

La Universidad de Stanford publicó su Informe sobre el Índice de Inteligencia Artificial 2024, en el que señalaba que el rápido avance de la IA hace que las comparaciones con los humanos sean cada vez menos pertinentes.
En informe anual ofrece una visión exhaustiva de las tendencias y el estado de la evolución de la IA. El informe afirma que los modelos de IA están mejorando tan rápidamente que los parámetros que utilizamos para medirlos son cada vez más irrelevantes.
Muchas pruebas comparativas del sector comparan los modelos de IA con la capacidad de los humanos para realizar tareas. La prueba comparativa Massive Multitask Language Understanding (MMLU) es un buen ejemplo.
Utiliza preguntas de opción múltiple para evaluar LLMs a través de 57 temas, incluyendo matemáticas, historia, derecho y ética. El MMLU ha sido la referencia en IA desde 2019.
La puntuación de referencia humana en el MMLU es de 89,8%, y ya en 2019, el modelo de IA medio obtuvo una puntuación ligeramente superior a 30%. Solo 5 años después, Gemini Ultra se convirtió en el primer modelo en superar la puntuación de referencia humana con 90,04%.
El informe señala que los actuales "sistemas de IA superan habitualmente el rendimiento humano en los puntos de referencia estándar". Las tendencias del gráfico siguiente parecen indicar que el MMLU y otros puntos de referencia necesitan ser sustituidos.
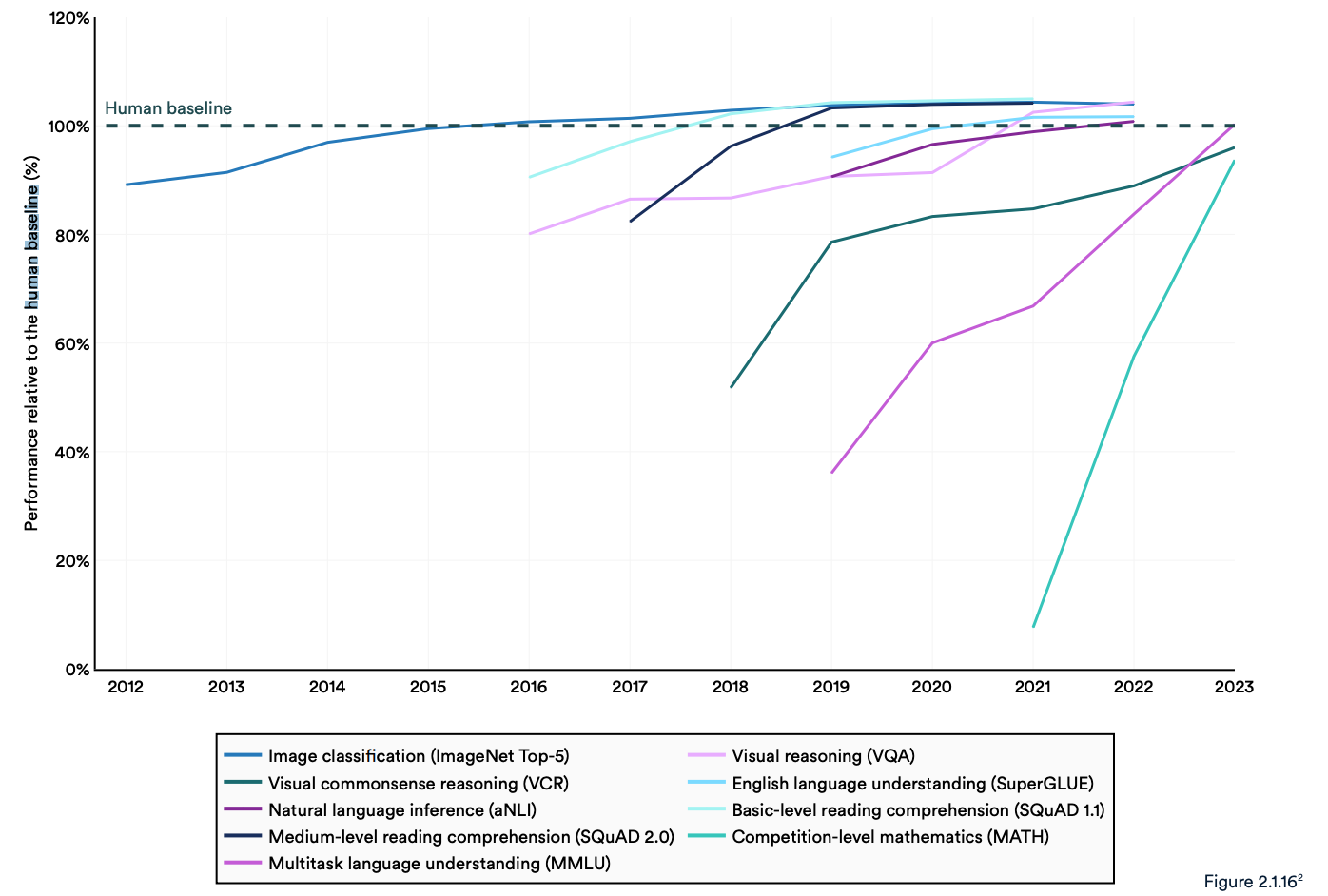
Los modelos de IA han alcanzado la saturación de rendimiento en pruebas de referencia establecidas como ImageNet, SQuAD y SuperGLUE, por lo que los investigadores están desarrollando pruebas más exigentes.
Un ejemplo es el Graduate-Level Google-Proof Q&A Benchmark (GPQA), que permite comparar modelos de IA con personas realmente inteligentes, en lugar de con la inteligencia humana media.
El examen GPQA consta de 400 preguntas tipo test de nivel universitario. Los expertos que han obtenido o están obteniendo un doctorado responden correctamente a las preguntas el 65% de las veces.
El documento del GPQA señala que, cuando se les plantean preguntas ajenas a su campo, "los validadores no expertos altamente cualificados sólo alcanzan una precisión de 34%, a pesar de pasar una media de más de 30 minutos con acceso ilimitado a la web".
