

Benchmarks haben Schwierigkeiten, mit den fortschreitenden Fähigkeiten von KI-Modellen Schritt zu halten, und das Projekt "Humanity's Last Exam" bittet um Ihre Hilfe, um dies zu ändern.
Das Projekt ist eine Zusammenarbeit zwischen dem Center for AI Safety (CAIS) und dem KI-Datenunternehmen Scale AI. Das Projekt zielt darauf ab, zu messen, wie nah wir an der Entwicklung von KI-Systemen auf Expertenniveau sind, etwas bestehende Benchmarks zu denen sie nicht fähig sind.
OpenAI und CAIS entwickelten den beliebten MMLU-Benchmark (Massive Multitask Language Understanding) im Jahr 2021. Damals, so CAIS, "schnitten KI-Systeme nicht besser ab als der Zufall".
Die beeindruckende Leistung des o1-Modells von OpenAI hat laut Dan Hendrycks, Geschäftsführer des CAIS, "die populärsten Benchmarks für logisches Denken zerstört".
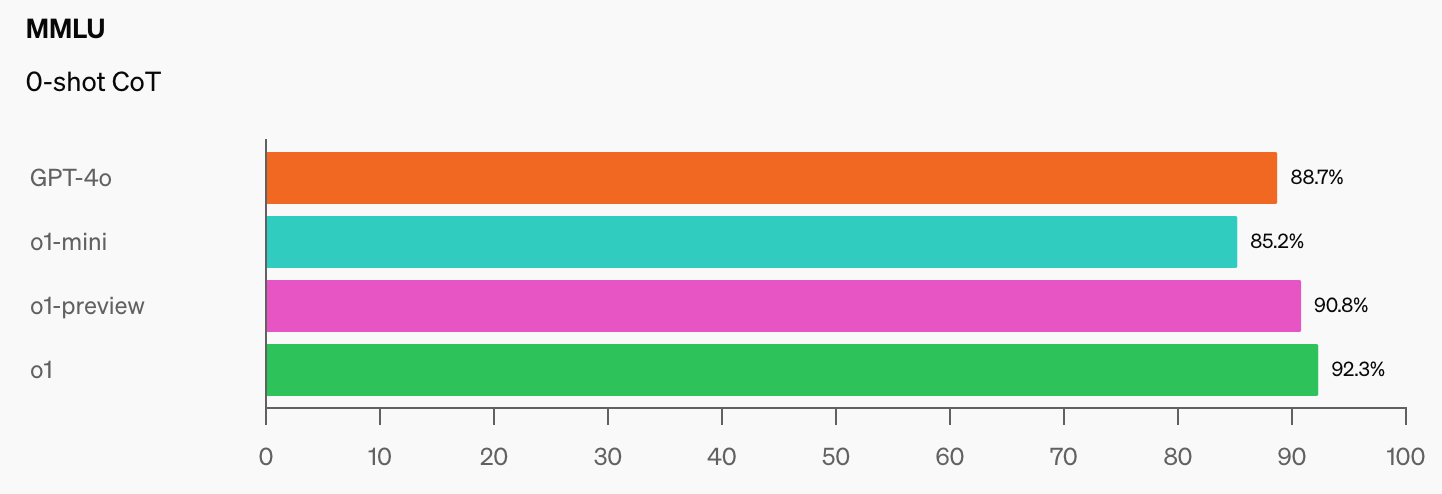
Wie werden wir KI-Modelle messen, wenn sie 100% auf der MMLU erreichen? Das CAIS sagt: "Die bestehenden Tests sind zu einfach geworden, und wir können die Entwicklung der KI nicht mehr gut verfolgen und auch nicht, wie weit sie davon entfernt ist, Experten zu werden."
Wenn Sie den Sprung in den Benchmark-Ergebnissen sehen, den o1 zu den bereits beeindruckenden GPT-4o-Zahlen hinzugefügt hat, wird es nicht lange dauern, bis ein KI-Modell die MMLU übertrifft.
Das ist objektiv wahr. pic.twitter.com/gorahh86ee
- Ethan Mollick (@emollick) 17. September 2024
Humanity's Last Exam bittet die Menschen, Fragen einzureichen, die Sie wirklich überraschen würden, wenn ein KI-Modell die richtige Antwort liefern würde. Sie wollen Prüfungsfragen auf PhD-Niveau, nicht die Art von "Wie viele Rs sind in Erdbeere", die einige Modelle zum Stolpern bringen.
Scale erklärte: "Wenn die bestehenden Tests zu einfach werden, verlieren wir die Fähigkeit, zwischen KI-Systemen zu unterscheiden, die in Prüfungen bestehen können, und solchen, die wirklich zur Pionierforschung und Problemlösung beitragen können."
Wenn Sie eine originelle Frage haben, die ein hochentwickeltes KI-Modell überraschen könnte, könnten Sie als Mitautor des Projektpapiers genannt werden und an einem Pool von $500.000 beteiligt werden, der für die besten Fragen vergeben wird.
Um Ihnen eine Vorstellung von dem Niveau zu geben, auf das das Projekt abzielt, erklärte Scale, dass "wenn ein zufällig ausgewählter Student verstehen kann, was gefragt wird, ist es wahrscheinlich zu einfach für die heutigen und zukünftigen Studenten der Rechtswissenschaften an der Grenze".
Es gibt einige interessante Einschränkungen hinsichtlich der Art der Fragen, die eingereicht werden können. Sie wollen keine Fragen zu chemischen, biologischen, radiologischen oder nuklearen Waffen oder zu Cyberwaffen, die für Angriffe auf kritische Infrastrukturen eingesetzt werden.
Wenn Sie glauben, eine Frage zu haben, die den Anforderungen entspricht, können Sie sie einreichen hier.



