

Anthropic investigadores identificaron con éxito millones de conceptos Claude Sonnet, uno de sus LLM avanzados.
Los modelos de IA suelen considerarse cajas negras, lo que significa que no se puede "ver" en su interior para entender exactamente cómo funcionan.
Cuando le das una entrada a un LLM, genera una respuesta, pero el razonamiento que hay detrás de sus elecciones no está claro.
Entras y sales, y ni siquiera los propios desarrolladores de IA entienden lo que ocurre dentro de esa "caja".
Las redes neuronales crean sus propias representaciones internas de la información cuando asignan entradas a salidas durante el entrenamiento de los datos. Los componentes básicos de este proceso, denominados "activaciones neuronales", se representan mediante valores numéricos.
Cada concepto se distribuye entre varias neuronas, y cada neurona contribuye a representar varios conceptos, por lo que resulta difícil asignar conceptos directamente a neuronas individuales.
Esto es análogo a nuestros cerebros humanos. Del mismo modo que nuestros cerebros procesan la información sensorial y generan pensamientos, comportamientos y recuerdos, la ciencia desconoce los miles de millones, incluso billones, de procesos que hay detrás de estas funciones.
AnthropicEstudio intenta ver dentro de la caja negra de la IA con una técnica llamada "aprendizaje de diccionario".
Se trata de descomponer los patrones complejos de un modelo de IA en bloques de construcción lineales o "átomos" que tengan un sentido intuitivo para los humanos.
Mapeo de LLM con aprendizaje de diccionarios
En octubre de 2023, Anthropic aplicó este método a un minúsculo modelo lingüístico "de juguete" y encontró rasgos coherentes correspondientes a conceptos como texto en mayúsculas, secuencias de ADN, apellidos en citas, sustantivos matemáticos o argumentos de funciones en código Python.
Este último estudio amplía la técnica para que, en este caso, funcione con los modelos lingüísticos de IA más grandes de la actualidad, Anthropic's Claude 3 Soneto.
A continuación se explica paso a paso cómo funcionó el estudio:
Identificar patrones con el aprendizaje de diccionarios
Anthropic utilizó el aprendizaje de diccionarios para analizar las activaciones neuronales en diversos contextos e identificar patrones comunes.
El aprendizaje de diccionarios agrupa estas activaciones en un conjunto más pequeño de "características" significativas, que representan conceptos de nivel superior aprendidos por el modelo.
Al identificar estas características, los investigadores pueden comprender mejor cómo el modelo procesa y representa la información.
Extracción de características de la capa intermedia
Los investigadores se centraron en la capa media de Claude 3.0 Sonnet, que sirve de punto crítico en la cadena de procesamiento del modelo.
Aplicando el aprendizaje de diccionarios a esta capa se extraen millones de características que capturan las representaciones internas del modelo y los conceptos aprendidos en esta fase.
La extracción de características de la capa intermedia permite a los investigadores examinar la comprensión que tiene el modelo de la información después de ha procesado la entrada antes de generar el resultado final.
Descubrir conceptos diversos y abstractos
Las características extraídas revelaron una amplia gama de conceptos aprendidos por Claudedesde entidades concretas como ciudades y personas hasta nociones abstractas relacionadas con campos científicos y sintaxis de programación.
Curiosamente, las características resultaron ser multimodales, respondiendo tanto a entradas textuales como visuales, lo que indica que el modelo puede aprender y representar conceptos a través de diferentes modalidades.
Además, las características multilingües sugieren que el modelo puede captar conceptos expresados en varios idiomas.

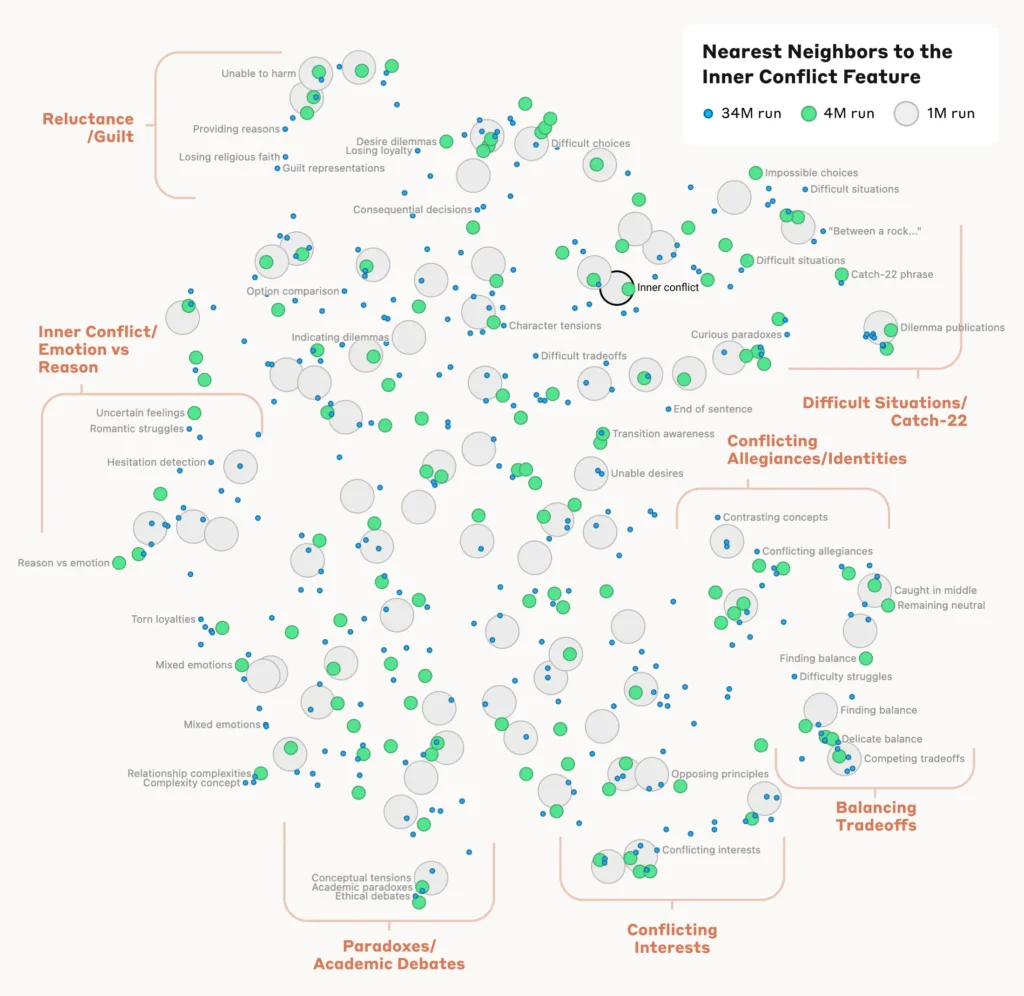
Analizar la organización de los conceptos
Para entender cómo el modelo organiza y relaciona los distintos conceptos, los investigadores analizaron la similitud entre rasgos basándose en sus patrones de activación.