El mes pasado Anthropic anunció que Claude 3 anotó un poco menos de 60% con 5 disparos de CoT. Vamos a necesitar un punto de referencia más grande.
Claude 3 obtiene ~60% de precisión en el GPQA. Me resulta difícil subestimar lo difíciles que son estas preguntas: doctores literales (en ámbitos distintos a los de las preguntas) con acceso a Internet obtienen 34%.
Los doctores *en el mismo ámbito* (¡también con acceso a Internet!) obtienen una precisión de 65% - 75%. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4 de marzo de 2024
Evaluaciones humanas y seguridad
El informe señalaba que la IA aún se enfrenta a problemas importantes: "No puede tratar de forma fiable los hechos, realizar razonamientos complejos ni explicar sus conclusiones".
Estas limitaciones contribuyen a otra característica del sistema de IA que, según el informe, no se mide bien; Seguridad de la IA. No tenemos puntos de referencia eficaces que nos permitan decir: "Este modelo es más seguro que aquel".
En parte porque es difícil de medir, y en parte porque "los desarrolladores de IA carecen de transparencia, especialmente en lo que se refiere a la divulgación de datos de entrenamiento y metodologías."
El informe señala que una tendencia interesante en el sector es recurrir a evaluaciones humanas del rendimiento de la IA, en lugar de pruebas comparativas.
Clasificar la estética o la prosa de la imagen de un modelo es difícil de hacer con un test. Como resultado, el informe afirma que "la evaluación comparativa ha empezado a cambiar lentamente hacia la incorporación de evaluaciones humanas como la Chatbot Arena Leaderboard en lugar de clasificaciones informatizadas como ImageNet o SQuAD."
A medida que los modelos de IA ven desaparecer la línea de base humana por el retrovisor, el sentimiento puede acabar determinando qué modelo elegimos utilizar.
Las tendencias indican que los modelos de IA acabarán siendo más inteligentes que nosotros y más difíciles de medir. Puede que pronto nos encontremos diciendo: "No sé por qué, pero este me gusta más".



