

Elon Musk anunció el lanzamiento beta del chatbot de xAI llamado Grok y las estadísticas iniciales nos dan una idea de cómo se compara con otros modelos.
En Chatbot Grok se basa en el modelo de frontera de xAI llamado Grok-1, que la empresa ha desarrollado durante los últimos cuatro meses. xAI no ha dicho con cuántos parámetros se ha entrenado, pero sí ha dado algunas cifras de su predecesor.
Grok-0, el prototipo del modelo actual, se entrenó con 33.000 millones de parámetros, por lo que podemos suponer que Grok-1 se entrenó con al menos otros tantos.
No parece mucho, pero xAI afirma que el rendimiento de Grok-0 "se aproxima a las capacidades de LLaMA 2 (70B) en pruebas de referencia LM estándar" a pesar de haber utilizado la mitad de los recursos de entrenamiento.
A falta de una cifra de parámetros, tenemos que fiarnos de la palabra de la empresa cuando describe Grok-1 como "de última generación" y que es "significativamente más potente" que Grok-0.
Grok-1 se puso a prueba evaluándolo con estas pruebas estándar de aprendizaje automático:
- GSM8k: Middle school math word problems
- MMLU: Preguntas multidisciplinares de respuesta múltiple
- HumanEval: tarea de finalización de código Python
- MATH: Problemas de matemáticas de secundaria y bachillerato escritos en LaTeX
He aquí un resumen de los resultados.
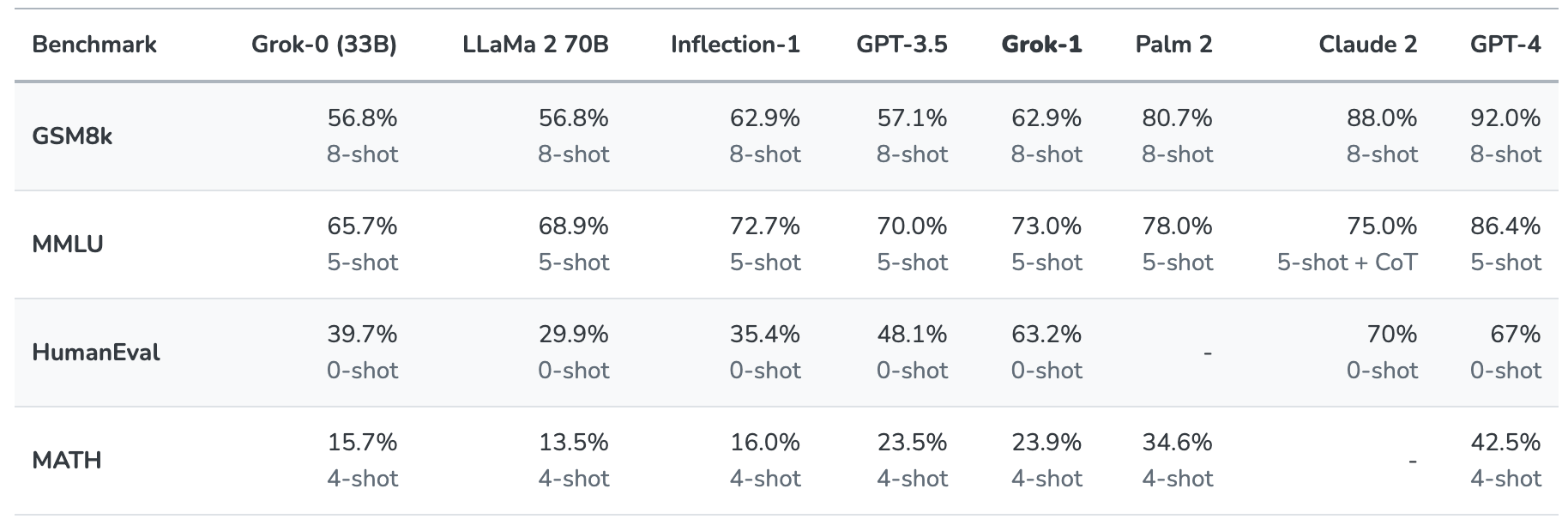
Los resultados son interesantes porque nos dan al menos una idea de cómo se compara Grok con otros modelos de frontera.
xAI afirma que estas cifras demuestran que Grok-1 supera a "todos los demás modelos de su clase de computación" y sólo fue superado por modelos entrenados con una "cantidad significativamente mayor de datos de entrenamiento y recursos de computación".
GPT-3.5 tiene 175.000 millones de parámetros, por lo que podemos suponer que Grok-1 tiene menos que eso, pero probablemente más que los 33.000 millones de su prototipo.
El chatbot Grok está pensado para procesar tareas como la respuesta a preguntas, la recuperación de información, la escritura creativa y la asistencia en codificación. Es más probable que se utilice para interacciones más breves que para casos de uso superpuntual debido a su ventana contextual más pequeña.
Con una longitud de contexto de 8.192, Grok-1 sólo tiene la mitad de contexto que GPT-3.5. Esto es un indicio de que xAI probablemente pretendía que Grok-1 ofreciera un contexto más largo a cambio de una mayor eficiencia. Esto indica que xAI probablemente pretendía que Grok-1 ofreciera un contexto más largo a cambio de una mayor eficiencia.
La empresa afirma que algunas de sus investigaciones actuales se centran en la "comprensión y recuperación de contextos largos", por lo que es muy posible que la próxima versión de Grok tenga una ventana de contexto más amplia.
El conjunto de datos exacto que se utilizó para entrenar a Grok-1 no está claro, pero casi seguro que incluía tus tweets en X, y el chatbot Grok también tiene acceso a Internet en tiempo real.
Tendremos que esperar a recibir más comentarios de los usuarios de la versión beta para hacernos una idea real de la calidad del modelo.
¿Nos ayudará Grok a desentrañar los misterios de la vida, el universo y todo lo demás? Quizá todavía no, pero es un comienzo entretenido.



