

Investigadores de DeepMind y la Universidad de Stanford desarrollaron un agente de IA que comprueba los LLM y permite evaluar la factualidad de los modelos de IA.
Incluso los mejores modelos de IA tienden a alucinar a veces. Si le pides a ChatGPT que te dé los hechos sobre un tema, cuanto más larga sea su respuesta más probable es que incluya algunos hechos que no son ciertos.
¿Qué modelos son más precisos que otros a la hora de generar respuestas largas? Es difícil saberlo, porque hasta ahora no disponíamos de un punto de referencia para medir la veracidad de las respuestas largas de los LLM.
DeepMind utilizó en primer lugar la GPT-4 para crear LongFact, un conjunto de 2.280 preguntas relacionadas con 38 temas. Estas preguntas obtienen respuestas largas del LLM que se está evaluando.
A continuación, crearon un agente de IA con GPT-3.5-turbo para que utilizara Google para verificar la veracidad de las respuestas generadas por el LLM. Llamaron a este método Search-Augmented Factuality Evaluator (SAFE).
SAFE descompone primero la respuesta larga del LLM en hechos individuales. A continuación, envía solicitudes de búsqueda a Google Search y razona sobre la veracidad del hecho basándose en la información de los resultados de búsqueda devueltos.
He aquí un ejemplo de la trabajo de investigación.
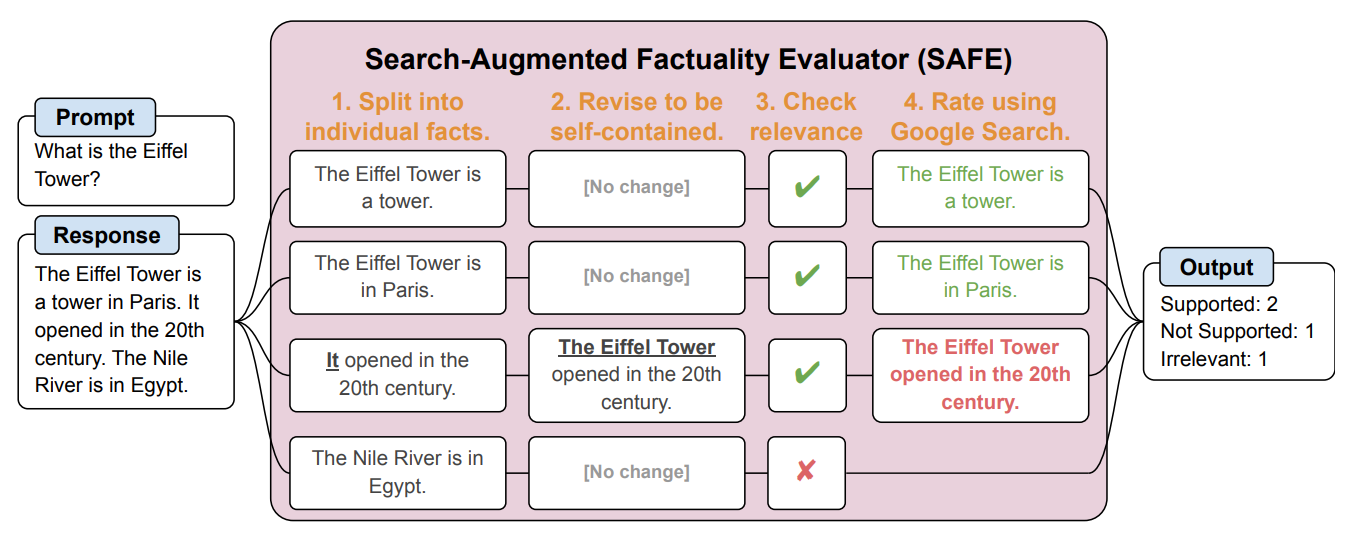
Los investigadores afirman que SAFE consigue un "rendimiento sobrehumano" en comparación con los anotadores humanos que realizan la comprobación.
SAFE coincidió con el 72% de las anotaciones humanas y, en los casos en que discrepó de los humanos, acertó el 76% de las veces. Además, resultaba 20 veces más barato que los anotadores humanos. Así pues, los LLM son mejores y más baratos verificadores de hechos que los humanos.
La calidad de la respuesta de los LLM evaluados se midió en función del número de factoides en su respuesta combinada con el grado de veracidad de los factoides individuales.
