para averiguar hasta qué punto son abiertos. Estudiaron múltiples criterios, como la disponibilidad del código fuente, los datos de entrenamiento, las ponderaciones de los modelos, los artículos de investigación y las API.
Por ejemplo, se descubrió que el modelo LLaMA de Meta y Gemma de Google eran simplemente "de peso abierto", lo que significa que el modelo entrenado se libera públicamente para su uso sin total transparencia sobre su código, proceso de entrenamiento, datos y métodos de ajuste.
En el otro extremo del espectro, los investigadores destacaron BLOOM, un gran modelo multilingüe desarrollado por una colaboración de más de 1.000 investigadores de todo el mundo, como ejemplo de verdadera IA de código abierto. Cada elemento del modelo es de libre acceso para su inspección y posterior investigación.
El documento evaluaba más de 30 modelos (tanto de texto como de imagen), pero éstos demuestran la inmensa variación existente dentro de los que dicen ser de código abierto:
- BloomZ (BigScience): Totalmente abierto en todos los criterios, incluido el código, los datos de entrenamiento, las ponderaciones del modelo, los trabajos de investigación y la API. Destacado como ejemplo de IA de código abierto.
- OLMo (Instituto Allen para la IA): Código abierto, datos de entrenamiento, pesos y trabajos de investigación. API sólo parcialmente abierta.
- Mistral 7B-Instruct (Mistral AI): Pesos del modelo y API abiertos. Código y documentos de investigación sólo parcialmente abiertos. Datos de entrenamiento no disponibles.
- Orca 2 (Microsoft): Pesos del modelo y documentos de investigación parcialmente abiertos. Código, datos de entrenamiento y API cerrados.
- Gemma 7B instructora (Google): Código y pesos parcialmente abiertos. Datos de entrenamiento, documentos de investigación y API cerrados. Descrito como "abierto" por Google en lugar de "código abierto".
- Llama 3 Instruct (Meta): Pesos parcialmente abiertos. Código, datos de entrenamiento, documentos de investigación y API cerrados. Un ejemplo de modelo de "pesos abiertos" sin mayor transparencia.
Falta de transparencia
La falta de transparencia en torno a los modelos de IA, especialmente los desarrollados por grandes empresas tecnológicas, suscita serias dudas sobre la responsabilidad y la supervisión.
Sin un acceso completo al código del modelo, a los datos de entrenamiento y a otros componentes clave, resulta extremadamente difícil comprender cómo funcionan estos modelos y tomar decisiones. Esto dificulta la identificación y el tratamiento de posibles sesgos, errores o usos indebidos de material protegido por derechos de autor.
La infracción de los derechos de autor en los datos de entrenamiento de la IA es un buen ejemplo de los problemas que surgen de esta falta de transparencia. Muchos modelos de IA patentados, como GPT-3.5/4/40/Claude 3/Gemini, se entrenan probablemente con material protegido por derechos de autor.
Sin embargo, dado que los datos de formación se guardan bajo llave, identificar datos específicos dentro de este material es casi imposible.
El New York Times demanda reciente contra OpenAI demuestra las consecuencias de este desafío en el mundo real. OpenAI acusó al NYT de utilizar ataques de ingeniería rápida para exponer los datos de entrenamiento y engatusar a ChatGPT para que reprodujera sus artículos textualmente, demostrando así que los datos de entrenamiento de OpenAI contienen material protegido por derechos de autor.
"El Times pagó a alguien para que pirateara los productos de OpenAI", declaró OpenAI.
En respuesta, Ian Crosby, el principal asesor jurídico del NYT, dijo: "Lo que OpenAI bizarramente caracteriza erróneamente como 'piratería' es simplemente utilizar los productos de OpenAI para buscar pruebas de que robaron y reprodujeron las obras protegidas por derechos de autor del Times. Y eso es exactamente lo que encontramos".
De hecho, ese es solo un ejemplo de la enorme pila de demandas que actualmente están bloqueadas en parte debido a la naturaleza opaca e impenetrable de los modelos de IA.
Esto es sólo la punta del iceberg. Sin medidas sólidas de transparencia y rendición de cuentas, nos arriesgamos a un futuro en el que sistemas de IA inexplicables tomen decisiones que afecten profundamente a nuestras vidas, economía y sociedad, pero que permanezcan ocultas al escrutinio.
Llamamientos a la apertura
Se ha pedido a empresas como Google y OpenAI que permitir el acceso al funcionamiento interno de sus modelos a efectos de evaluación de la seguridad.
Sin embargo, lo cierto es que ni siquiera las empresas de IA comprenden realmente cómo funcionan sus modelos.
