
La selección de pacientes para encontrar participantes adecuados para ensayos clínicos es una tarea laboriosa, costosa y propensa a errores, pero la IA pronto podría solucionarlo.
Un equipo de investigadores del Brigham and Women's Hospital, la Facultad de Medicina de Harvard y el Mass General Brigham Personalized Medicine, realizó un estudio para comprobar si un modelo de IA podía procesar historiales médicos para encontrar candidatos adecuados para ensayos clínicos.
Utilizaron GPT-4V, el LLM de OpenAI con procesamiento de imágenes, habilitado por Retrieval-Augmented Generation (RAG) para procesar las historias clínicas electrónicas (HCE) y las notas clínicas de los posibles candidatos.
Los LLM se entrenan previamente utilizando un conjunto de datos fijo y sólo pueden responder a preguntas basadas en esos datos. La GAR es una técnica que permite a un LLM recuperar datos de fuentes externas, como Internet o los documentos internos de una organización.
Cuando se selecciona a los participantes de un ensayo clínico, su idoneidad se determina mediante una lista de criterios de inclusión y exclusión. Para ello, normalmente es necesario que personal cualificado rastree las historias clínicas electrónicas de cientos o miles de pacientes para encontrar a los que cumplen los criterios.
Los investigadores recopilaron datos de un ensayo cuyo objetivo era reclutar pacientes con insuficiencia cardiaca sintomática. Utilizaron esos datos para ver si la GPT-4V con RAG podía hacer el trabajo de forma más eficiente que el personal del estudio, manteniendo la precisión.
Los datos estructurados de las HCE de los posibles candidatos podrían utilizarse para determinar 5 de 6 criterios de inclusión y 5 de 17 de exclusión para el ensayo clínico. Esa es la parte fácil.
Los 13 criterios restantes debían determinarse consultando los datos no estructurados de las notas clínicas de cada paciente, que es la parte laboriosa en la que los investigadores esperaban que les ayudara la IA.
🔍Can @Microsoft @Azure @OpenAI's #GPT4 ¿se comporta mejor que un ser humano en el cribado de ensayos clínicos? Nos hemos hecho esta pregunta en nuestro estudio más reciente y me complace enormemente compartir nuestros resultados en preprint:https://t.co/lhOPKCcudP
Integrar la GPT4 en los ensayos clínicos no es...- Ozan Unlu (@OzanUnluMD) 9 de febrero de 2024
Resultados
En primer lugar, los investigadores obtuvieron evaluaciones estructuradas realizadas por el personal del estudio y notas clínicas de los dos últimos años.
Desarrollaron un flujo de trabajo para un sistema de respuesta a preguntas basado en notas clínicas con arquitectura RAG y GPT-4V y lo denominaron RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review).
Se utilizaron las notas de 100 pacientes como conjunto de datos de desarrollo, 282 pacientes como conjunto de datos de validación y 1894 pacientes como conjunto de prueba.
Un clínico experto realizó una revisión ciega de las historias clínicas de los pacientes para responder a las preguntas de elegibilidad y determinar las respuestas "patrón oro". A continuación, se compararon con las respuestas del personal del estudio y RECTIFIER en función de los siguientes criterios:
- Sensibilidad: capacidad de una prueba para identificar correctamente a los pacientes aptos para el ensayo (verdaderos positivos).
- Especificidad: capacidad de una prueba para identificar correctamente a los pacientes no aptos para el ensayo (verdaderos negativos).
- Precisión - Proporción global de clasificaciones correctas (tanto verdaderos positivos como verdaderos negativos).
- Coeficiente de correlación de Matthews (CCM): métrica utilizada para medir la eficacia del modelo a la hora de seleccionar o excluir a una persona. Un valor de 0 equivale a lanzar una moneda al aire y 1 representa acertar el 100% de las veces.
