

Los grandes modelos lingüísticos (LLM) a menudo se dejan engañar por los prejuicios o el contexto irrelevante de una pregunta. Los investigadores de Meta han encontrado una forma aparentemente sencilla de solucionarlo.
A medida que aumentan las ventanas de contexto, las instrucciones que introducimos en un LLM pueden hacerse más largas y detalladas. Los LLM son cada vez más capaces de captar los matices o pequeños detalles de nuestras indicaciones, pero a veces esto puede confundirlos.
Los primeros sistemas de aprendizaje automático utilizaban un enfoque de "atención dura" que seleccionaba la parte más relevante de una entrada y respondía sólo a ella. Esto funciona bien cuando se trata de subtitular una imagen, pero mal cuando se traduce una frase o se responde a una pregunta con varias capas.
La mayoría de los LLM utilizan ahora un enfoque de "atención suave" que tokeniza toda la pregunta y asigna pesos a cada una de ellas.
Meta propone un enfoque denominado Sistema 2 Atención (S2A) para obtener lo mejor de ambos mundos. S2A utiliza la capacidad de procesamiento del lenguaje natural de un LLM para tomar su solicitud y eliminar los sesgos y la información irrelevante antes de empezar a trabajar en una respuesta.
He aquí un ejemplo.

S2A se deshace de la información relativa a Max, ya que es irrelevante para la pregunta. S2A regenera una pregunta optimizada antes de empezar a trabajar en ella. Los LLM son notoriamente malos en matemáticas por lo que hacer el aviso menos confuso es de gran ayuda.
A los LLM les gusta complacer a la gente y están encantados de estar de acuerdo contigo, incluso cuando estás equivocado. S2A elimina cualquier sesgo en una pregunta y sólo procesa las partes relevantes de la misma. Esto reduce lo que los investigadores de IA llaman "adulancia", o la propensión de un modelo de IA a besar culos.

En realidad, S2A no es más que un sistema que indica al LLM que perfeccione un poco la pregunta original antes de ponerse a trabajar en ella. Los resultados que obtuvieron los investigadores con preguntas matemáticas, objetivas y largas fueron impresionantes.
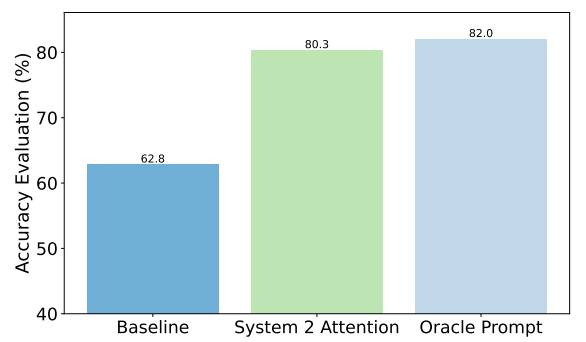
A modo de ejemplo, he aquí las mejoras conseguidas por S2A en las preguntas sobre hechos. La línea de base eran las respuestas a preguntas que contenían sesgos, mientras que la indicación de Oracle era una indicación ideal refinada por humanos.
S2A se acerca mucho a los resultados de Oracle y mejora la precisión en casi 50% con respecto a la línea de base.
¿Cuál es el problema? El preprocesamiento de la pregunta original antes de responderla añade requisitos de cálculo adicionales al proceso. Si la pregunta es larga y contiene mucha información relevante, regenerarla puede suponer un coste considerable.
Es poco probable que los usuarios mejoren escribiendo prompts bien elaborados, por lo que S2A puede ser una buena forma de evitarlo.
¿Incorporará Meta S2A a su Llama modelo? No lo sabemos, pero usted mismo puede aprovechar el enfoque S2A.
Si tienes cuidado de omitir las opiniones o las sugerencias de tus preguntas, es más probable que obtengas respuestas precisas de estos modelos.



