

Apple aún no ha lanzado oficialmente un modelo de IA, pero un nuevo trabajo de investigación da una idea de los avances de la compañía en el desarrollo de modelos con capacidades multimodales de última generación.
El periódicotitulado "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training", presenta la familia de MLLM de Apple denominada MM1.
MM1 muestra unas capacidades impresionantes en el subtitulado de imágenes, la respuesta a preguntas visuales (VQA) y la inferencia de lenguaje natural. Los investigadores explican que la cuidadosa elección de los pares imagen-titular les permitió obtener resultados superiores, especialmente en escenarios de aprendizaje con pocas imágenes.
Lo que diferencia al MM1 de otros MLLM es su capacidad superior para seguir instrucciones a través de múltiples imágenes y para razonar sobre las complejas escenas que se le presentan.
Los modelos MM1 contienen hasta 30B de parámetros, el triple que GPT-4V, el componente que dota a GPT-4 de OpenAI de sus capacidades de visión.
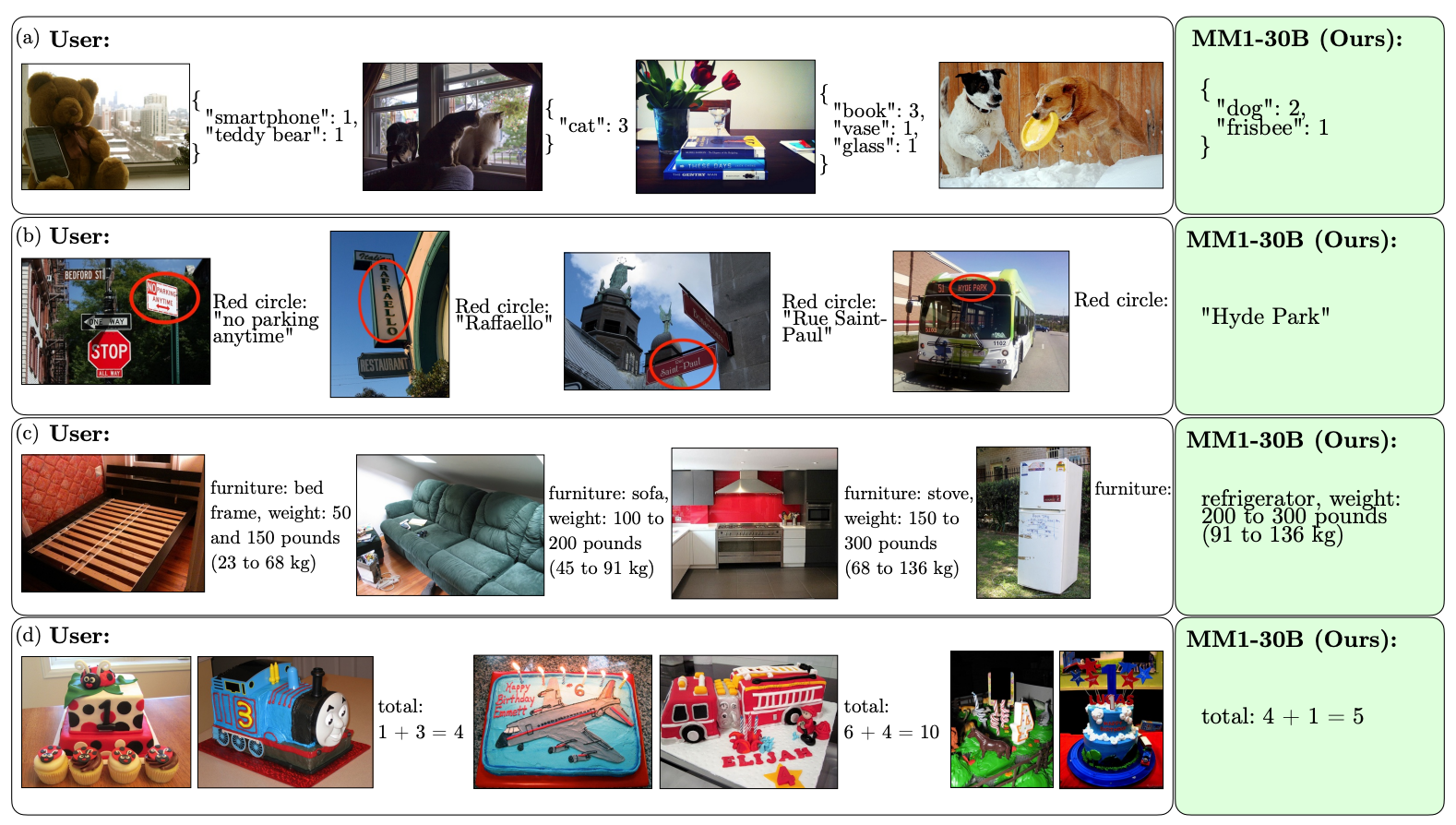
Estos son algunos ejemplos de las capacidades VQA de MM1.

MM1 se sometió a un preentrenamiento multimodal a gran escala sobre "un conjunto de datos de 500M documentos imagen-texto intercalados, que contenían 1B imágenes y 500B tokens de texto".
La escala y la diversidad de su preentrenamiento permiten a MM1 realizar impresionantes predicciones en contexto y seguir un formato personalizado con un pequeño número de ejemplos de pocas tomas. A continuación se muestran ejemplos de cómo MM1 aprende la salida y el formato deseados a partir de solo 3 ejemplos.
Para crear modelos de IA que puedan "ver" y razonar se necesita un conector de visión-lenguaje que traduzca las imágenes y el lenguaje en una representación unificada que el modelo pueda utilizar para su posterior procesamiento.
Los investigadores descubrieron que el diseño del conector visión-lenguaje era un factor menos determinante en el rendimiento de MM1. Curiosamente, fueron la resolución de la imagen y el número de tokens de imagen los que tuvieron un mayor impacto.
Es interesante ver lo abierta que ha sido Apple a la hora de compartir sus investigaciones con la comunidad de la IA en general. Los investigadores afirman que "en este artículo, documentamos el proceso de construcción de MLLM e intentamos formular lecciones de diseño, que esperamos sean de utilidad para la comunidad."
Es probable que los resultados publicados orienten a otros desarrolladores de MMLM en la elección de la arquitectura y los datos de preentrenamiento.
Queda por ver cómo se implementarán exactamente los modelos MM1 en los productos de Apple. Los ejemplos publicados de las capacidades de MM1 apuntan a que Siri será mucho más inteligente cuando aprenda a ver.



