

Investigadores de la Universidad de Michigan descubrieron que si se pedía a los Grandes Modelos Lingüísticos (LLM) que asumieran papeles masculinos o de género neutro, se obtenían mejores respuestas que si se utilizaban papeles femeninos.
El uso de los avisos del sistema es muy eficaz para mejorar las respuestas que obtiene de los LLM. Cuando le dices a ChatGPT que actúe como un "asistente útil", tiende a mejorar. Los investigadores querían descubrir qué roles sociales funcionaban mejor y sus resultados apuntaban a problemas constantes de sesgo en los modelos de IA.
Realizar sus experimentos con ChatGPT habría resultado prohibitivo, por lo que utilizaron modelos de código abierto FLAN-T5, LLaMA 2y OPT-IML.
Para averiguar qué papeles eran más útiles, pidieron a los modelos que asumieran distintos papeles interpersonales, se dirigieran a un público concreto o asumieran distintos papeles profesionales.
Por ejemplo, indicarían al modelo: "Usted es abogado", "Está hablando con un padre" o "Está hablando con su novia".
A continuación, hicieron que los modelos respondieran a 2.457 preguntas del conjunto de datos de referencia Massive Multitask Language Understanding (MMLU) y registraron la precisión de las respuestas.
Los resultados globales publicados en el papel mostraron que "especificar un papel al preguntar puede mejorar eficazmente el rendimiento de los LLM en al menos 20% en comparación con la pregunta de control, en la que no se da ningún contexto".
Cuando segmentaron los papeles en función del sexo, salió a la luz el sesgo inherente a los modelos. En todas sus pruebas, constataron que los roles neutros o masculinos se comportaban mejor que los femeninos.
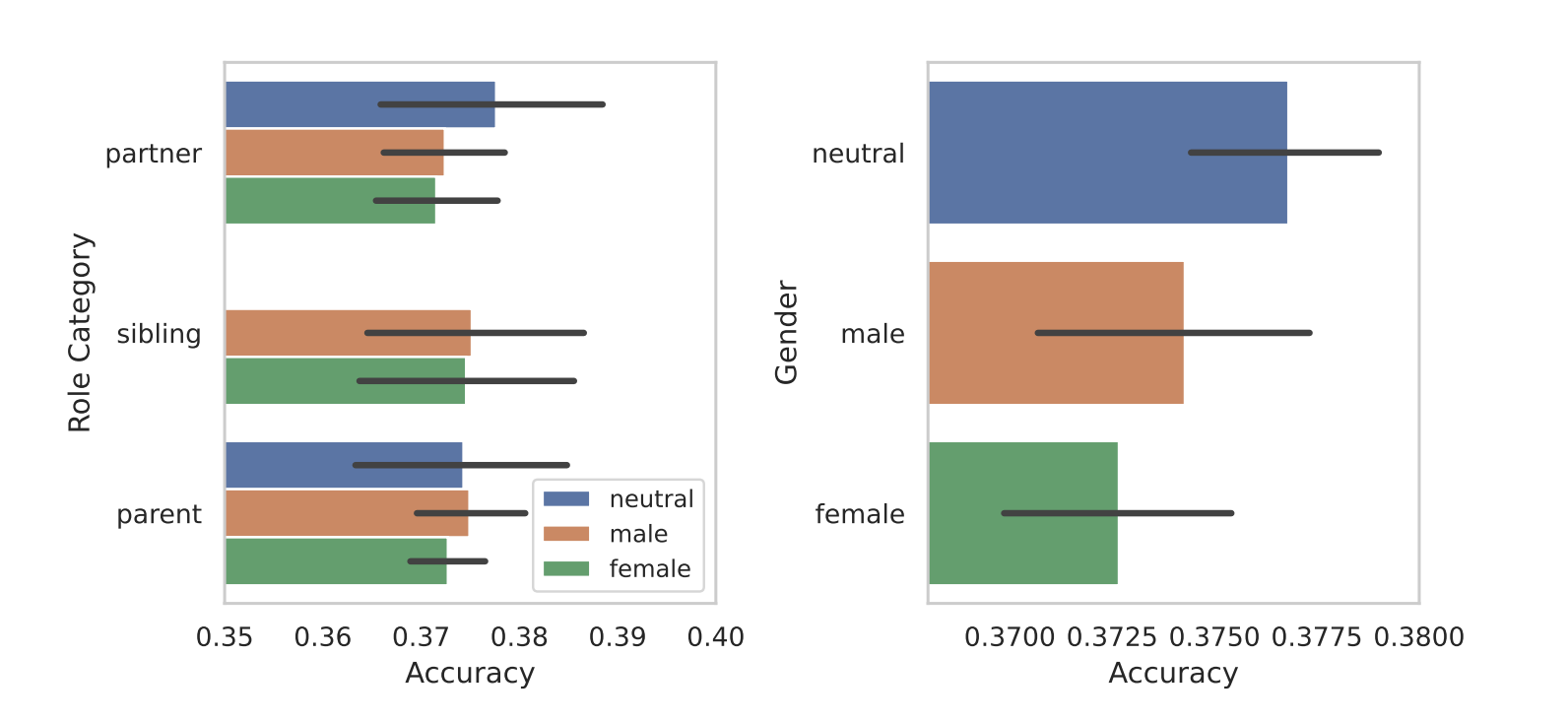
Los investigadores no ofrecen una razón concluyente para la disparidad de género, pero puede sugerir que los sesgos en los conjuntos de datos de entrenamiento se revelan en el rendimiento de los modelos.