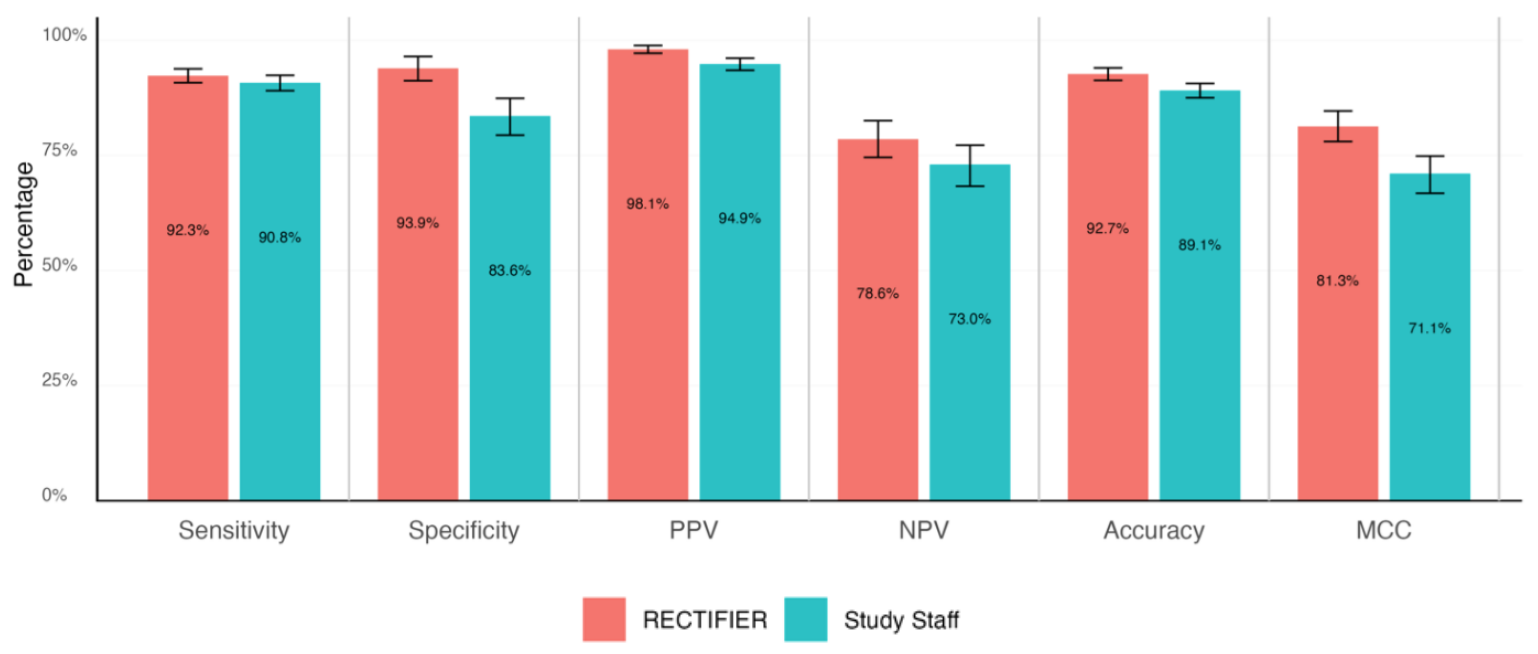
RECTIFIER funcionó tan bien, y en algunos casos mejor, que el personal del estudio. Probablemente, el resultado más significativo del estudio procedía de la comparación de costes.
Aunque no se facilitaron cifras sobre la remuneración del personal del estudio, debió de ser bastante superior al coste de utilizar la GPT-4V, que osciló entre $0,02 y $0,10 por paciente. Utilizar la IA para evaluar un grupo de 1.000 candidatos potenciales llevaría unos minutos y costaría alrededor de $100.
Los investigadores concluyeron que el uso de un modelo de IA como GPT-4V con RAG puede mantener o mejorar la precisión en la identificación de candidatos para ensayos clínicos, y hacerlo de forma más eficiente y mucho más barata que utilizando personal humano.
Señalaron la necesidad de ser cautelosos a la hora de entregar la atención médica a sistemas automatizados, pero parece que la IA hará mejor trabajo que nosotros si se dirige adecuadamente.



