

Google DeepMind ha presentado Gecko, una nueva referencia para evaluar de forma exhaustiva los modelos de conversión de texto en imagen (T2I).
En los últimos dos años, hemos visto generadores de imágenes de IA como DALL-E y A mitad de camino mejoran progresivamente con cada versión.
Sin embargo, decidir cuál de los modelos subyacentes que utilizan estas plataformas es el mejor ha sido en gran medida subjetivo y difícil de evaluar comparativamente.
Afirmar a grandes rasgos que un modelo es "mejor" que otro no es tan sencillo. Cada modelo destaca en distintos aspectos de la generación de imágenes. Uno puede ser bueno en la representación de texto, mientras que otro puede ser mejor en la interacción con objetos.
Un reto clave al que se enfrentan los modelos T2I es seguir cada detalle de la indicación y que éstos se reflejen con precisión en la imagen generada.
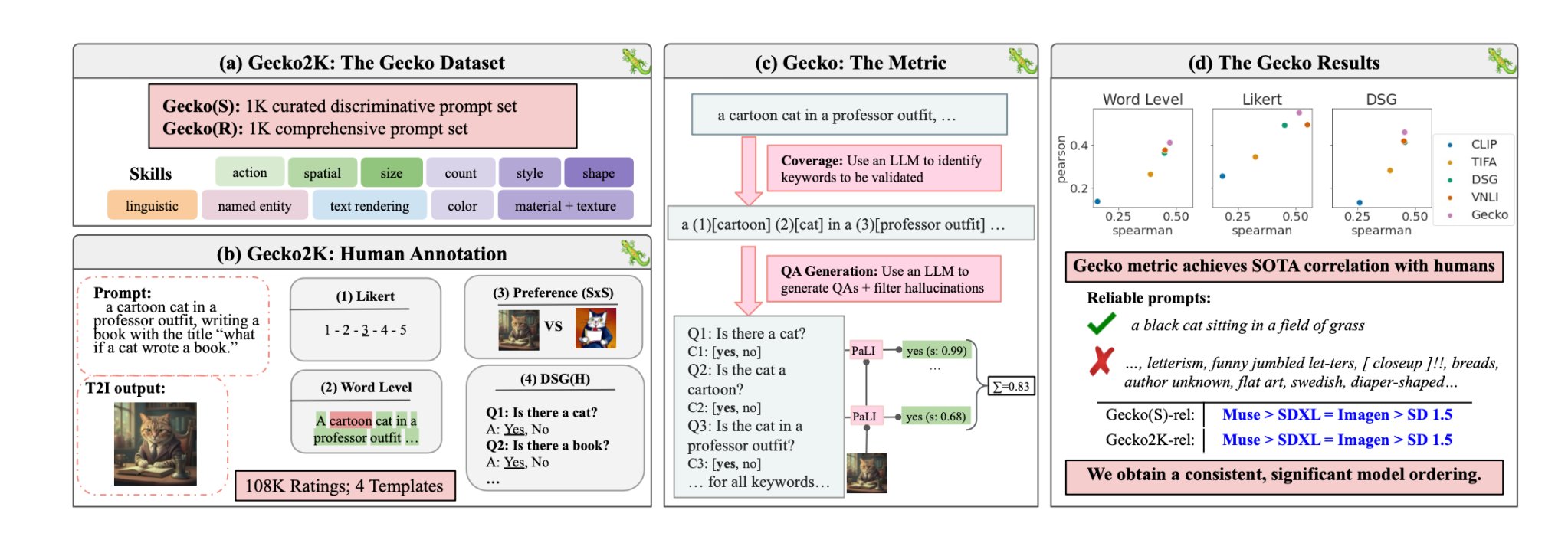
Con Gecko, el DeepMind investigadores han creado un referencia que evalúa las capacidades de los modelos T2I de forma similar a como lo hacen los humanos.
Competencias
En primer lugar, los investigadores definieron un amplio conjunto de habilidades relevantes para la generación de T2I. Entre ellas se incluyen la comprensión espacial, el reconocimiento de acciones, la representación de textos y otras. A continuación, las dividieron en subhabilidades más específicas.
Por ejemplo, en representación de texto, las subhabilidades podrían incluir la representación de diferentes fuentes, colores o tamaños de texto.
A continuación, se utilizó un LLM para generar indicaciones que pusieran a prueba la capacidad del modelo T2I en una habilidad o subhabilidad específica.
Esto permite a los creadores de un modelo T2I determinar no sólo qué destrezas suponen un reto, sino a qué nivel de complejidad una destreza se convierte en un reto para su modelo.
Humano vs Autoevaluación
Gecko también mide la precisión con la que un modelo T2I sigue todos los detalles de una pregunta. Una vez más, se utilizó un LLM para aislar los detalles clave de cada pregunta y generar un conjunto de preguntas relacionadas con esos detalles.
Estas preguntas pueden ser tanto sencillas y directas sobre elementos visibles en la imagen (por ejemplo, "¿Hay un gato en la imagen?") como más complejas, que ponen a prueba la comprensión de la escena o las relaciones entre objetos (por ejemplo, "¿Está el gato sentado encima del libro?").
A continuación, un modelo de respuesta a preguntas visuales (VQA) analiza la imagen generada y responde a las preguntas para comprobar la precisión con la que el modelo T2I alinea su imagen de salida con una pregunta de entrada.
Los investigadores recopilaron más de 100.000 anotaciones humanas en las que los participantes puntuaban una imagen generada en función de lo alineada que estuviera con criterios específicos.
Se pedía a los humanos que tuvieran en cuenta un aspecto concreto de la pregunta y puntuaran la imagen en una escala de 1 a 5 en función de su adecuación a la pregunta.
Utilizando las evaluaciones anotadas por humanos como patrón oro, los investigadores pudieron confirmar que su métrica de autoevaluación "se correlaciona mejor con las valoraciones humanas que las métricas existentes para nuestro nuevo conjunto de datos".
El resultado es un sistema de evaluación comparativa capaz de poner cifras a los factores específicos que hacen que una imagen generada sea buena o no.
Esencialmente, Gecko puntúa la imagen de salida de un modo que se ajusta a cómo decidimos intuitivamente si estamos satisfechos o no con la imagen generada.
¿Cuál es el mejor modelo de conversión de texto en imagen?
En su papellos investigadores concluyeron que el modelo Muse de Google supera a Stable Diffusion 1.5 y SDXL en la prueba Gecko. Puede que sean parciales, pero los números no mienten.