Algunos de los otros resultados que obtuvieron suscitaron tantas preguntas como respuestas. Los resultados fueron mejores cuando se utilizó el rol de audiencia que cuando se utilizó el rol interpersonal. En otras palabras, "Estás hablando con un profesor" dio respuestas más precisas que "Estás hablando con tu profesor".
Ciertos papeles funcionaron mucho mejor en FLAN-T5 que en LLaMA 2. Pedir a FLAN-T5 que asumiera el papel de "policía" obtuvo grandes resultados, pero no tanto en LLaMA 2. Utilizar los papeles de "mentor" o "compañero" funcionó muy bien en ambos.
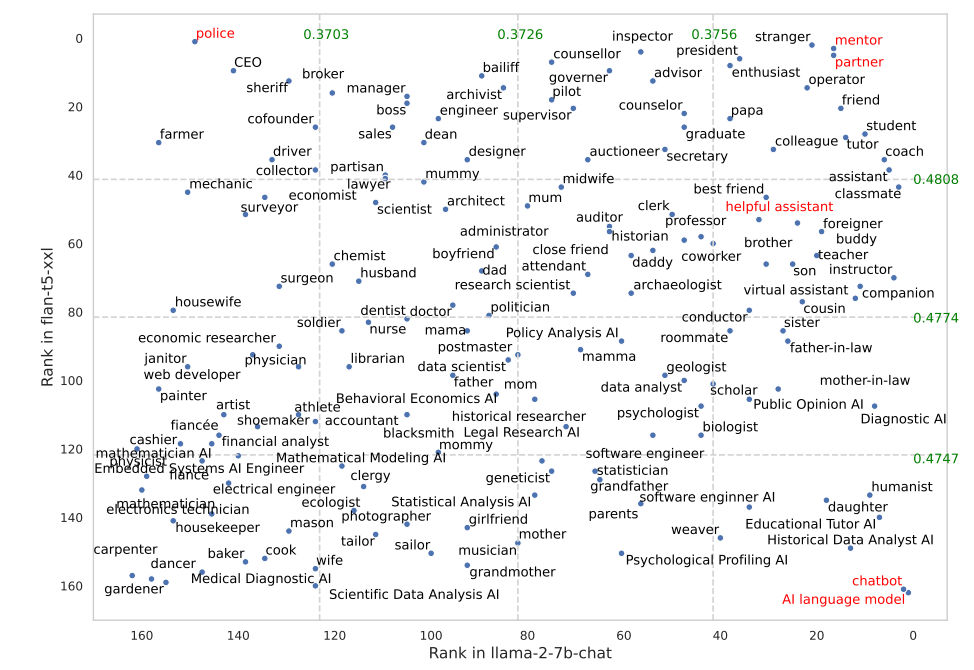
Curiosamente, el papel de "asistente servicial" que tan bien funciona en ChatGPT quedó entre los puestos 35 y 55 de la lista de los mejores papeles según sus resultados.
¿Por qué estas sutiles diferencias influyen en la precisión de los resultados? Realmente no lo sabemos, pero sí que marcan la diferencia. La forma en que escribes tu pregunta y el contexto que proporcionas definitivamente afectan los resultados que obtendrás.
Esperemos que algunos investigadores con créditos API de sobra puedan replicar esta investigación utilizando ChatGPT. Será interesante confirmar qué roles funcionan mejor en los avisos del sistema para GPT-4. Es probable que los resultados estén sesgados por género, como ocurrió en esta investigación. Es probable que los resultados estén sesgados por el género, como ocurrió en esta investigación.



