

A pesar de los rápidos avances de los LLM, seguimos sin comprender cómo estos modelos hacen frente a entradas más largas.
Mosh Levy, Alon Jacoby y Yoav Goldberg, de la Universidad Bar-Ilan y el Instituto Allen de Inteligencia Artificial, investigaron cómo varía el rendimiento de los grandes modelos lingüísticos (LLM) en función de la longitud del texto de entrada que deben procesar.
Desarrollaron un marco de razonamiento específico para este fin, que les permitió diseccionar la influencia de la longitud de la entrada en el razonamiento LLM en un entorno controlado.
El marco de preguntas proponía diferentes versiones de la misma pregunta, cada una de las cuales contenía la información necesaria para responder a la pregunta, rellenada con texto adicional irrelevante de longitud y tipo variables.
Esto permite aislar la longitud de la entrada como variable, garantizando que los cambios en el rendimiento del modelo puedan atribuirse directamente a la longitud de la entrada.
Principales resultados
Levy, Jacoby y Goldberg descubrieron que los LLM muestran un notable descenso en el rendimiento del razonamiento a longitudes de entrada muy por debajo de lo que los desarrolladores afirman que pueden manejar. Documentaron sus hallazgos en este estudio.
El declive se observó sistemáticamente en todas las versiones del conjunto de datos, lo que indica un problema sistémico con el manejo de entradas más largas en lugar de un problema vinculado a muestras de datos o arquitecturas de modelos específicas.
Como describen los investigadores, "nuestros hallazgos muestran una notable degradación en el rendimiento de razonamiento de los LLM a longitudes de entrada mucho más cortas que su máximo técnico. Demostramos que la tendencia a la degradación aparece en todas las versiones de nuestro conjunto de datos, aunque con diferentes intensidades."

Además, el estudio pone de relieve cómo las métricas tradicionales como la perplejidad, utilizadas habitualmente para evaluar los LLM, no se correlacionan con el rendimiento de los modelos en tareas de razonamiento que implican entradas largas.
Una exploración más profunda descubrió que la degradación del rendimiento no dependía únicamente de la presencia de información irrelevante (relleno), sino que se observaba incluso cuando dicho relleno consistía en información relevante duplicada.
Cuando mantenemos juntos los dos vanos centrales y añadimos texto a su alrededor, la precisión ya baja. Introduciendo párrafos entre los espacios, los resultados bajan mucho más. El descenso se produce tanto cuando los textos que añadimos son similares a los de la tarea como cuando son completamente diferentes. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26 de febrero de 2024
Esto sugiere que el reto para los LLM reside en filtrar el ruido y el procesamiento inherente a las secuencias de texto más largas.
Ignorar las instrucciones
Un modo de fallo crítico que se destaca en el estudio es la tendencia de los LLM a ignorar las instrucciones incrustadas en la entrada a medida que ésta aumenta.
Los modelos también generaban a veces respuestas que indicaban incertidumbre o falta de información suficiente, como "No hay suficiente información en el texto", a pesar de contar con toda la información necesaria.
En general, a medida que aumenta la longitud de la información, los estudiantes de LLM parecen tener dificultades para priorizar y centrarse en los elementos de información clave, incluidas las instrucciones directas.
Mostrar sesgos en las respuestas
Otro problema notable fue el aumento de los sesgos en las respuestas de los modelos a medida que las entradas se hacían más largas.
En concreto, los LLM mostraron un sesgo hacia la respuesta "Falso" a medida que aumentaba la longitud de la entrada. Este sesgo indica un sesgo en la estimación de probabilidades o en los procesos de toma de decisiones dentro del modelo, posiblemente como mecanismo defensivo en respuesta a la mayor incertidumbre debida a la mayor longitud de las entradas.
La inclinación a favorecer las respuestas "Falsas" también podría reflejar un desequilibrio subyacente en los datos de entrenamiento o un artefacto del proceso de entrenamiento de los modelos, donde las respuestas negativas pueden estar sobrerrepresentadas o asociadas a contextos de incertidumbre y ambigüedad.
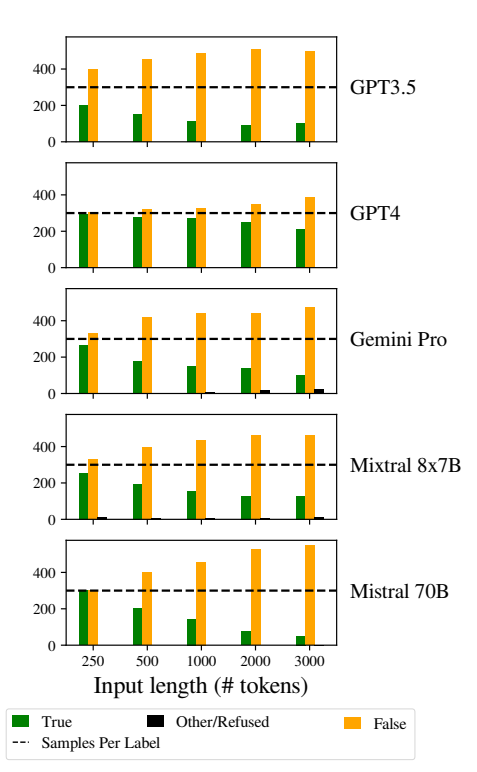
Este sesgo afecta a la precisión de los resultados de los modelos y suscita dudas sobre la fiabilidad y equidad de los LLM en aplicaciones que requieren una comprensión matizada e imparcialidad.
La aplicación de estrategias sólidas de detección y mitigación de sesgos durante las fases de entrenamiento y ajuste de los modelos es esencial para reducir los sesgos injustificados en las respuestas de los modelos.
Earantizar que los conjuntos de datos de entrenamiento sean diversos, equilibrados y representativos de una amplia gama de escenarios también puede ayudar a minimizar los sesgos y mejorar la generalización de los modelos.
Esto contribuye a otros estudios recientes que, del mismo modo, ponen de manifiesto problemas fundamentales en el funcionamiento de los LLM, lo que lleva a una situación en la que esa "deuda técnica" podría amenazar la funcionalidad y la integridad del modelo con el paso del tiempo.



