

Der Gründer und CEO von HyperWrite, Matt Shumer, gab bekannt, dass sein neues Modell, Reflection 70B, mit einem einfachen Trick LLM-Halluzinationen löst und beeindruckende Benchmark-Ergebnisse liefert, die größere und sogar geschlossene Modelle wie GPT-4o schlagen.
Shumer arbeitete mit dem Anbieter synthetischer Daten, Glaive, zusammen, um das neue Modell zu erstellen, das auf dem Llama 3.1-70B Instruct Modell von Meta basiert.
In der Ankündigung zum Start auf Hugging Face sagte Shumer. "Reflection Llama-3.1 70B ist (derzeit) das weltweit beste Open-Source-LLM, trainiert mit einer neuen Technik namens Reflection-Tuning, die einem LLM beibringt, Fehler in seiner Argumentation zu erkennen und den Kurs zu korrigieren."
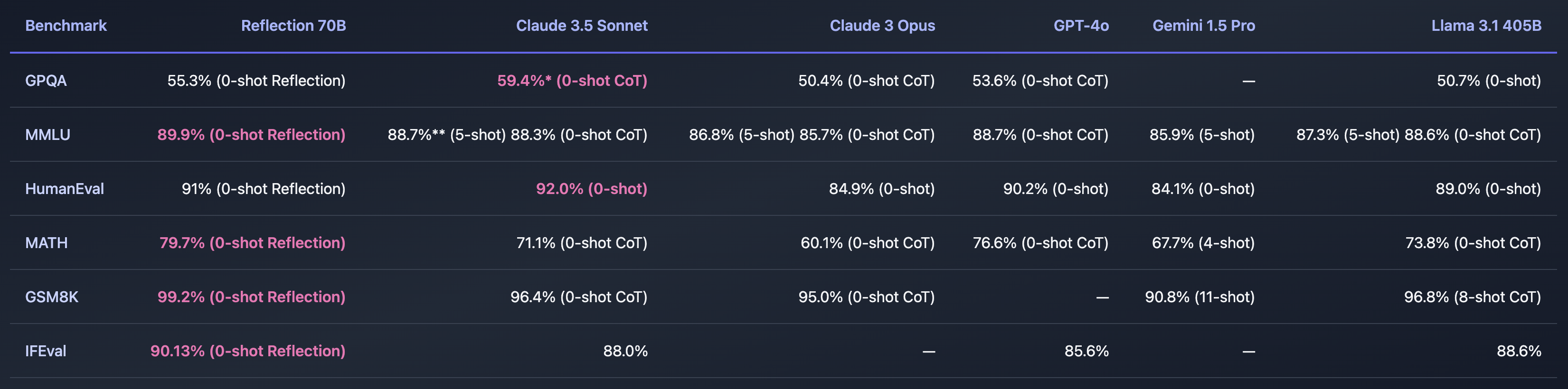
Wenn Shumer einen Weg gefunden hat, das Problem der KI-Halluzinationen zu lösen, dann wäre das unglaublich. Die Benchmarks, die er mitgeteilt hat, scheinen darauf hinzudeuten, dass Reflection 70B anderen Modellen weit voraus ist.
Der Name des Modells ist eine Anspielung auf seine Fähigkeit zur Selbstkorrektur während der Schlussfolgerung. Shumer verrät nicht zu viel, erklärt aber, dass das Modell über seine ursprüngliche Antwort auf eine Aufforderung nachdenkt und sie erst dann ausgibt, wenn es überzeugt ist, dass sie richtig ist.
Shumer sagt, dass eine 405B-Version des Reflection in Arbeit ist und andere Modelle, einschließlich des GPT-4o, in den Schatten stellen wird, wenn sie nächste Woche vorgestellt wird.
Ist Reflection 70B ein Betrug?
Ist das alles zu schön, um wahr zu sein? Reflection 70B kann bei Huging Face heruntergeladen werden, aber die ersten Tester waren nicht in der Lage, die beeindruckende Leistung, die Shumers Benchmarks zeigten, zu wiederholen.
Die Reflexionsspielplatz lässt Sie das Modell ausprobieren, sagt aber, dass die Demo wegen der hohen Nachfrage vorübergehend nicht verfügbar ist. Die Vorschläge "Zähle 'r's in Erdbeere" und "9,11 vs. 9,9" deuten darauf hin, dass das Modell diese kniffligen Fragen richtig beantwortet. Einige Benutzer behaupten jedoch, dass Reflection speziell für die Beantwortung dieser Aufforderungen optimiert wurde.