Descubrieron que las características que representaban conceptos relacionados tendían a agruparse. Por ejemplo, los rasgos asociados a ciudades o disciplinas científicas mostraban una mayor similitud entre sí que los rasgos que representaban conceptos no relacionados.
Esto sugiere que la organización interna de los conceptos del modelo se ajusta, hasta cierto punto, a las intuiciones humanas sobre las relaciones conceptuales.
Verificación de las características
Para confirmar que las características identificadas influyen directamente en el comportamiento y los resultados del modelo, los investigadores realizaron experimentos de "dirección de características".
Se trataba de amplificar o suprimir selectivamente la activación de rasgos específicos durante el procesamiento del modelo y observar el impacto en sus respuestas.
Mediante la manipulación de características individuales, los investigadores pudieron establecer un vínculo directo entre las características individuales y el comportamiento del modelo. Por ejemplo, si se amplificaba una característica relacionada con una ciudad concreta, el modelo generaba resultados sesgados por la ciudad, incluso en contextos irrelevantes.
Lea el estudio completo aquí.
Por qué la interpretabilidad es fundamental para la seguridad de la IA
Anthropictiene una importancia fundamental para la interpretabilidad de la IA y, por extensión, para la seguridad.
Comprender cómo procesan y representan la información los LLM ayuda a los investigadores a entender y mitigar los riesgos. En sienta las bases para desarrollar sistemas de IA más transparentes y explicables.
En Anthropic Esperamos que nosotros y otros podamos utilizar estos descubrimientos para hacer más seguros los modelos. Por ejemplo, sería posible utilizar las técnicas aquí descritas para vigilar los sistemas de IA en busca de ciertos comportamientos peligrosos (como engañar al usuario), dirigirlos hacia resultados deseables (debiasing) o eliminar por completo ciertos temas peligrosos."
Comprender mejor el comportamiento de la IA es fundamental a medida que se hace omnipresente en los procesos de toma de decisiones críticas en campos como la sanidad, las finanzas y la justicia penal. También ayuda a descubrir la causa de sesgoalucinaciones y otros comportamientos no deseados o impredecibles.
Por ejemplo, un estudio reciente de la Universidad de Bonn descubrieron cómo las redes neuronales gráficas (GNN) utilizadas para el descubrimiento de fármacos se basan en gran medida en el recuerdo de similitudes a partir de datos de entrenamiento, en lugar de aprender realmente nuevas interacciones químicas complejas.
Esto dificulta la comprensión de cómo determinan exactamente estos modelos los nuevos compuestos de interés.
El año pasado, el El Gobierno británico negoció con grandes gigantes tecnológicos como OpenAI y DeepMindque desean acceder a los procesos internos de toma de decisiones de sus sistemas de IA.
Regulación como la Ley de IA de la UE presionará a las empresas de inteligencia artificial para que sean más transparentes, aunque los secretos comerciales seguirán guardados bajo llave.
Anthropicofrece una idea de lo que hay dentro de la caja al "mapear" la información a través del modelo.
Sin embargo, lo cierto es que estos modelos son tan amplios que, por AnthropicCreemos que es bastante probable que nos falten órdenes de magnitud, y que si quisiéramos obtener todas las características -¡en todas las capas! - tendríamos que utilizar muchos más recursos informáticos que los necesarios para entrenar los modelos subyacentes".
Es un punto interesante: la ingeniería inversa de un modelo es más compleja desde el punto de vista computacional que la ingeniería del modelo en primer lugar.
Es una reminiscencia de proyectos neurocientíficos enormemente caros como el Proyecto Cerebro Humano (HBP)que invirtió miles de millones en cartografiar nuestros cerebros para acabar fracasando.
Nunca subestimes lo mucho que hay dentro de la caja negra.