Es lo que se denomina el problema de la "caja negra", que surge al intentar interpretar y explicar las decisiones específicas del modelo de forma comprensible para el ser humano.
Por ejemplo, un desarrollador puede saber que un modelo de aprendizaje profundo es preciso y funciona bien, pero puede tener dificultades para determinar exactamente qué características utiliza el modelo para tomar sus decisiones.
Anthropic, que desarrolló los modelos Claude, recientemente realizó un experimento para identificar cómo funciona Claude 3 Sonnet, explica: "La mayoría de las veces tratamos los modelos de IA como una caja negra: algo entra y sale una respuesta, y no está claro por qué el modelo dio esa respuesta concreta en lugar de otra. Por eso es difícil confiar en la seguridad de estos modelos: si no sabemos cómo funcionan, ¿cómo sabemos que no darán respuestas perjudiciales, sesgadas, falsas o peligrosas? ¿Cómo podemos confiar en que serán seguros y fiables?".
Es una admisión bastante notable, en realidad, que el creador de una tecnología no entienda su producto en la era de la IA.
Este experimento antrópico ilustra que explicar objetivamente los resultados es una tarea excepcionalmente complicada. De hecho, Anthropic calculó que consumiría más potencia informática "abrir la caja negra" que entrenar el propio modelo.
Los desarrolladores intentan combatir activamente el problema de la "caja negra" mediante investigaciones como la "IA explicable" (XAI), cuyo objetivo es desarrollar técnicas y herramientas para que los modelos de IA sean más transparentes e interpretables.
Los métodos de XAI pretenden proporcionar información sobre el proceso de toma de decisiones del modelo, destacar las características más influyentes y generar explicaciones legibles para el ser humano. La XAI ya se ha aplicado a modelos desplegados en proyectos de alto riesgo. aplicaciones como el desarrollo de fármacosLa comprensión del funcionamiento de un modelo puede ser fundamental para la seguridad.
Las iniciativas de código abierto son vitales para la XAI y otras investigaciones que pretenden penetrar en la caja negra y aportar transparencia a los modelos de IA.
Sin acceso al código del modelo, los datos de entrenamiento y otros componentes clave, los investigadores no pueden desarrollar y probar técnicas para explicar cómo funcionan realmente los sistemas de IA e identificar los datos específicos con los que se entrenaron.
La normativa podría confundir aún más la situación del código abierto
La Unión Europea recientemente aprobada está a punto de introducir una nueva normativa para los sistemas de IA, con disposiciones que abordan específicamente los modelos de código abierto.
Según la Ley, los modelos de uso general de código abierto hasta un determinado tamaño estarán exentos de amplios requisitos de transparencia.
Sin embargo, como señalan Dingemanse y Liesenfeld en su estudio, la definición exacta de "IA de código abierto" según la Ley de IA sigue sin estar clara y podría convertirse en un punto de controversia.
La Ley define actualmente los modelos de código abierto como aquellos que se publican bajo una licencia "libre y abierta" que permite a los usuarios modificar el modelo. Sin embargo, no especifica los requisitos de acceso a los datos de entrenamiento ni a otros componentes clave.
Esta ambigüedad deja margen para la interpretación y la posible presión de los intereses corporativos. Los investigadores advierten de que afinar la definición de código abierto en la Ley de IA "probablemente formará un único punto de presión que será objetivo de los lobbies corporativos y las grandes empresas."
Existe el riesgo de que, sin unos criterios claros y sólidos sobre lo que constituye una verdadera IA de código abierto, la normativa cree inadvertidamente lagunas o incentivos para que las empresas se dediquen al "lavado abierto", alegando apertura por las ventajas legales y de relaciones públicas pero manteniendo la propiedad de aspectos importantes de sus modelos.
Además, la naturaleza global del desarrollo de la IA implica que las diferentes normativas de las distintas jurisdicciones podrían complicar aún más el panorama.
Si los principales productores de IA, como Estados Unidos y China, adoptan enfoques divergentes en cuanto a los requisitos de apertura y transparencia, esto podría dar lugar a un ecosistema fragmentado en el que el grado de apertura varíe mucho en función de dónde se origine un modelo.
Los autores del estudio subrayan la necesidad de que los reguladores colaboren estrechamente con la comunidad científica y otras partes interesadas para garantizar que cualquier disposición de código abierto en la legislación sobre IA se base en un profundo conocimiento de la tecnología y los principios de apertura.
Como concluyen Dingemanse y Liesenfeld en un debate con la Naturaleza"Es justo decir que el término código abierto adquirirá un peso legal sin precedentes en los países regidos por la Ley de IA de la UE".
La forma en que esto se desarrolle en la práctica tendrá implicaciones trascendentales para la futura dirección de la investigación y el despliegue de la IA.