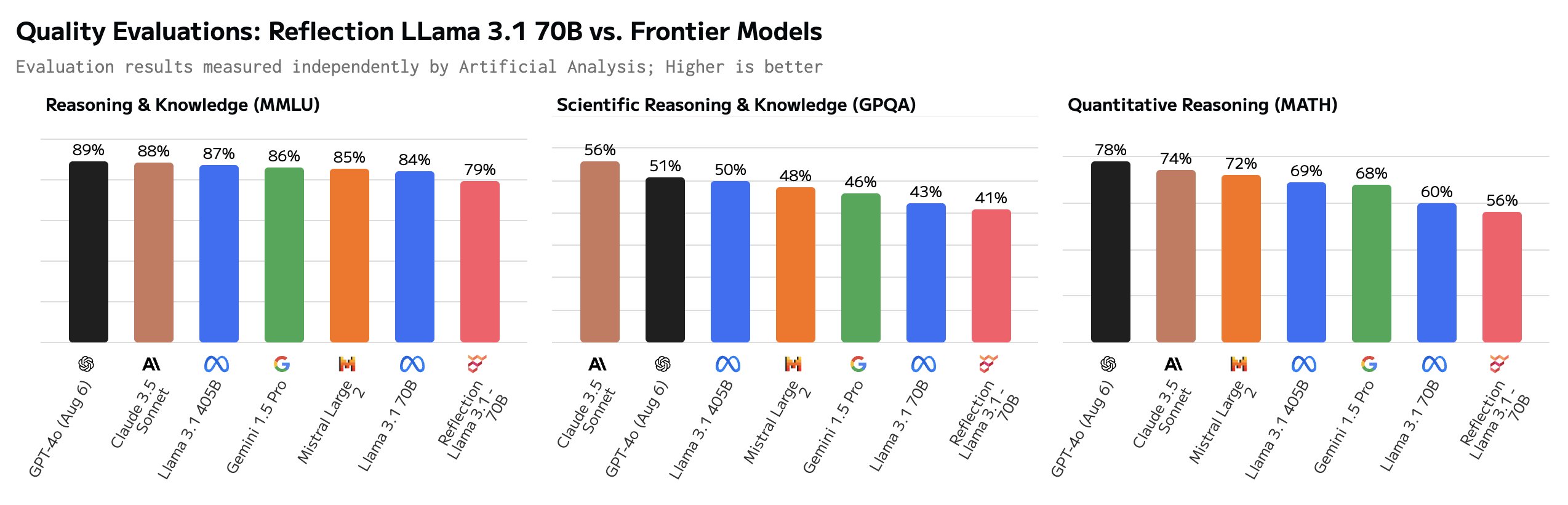
Einige Nutzer stellten die beeindruckenden Benchmarks in Frage. Der GSM8K von über 99% sah besonders verdächtig aus.
Hallo Matt! Das ist super interessant, aber ich bin ziemlich überrascht, ein GSM8k Ergebnis von über 99% zu sehen. Nach meinem Verständnis ist es wahrscheinlich, dass mehr als 1% von GSM8k falsch beschriftet sind (die richtige Antwort ist tatsächlich falsch)!
- Hugh Zhang (@hughbzhang) 5. September 2024
Einige der richtigen Antworten im GSM8K-Datensatz sind tatsächlich falsch. Mit anderen Worten: Die einzige Möglichkeit, bei GSM8K mehr als 99% zu erreichen, bestand darin, die gleichen falschen Antworten auf diese Aufgaben zu geben.
Nach einigen Tests sagen Benutzer, dass Reflection tatsächlich schlechter ist als Llama 3.1 und dass es eigentlich nur Llama 3 mit LoRA-Tuning war.
Als Reaktion auf das negative Feedback postete Shumer eine Erklärung auf X: "Schnelles Update - wir haben die Gewichte neu hochgeladen, aber es gibt immer noch ein Problem. Wir haben gerade wieder mit dem Training begonnen, um alle möglichen Probleme zu beseitigen. Sollte bald fertig sein."
Shumer erklärte, dass es einen Fehler in der API gebe und dass man daran arbeite. In der Zwischenzeit gewährte er Zugang zu einer geheimen, privaten API, damit Zweifler Reflection ausprobieren konnten, während sie an der Behebung arbeiteten.
Und genau hier scheinen sich die Räder zu lösen, denn eine vorsichtige Nachfrage scheint zu zeigen, dass die API in Wirklichkeit nur eine Claude 3.5 Sonnet-Verpackung ist.
"Reflection API" ist ein Sonnet 3.5 Wrapper mit Prompt. Und sie tarnen es derzeit, indem sie die Zeichenfolge "claude" herausfiltern.https://t.co/c4Oj8Y3Ol1 https://t.co/k0ECeo9a4i pic.twitter.com/jTm2Q85Q7b
- Joseph (@RealJosephus) 8. September 2024
Nachfolgende Tests ergaben, dass die API Ausgaben von Llama und GPT-4o lieferte. Shumer besteht darauf, dass die ursprünglichen Ergebnisse korrekt sind und dass man daran arbeitet, das herunterladbare Modell zu verbessern.
Sind die Skeptiker ein wenig voreilig, wenn sie Shumer einen Betrüger nennen? Vielleicht wurde die Veröffentlichung nur schlecht gehandhabt und Reflection 70B ist wirklich ein bahnbrechendes Open-Source-Modell. Oder vielleicht ist es ein weiteres Beispiel für einen KI-Hype, um Risikokapital von Investoren zu erhalten, die auf der Suche nach dem nächsten großen Ding der KI sind.
Wir müssen noch ein oder zwei Tage abwarten, um zu sehen, wie sich das entwickelt.



