

Investigadores de la Universidad de California en San Diego y de la Universidad de Nueva York desarrollaron V*, un algoritmo de búsqueda guiada por LLM que es mucho mejor que GPT-4V en la comprensión contextual y la localización precisa de elementos visuales específicos en las imágenes.
Los modelos multimodales de lenguaje amplio (MLLM), como GPT-4V de OpenAI, nos dejaron boquiabiertos el año pasado con su capacidad para responder a preguntas sobre imágenes. A pesar de lo impresionante que es GPT-4V, a veces tiene problemas cuando las imágenes son muy complejas y a menudo pasa por alto pequeños detalles.
El algoritmo V* utiliza un LLM de respuesta a preguntas visuales (VQA) que le sirve de guía para identificar en qué zona de la imagen debe centrarse para responder a una consulta visual. Los investigadores denominan a esta combinación Show, sEArch y telL (SEAL).
Si alguien te diera una imagen de alta resolución y te hiciera una pregunta sobre ella, tu lógica te guiaría para que hicieras zoom en una zona donde fuera más probable encontrar el objeto en cuestión. SEAL utiliza V* para analizar imágenes de forma similar.
Un modelo de búsqueda visual podría limitarse a dividir una imagen en bloques, hacer zoom en cada uno de ellos y procesarlos para encontrar el objeto en cuestión, pero eso es muy ineficiente desde el punto de vista computacional.
Cuando se le plantea una consulta textual sobre una imagen, V* intenta en primer lugar localizar directamente el objetivo de la imagen. Si no lo consigue, pide al MLLM que utilice el sentido común para identificar en qué zona de la imagen es más probable que se encuentre el objetivo.
A continuación, centra su búsqueda sólo en esa zona, en lugar de intentar una búsqueda "ampliada" de toda la imagen.

Cuando se pide a GPT-4V que responda a preguntas sobre una imagen que requiere un procesamiento visual exhaustivo de imágenes de alta resolución, tiene dificultades. El SEAL que utiliza V* funciona mucho mejor.

Cuando se le preguntó "¿Qué tipo de bebida podemos comprar en esa máquina expendedora?" SEAL respondió "Coca-Cola", mientras que GPT-4V adivinó incorrectamente "Pepsi".
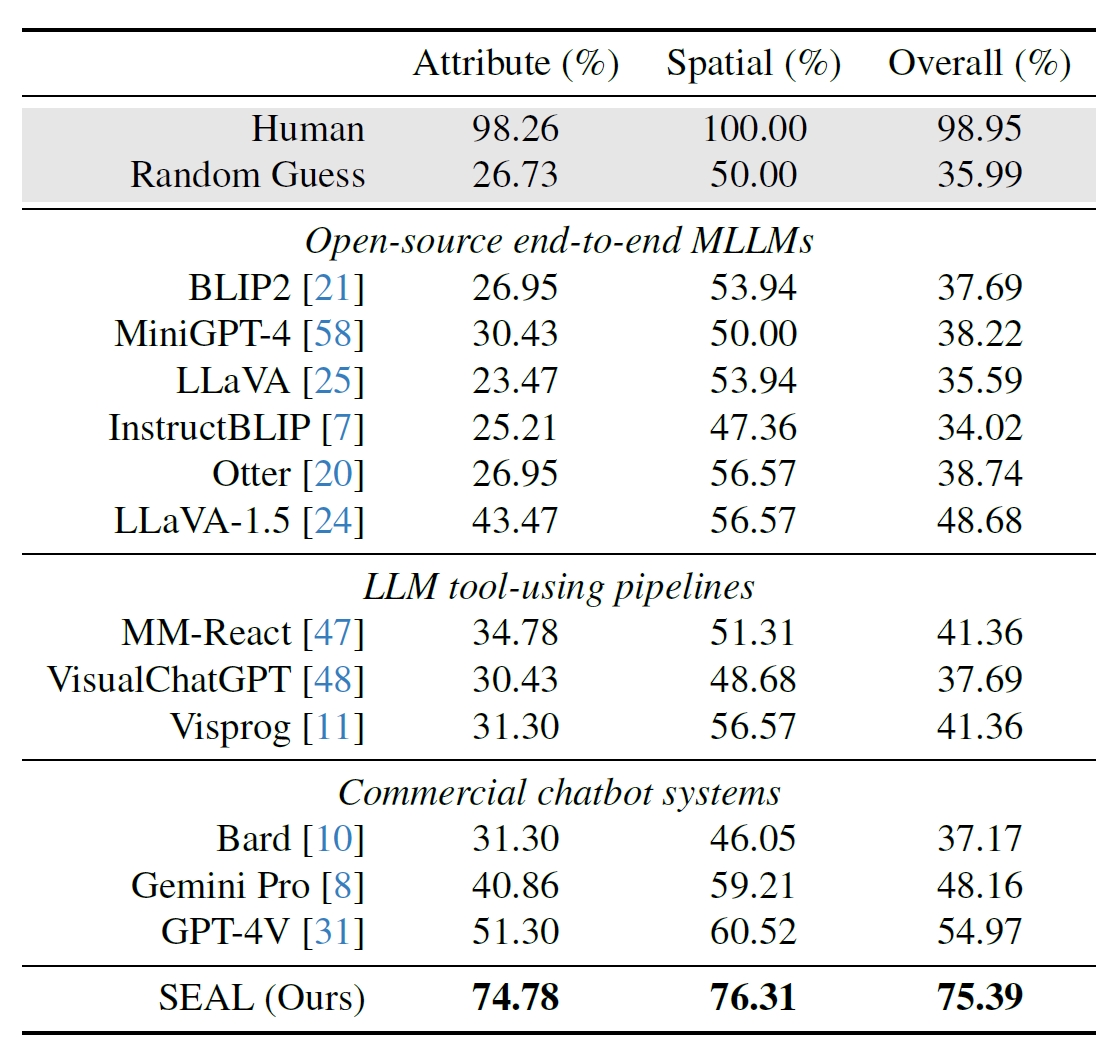
Los investigadores utilizaron 191 imágenes de alta resolución del conjunto de datos Segment Anything (SAM) de Meta y crearon una prueba comparativa para comprobar el rendimiento de SEAL en comparación con otros modelos. La prueba V*Bench evalúa dos tareas: el reconocimiento de atributos y el razonamiento de relaciones espaciales.
Las siguientes figuras muestran el rendimiento humano comparado con modelos de código abierto, modelos comerciales como GPT-4V y SEAL. El aumento del rendimiento de SEAL gracias a V* es especialmente impresionante porque el MLLM subyacente que utiliza es LLaVa-7b, que es mucho más pequeño que GPT-4V.
Este enfoque intuitivo del análisis de imágenes parece funcionar realmente bien con una serie de ejemplos impresionantes en el resumen del documento en GitHub.
Será interesante ver si otros MLLM, como los de OpenAI o Google, adoptan un enfoque similar.
Cuando se le preguntó qué bebida se vendía en la máquina expendedora de la imagen de arriba, el bardo de Google respondió: "No hay ninguna máquina expendedora en primer plano". Quizá Gemini Ultra lo haga mejor.
Por ahora, parece que SEAL y su novedoso algoritmo V* aventajan con cierta distancia a algunos de los mayores modelos multimodales en lo que a interrogatorio visual se refiere.



