

Los investigadores han presentado FANToM, una nueva prueba de referencia diseñada para comprobar y evaluar con rigor la comprensión y aplicación de la Teoría de la Mente (ToM) por parte de los grandes modelos lingüísticos (LLM).
La teoría de la mente se refiere a la capacidad de atribuir creencias, deseos y conocimientos a uno mismo y a los demás, y de comprender que los demás tienen creencias y perspectivas diferentes de las propias.
La ToM se considera fundamental para la conciencia de los animales inteligentes. Además de los humanos, se considera que primates como los orangutanes, los gorilas y los chimpancés tienen ToM, al igual que algunos no primates como los loros y los miembros de la familia de los córvidos.
A medida que los modelos de IA se hacen más complejos, los investigadores buscan nuevos métodos para evaluar capacidades como la ToM.
Un nuevo punto de referencia llamado FANToMcreado por investigadores del Allen Institute for AI, la Universidad de Washington, la Universidad Carnegie Mellon y la Universidad Nacional de Seúl, somete modelos de aprendizaje automático a escenarios dinámicos que reflejan interacciones de la vida real.
Con FANToM, los personajes entran y salen de las conversaciones, lo que desafía a los modelos de IA a mantener un conocimiento preciso de quién sabe qué en cada momento.
La aplicación de FANToM a grandes modelos lingüísticos (LLM) reveló que incluso los modelos más avanzados tienen dificultades para mantener una ToM coherente.
El rendimiento de los modelos fue significativamente inferior al de los participantes humanos, lo que pone de manifiesto las limitaciones de la IA para comprender y navegar por interacciones sociales complejas.
De hecho, los humanos dominaron todas las categorías, como se ve a continuación.
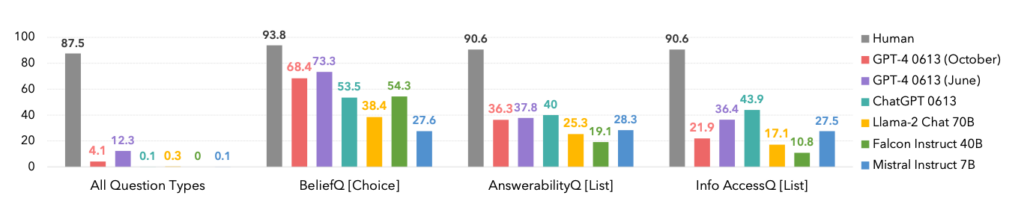
Un dato interesante es que la versión de octubre de la iteración del modelo GPT-4 fue superada por una anterior de junio, lo que podría respaldar las recientes anécdotas entre los usuarios de que ChatGPT está empeorando.
FANToM también reveló técnicas para mejorar la ToM de LLM, como el razonamiento en cadena y otros métodos de ajuste.
Sin embargo, la brecha entre la inteligencia artificial y las competencias humanas en ToM sigue siendo grande.
La IA avanza hacia un lenguaje similar al humano
En un asunto relacionado pero distinto estudio publicado en NatureLos científicos desarrollaron una red neuronal capaz de generalizar el lenguaje como los humanos.
Esta nueva red neuronal mostró una impresionante capacidad para integrar palabras recién aprendidas en su vocabulario. A continuación, podía utilizar esas palabras en diversos contextos, una habilidad cognitiva conocida como generalización sistemática.
Los seres humanos muestran de forma natural una generalización sistemática, incorporando sin problemas nuevo vocabulario a su repertorio.
Por ejemplo, una vez que alguien aprende el término "photobomb", puede aplicarlo en diversas situaciones casi de inmediato. La jerga aparece constantemente y el ser humano la incorpora a su vocabulario de forma natural.
Los investigadores sometieron tanto su red neuronal personalizada como ChatGPT a una serie de pruebas y descubrieron que ChatGPT iba por detrás del modelo personalizado en cuanto a rendimiento.
Mientras que los LLM como ChatGPT destacan en muchos escenarios conversacionales, muestran notables incoherencias y lagunas en otros, un problema que aborda esta nueva red neuronal.
Para investigar este aspecto de la comunicación lingüística, los investigadores realizaron un experimento con 25 participantes humanos, en el que evaluaron su capacidad para aplicar palabras recién aprendidas en distintos contextos. Se presentó a los sujetos un pseudolenguaje compuesto por palabras sin sentido que representaban diversas acciones y reglas.
Tras una fase de entrenamiento, los participantes destacaron en la aplicación de estas reglas abstractas a situaciones nuevas, mostrando una generalización sistemática.
Cuando la red neuronal recién desarrollada fue expuesta a esta tarea, reflejó el rendimiento humano. Sin embargo, cuando se sometió a ChatGPT al mismo reto, tuvo dificultades significativas, fallando entre el 42 y el 86% de las veces, dependiendo de la tarea específica.
Esto es significativo por dos razones. En primer lugar, se podría argumentar que esta nueva red neuronal superó con eficacia a GPT-4 en esta tarea específica, lo cual ya es bastante impresionante. En segundo lugar, este estudio expone nuevos métodos para enseñar a los modelos de IA a generalizar nuevos lenguajes como los humanos.
Como describe Elia Bruni, especialista en procesamiento del lenguaje natural de la Universidad de Osnabrück (Alemania), "infundir sistematicidad a las redes neuronales es un gran reto".
Juntos, estos dos estudios ofrecen nuevos enfoques para entrenar modelos de IA más inteligentes que puedan rivalizar con los humanos en áreas críticas como la lingüística y la teoría de la mente.



