

Genie, de Google DeepMind, es un modelo generativo que traduce simples imágenes o mensajes de texto en mundos dinámicos e interactivos.
Genie se entrenó con un extenso conjunto de datos de más de 200.000 horas de secuencias de vídeo de juegos, incluidos juegos de plataformas en 2D e interacciones robóticas en el mundo real.
Este vasto conjunto de datos permitió a Genie comprender y generar la física, la dinámica y la estética de numerosos entornos y objetos.
El modelo final, documentado en un trabajo de investigacióncontiene 11.000 millones de parámetros para generar mundos virtuales interactivos a partir de imágenes en múltiples formatos o mensajes de texto.
Así, puedes dar a Genie una imagen de tu salón o jardín y convertirla en un nivel de plataformas 2D jugable.
O garabatear un entorno 2D en un trozo de papel y convertirlo en un entorno jugable.
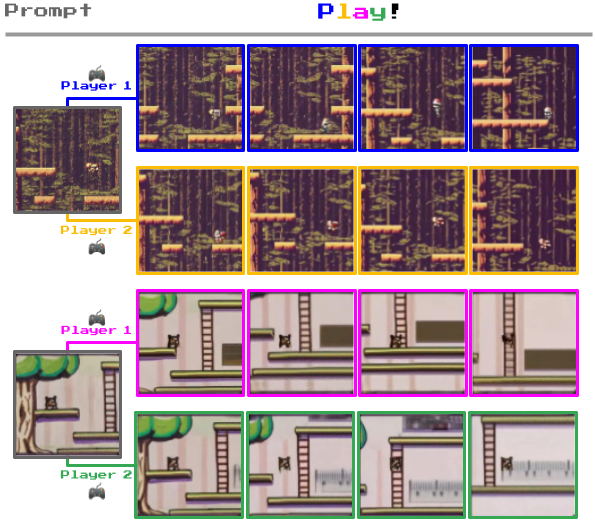
Lo que diferencia a Genie de otros modelos de mundo es su capacidad para permitir a los usuarios interactuar con los entornos generados fotograma a fotograma.
Por ejemplo, a continuación puedes ver cómo Genie toma fotografías de entornos del mundo real y las convierte en niveles de juego en 2D.

Cómo funciona Genie
Genie es un "modelo de mundo fundacional" con tres componentes clave: un tokenizador espaciotemporal de vídeo, un modelo de dinámica autorregresiva y un modelo de acción latente (LAM) sencillo y escalable.
Así es como funciona:
- Transformadores espaciotemporales: Un elemento central de Genie son los transformadores espaciotemporales (ST), que procesan secuencias de fotogramas de vídeo. A diferencia de los transformadores tradicionales que manejan texto o imágenes estáticas, los transformadores ST están diseñados para comprender la progresión de los datos visuales a lo largo del tiempo, lo que los hace ideales para la generación de vídeo y entornos dinámicos.
- Modelo de acción latente (MLA): Genie comprende y predice acciones dentro de sus mundos generados a través del LAM. Este infiere las acciones potenciales que podrían ocurrir entre los fotogramas de un vídeo, aprendiendo un conjunto de "acciones latentes" directamente de los datos visuales. Esto permite a Genie controlar la progresión de los acontecimientos en entornos interactivos, a pesar de la ausencia de etiquetas de acción explícitas en los datos de entrenamiento.
- Tokenizador de vídeo y modelo dinámico: Para gestionar los datos de vídeo, Genie emplea un tokenizador de vídeo que comprime los fotogramas de vídeo en bruto en un formato más manejable de tokens discretos. Tras la tokenización, el modelo dinámico predice el siguiente conjunto de tokens de fotogramas, generando fotogramas posteriores en el entorno interactivo.
El equipo de DeepMind explicó lo siguiente sobre Genie: "Genie podría permitir a un gran número de personas generar sus propias experiencias de juego. Esto podría ser positivo para quienes deseen expresar su creatividad de una forma nueva, por ejemplo, los niños, que podrían diseñar y adentrarse en sus propios mundos imaginados".
En un experimento paralelo, cuando se le presentaron vídeos de brazos robóticos reales interactuando con objetos del mundo real, Genie demostró una asombrosa capacidad para descifrar las acciones que estos brazos podían realizar. Esto demuestra su potencial para la investigación robótica.
Tim Rocktäschel, del equipo de Genie, describió el potencial abierto de Genie: "Es difícil predecir qué casos de uso serán posibles. Esperamos que proyectos como Genie acaben proporcionando a la gente nuevas herramientas para expresar su creatividad".
DeepMind era consciente de los riesgos de divulgar este modelo de cimentación, por lo que afirmaba en el documento: "Hemos optado por no divulgar los puntos de control del modelo entrenado, el conjunto de datos de entrenamiento del modelo o ejemplos de esos datos para acompañar este documento o el sitio web."
"Nos gustaría tener la oportunidad de seguir colaborando con la comunidad investigadora (y de videojuegos) y garantizar que cualquier futuro lanzamiento de este tipo sea respetuoso, seguro y responsable".
Utilizar juegos para simular aplicaciones del mundo real
DeepMind ha utilizado videojuegos para varios proyectos de aprendizaje automático.
Por ejemplo, en 2021, DeepMind construyó XLandun campo de juego virtual para probar enfoques de aprendizaje por refuerzo (RL) para agentes de IA generalistas. Aquí, los modelos de IA dominaban la cooperación y la resolución de problemas realizando tareas como mover obstáculos en entornos de juego abiertos.
Luego, el mes pasado, SIMA (Scalable, Instructable, Multiworld Agent) fue diseñado para comprender y ejecutar instrucciones en lenguaje humano a través de diferentes juegos y escenarios.
SIMA se entrenó con nueve videojuegos que requerían distintas habilidades, desde la navegación básica hasta el pilotaje de vehículos.
Los entornos de juego ofrecen una caja de arena controlable y escalable para entrenar y probar modelos de IA.
La experiencia de DeepMind en juegos se remonta a 2014-2015, cuando desarrollaron un algoritmo para derrotar a humanos en juegos como Pong y Space Invaders, por no hablar de AlphaGo, que derrotó al jugador profesional Fan Hui en un tablero de 19×19 a tamaño real.



