

Google DeepMind ha lanzado un conjunto de nuevas herramientas para ayudar a los robots a aprender de forma autónoma con mayor rapidez y eficacia en entornos novedosos.
Entrenar a un robot para que realice una tarea específica en un único entorno es una tarea de ingeniería relativamente sencilla. Para que los robots nos sean realmente útiles en el futuro, tendrán que ser capaces de realizar una serie de tareas generales y aprender a hacerlas en entornos que no hayan experimentado antes.
El año pasado DeepMind lanzó su Modelo de control robótico RT-2 y RT-X. RT-2 traduce comandos de voz o texto en acciones robóticas.
Las nuevas herramientas anunciadas por DeepMind se basan en RT-2 y nos acercan a robots autónomos que exploran distintos entornos y aprenden nuevas habilidades.
En los dos últimos años, los modelos de grandes cimientos han demostrado ser capaces de percibir y razonar sobre el mundo que nos rodea, lo que abre una posibilidad clave para escalar la robótica.
Presentamos AutoRT, un marco para orquestar agentes robóticos en la naturaleza utilizando modelos de fundamentos. pic.twitter.com/x3YdO10kqq
- Keerthana Gopalakrishnan (@keerthanpg) 4 de enero de 2024
AutoRT
AutoRT combina un Large Language Model (LLM) fundacional con un Visual Language Model (VLM) y un modelo de control de robots como RT-2.
El VLM permite al robot evaluar la escena que tiene delante y pasar la descripción al LLM. El LLM evalúa los objetos identificados y la escena y, a continuación, genera una lista de tareas potenciales que el robot podría realizar.
Las tareas se evalúan en función de su seguridad, las capacidades del robot y si el intento de la tarea añadiría o no nuevas habilidades o diversidad a la base de conocimientos de AutoRT.
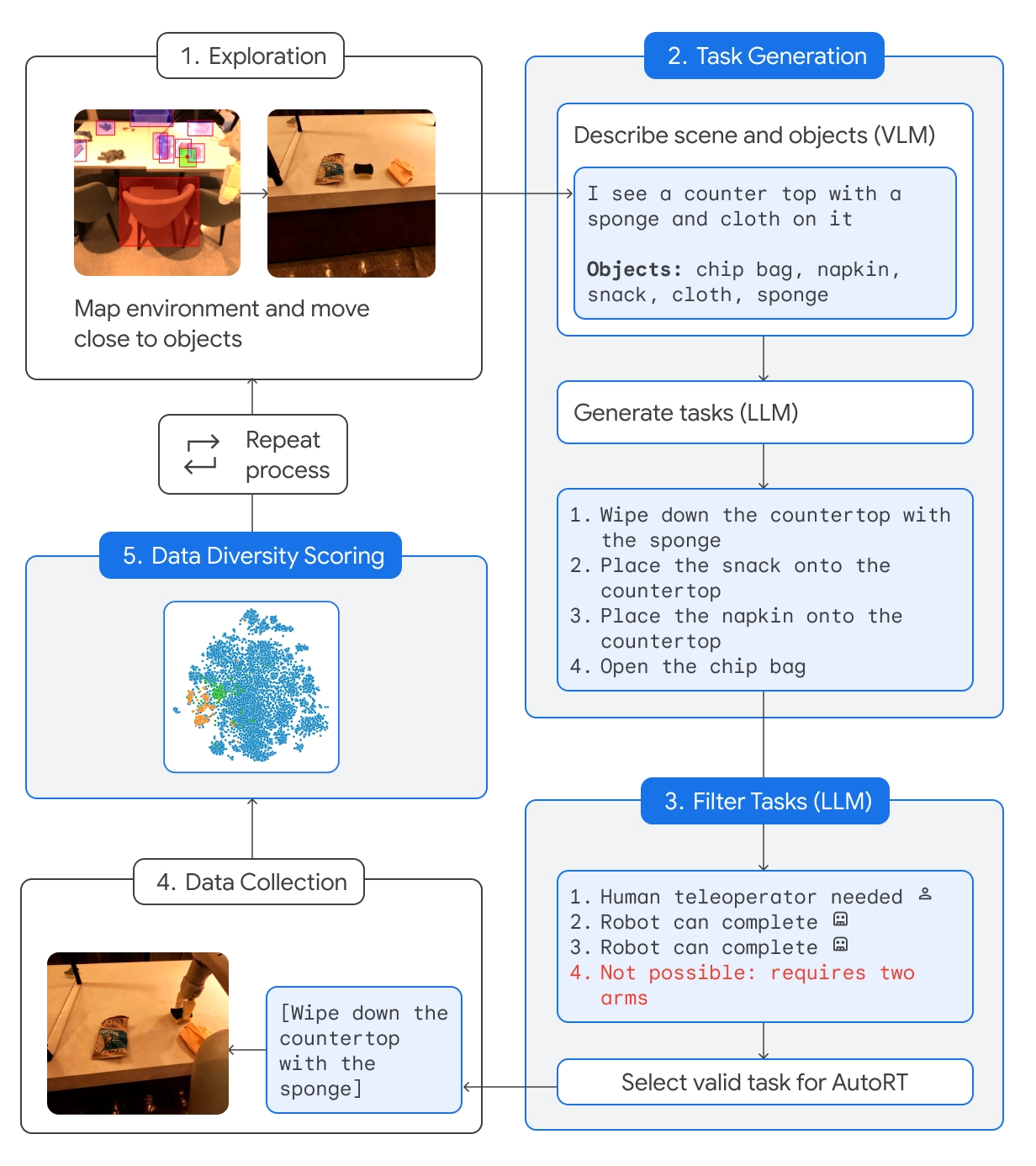
DeepMind afirma que con AutoRT "orquestaron con seguridad hasta 20 robots simultáneamente, y hasta 52 robots únicos en total, en una variedad de edificios de oficinas, recopilando un conjunto de datos diverso que comprende 77.000 ensayos robóticos a través de 6.650 tareas únicas."
Constitución robótica
Enviar un robot a entornos nuevos significa que se encontrará con situaciones potencialmente peligrosas que no pueden planificarse de forma específica. Utilizando una constitución robótica como guía, los robots disponen de barandillas de seguridad generalizadas.
La constitución robótica se inspira en las 3 leyes de la robótica de Isaac Asimov:
- Un robot no puede lesionar a un ser humano.
- Este robot no intentará realizar tareas que impliquen a personas, animales o seres vivos. Este robot no interactuará con objetos afilados, como un cuchillo.
- Este robot sólo tiene un brazo, por lo que no puede realizar tareas que requieran dos brazos. Por ejemplo, no puede abrir una botella.
Seguir estas directrices evita que el robot seleccione una tarea de la lista de opciones que pueda herir a alguien o dañarse a sí mismo o a otra cosa.
SARA-RT
Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT) toma modelos como RT-2 y los hace más eficientes.
La arquitectura de red neuronal de RT-2 se basa en módulos de atención de complejidad cuadrática. Esto significa que si se duplica la entrada, añadiendo un nuevo sensor o aumentando la resolución de la cámara, se necesitan cuatro veces más recursos computacionales.
SARA-RT utiliza un modelo de atención lineal para ajustar el modelo robótico. El resultado es una mejora de 14% en velocidad y 10% en precisión.
RT-Trayectoria
Convertir una tarea sencilla, como limpiar una mesa, en instrucciones que pueda seguir un robot es complicado. Hay que convertir la tarea de lenguaje natural a una secuencia codificada de movimientos y rotaciones del motor para accionar las piezas móviles del robot.
RT-Trajectory añade una superposición visual 2D a un vídeo de entrenamiento para que el robot pueda aprender intuitivamente qué tipo de movimiento es necesario para realizar la tarea.
Así, en lugar de pedirle al robot que "limpie la mesa", la demostración y la superposición de movimientos le dan más posibilidades de aprender rápidamente la nueva habilidad.
DeepMind dice que un brazo controlado por RT-Trajectory "logró una tasa de éxito en la tarea de 63%, en comparación con 29% para RT-2".
🔵 También puede crear trayectorias observando demostraciones humanas, entendiendo bocetos e incluso dibujos generados por VLM.
Cuando se probó en 41 tareas no vistas en los datos de entrenamiento, un brazo controlado por RT-Trajectory alcanzó una tasa de éxito de 63%. https://t.co/rqOnzDDMDI pic.twitter.com/bdhi9W5TWi
- Google DeepMind (@GoogleDeepMind) 4 de enero de 2024
DeepMind pone estos modelos y conjuntos de datos a disposición de otros desarrolladores, por lo que será interesante ver cómo estas nuevas herramientas aceleran la integración de los robots impulsados por IA en la vida cotidiana.