La métrica que utilizaron (F1@K) calcula el número "ideal" de hechos que prefiere el ser humano en una respuesta. Las pruebas de referencia utilizaron 64 como mediana para K y 178 como máximo.
En pocas palabras, F1@K es una medida de "¿Me dio la respuesta tantos datos como quería?" combinada con "¿Cuántos de esos datos eran ciertos?".
¿Qué LLM es más factual?
Los investigadores utilizaron LongFact para preguntar a 13 LLM de las familias Gemini, GPT, Claude y PaLM-2. A continuación, utilizaron SAFE para evaluar la veracidad de sus respuestas.
GPT-4-Turbo encabeza la lista como modelo más factual a la hora de generar respuestas largas. Le siguen de cerca Gemini-Ultra y PaLM-2-L-IT-RLHF. Los resultados mostraron que los LLM más grandes son más factuales que los más pequeños.
El cálculo de F1@K probablemente entusiasmaría a los científicos de datos, pero, en aras de la simplicidad, estos resultados de referencia muestran lo factual que es cada modelo cuando devuelve respuestas de longitud media y más largas a las preguntas.
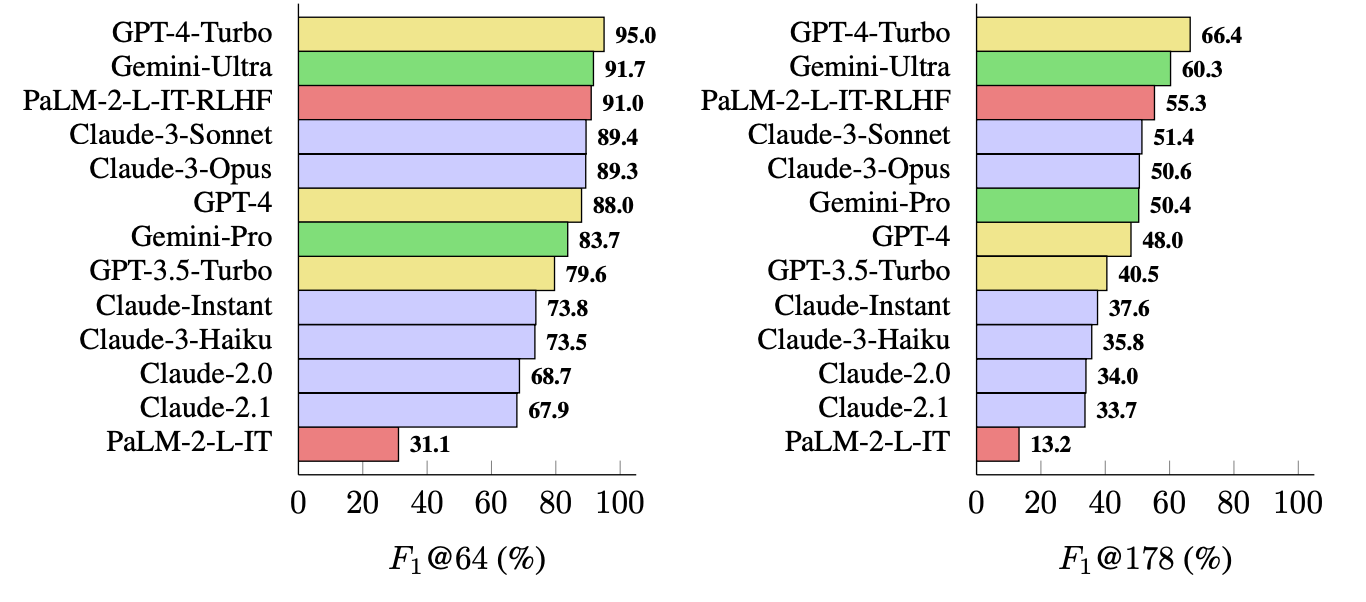
SAFE es una forma barata y eficaz de cuantificar la veracidad de los hechos a largo plazo. Es más rápido y barato que la comprobación de hechos por humanos, pero sigue dependiendo de la veracidad de la información que Google devuelve en los resultados de búsqueda.
DeepMind lanzó SAFE para uso público y sugirió que podría ayudar a mejorar la factualidad de los LLM mediante un mejor preentrenamiento y ajuste. También podría permitir a un LLM comprobar sus hechos antes de presentar el resultado a un usuario.
OpenAI se alegrará de ver que un estudio de Google muestra que GPT-4 supera a Gemini en otra prueba comparativa.



