

Google DeepMind-Forscher haben NATURAL PLAN entwickelt, einen Benchmark zur Bewertung der Fähigkeit von LLMs, reale Aufgaben auf der Grundlage von natürlichsprachlichen Aufforderungen zu planen.
Die nächste Evolutionsstufe der KI besteht darin, dass sie die Grenzen einer Chat-Plattform verlässt und die Rolle eines Agenten übernimmt, um plattformübergreifende Aufgaben in unserem Namen zu erledigen. Aber das ist schwieriger, als es klingt.
Planungsaufgaben wie das Ansetzen einer Besprechung oder das Zusammenstellen einer Urlaubsroute mögen uns einfach erscheinen. Wir Menschen sind gut darin, mehrere Schritte zu durchdenken und vorherzusagen, ob eine bestimmte Vorgehensweise zum gewünschten Ziel führt oder nicht.
Das mag Ihnen leicht fallen, aber selbst die besten KI-Modelle haben Probleme mit der Planung. Könnten wir sie vergleichen, um zu sehen, welches LLM am besten planen kann?
Der NATURAL PLAN-Benchmark testet LLMs auf 3 Planungsaufgaben:
- Planung der Reise - Planung einer Reiseroute unter Berücksichtigung von Flug- und Zielortbeschränkungen
- Planung von Sitzungen - Planung von Treffen mit mehreren Freunden an verschiedenen Orten
- Kalenderplanung - Planung von Arbeitssitzungen zwischen mehreren Personen unter Berücksichtigung bestehender Zeitpläne und verschiedener Sachzwänge
Das Experiment begann mit einem "few-shot prompting", bei dem den Modellen 5 Beispiele für Aufforderungen und die entsprechenden richtigen Antworten vorgelegt wurden. Anschließend wurden sie mit Planungsaufforderungen unterschiedlicher Schwierigkeit konfrontiert.
Hier ist ein Beispiel für eine Aufforderung und eine Lösung, die den Modellen als Beispiel zur Verfügung gestellt wird:

Ergebnisse
Die Forscher testeten GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash, und Gemini 1.5 Profidie bei diesen Tests nicht sehr gut abgeschnitten haben.
Die Ergebnisse müssen im DeepMind-Büro gut angekommen sein, denn Gemini 1.5 Pro hat sich als Sieger durchgesetzt.

Wie erwartet, verschlechterten sich die Ergebnisse exponentiell mit komplexeren Aufforderungen, bei denen die Anzahl der Personen oder Städte erhöht wurde. Schauen Sie sich zum Beispiel an, wie schnell die Genauigkeit abnahm, als mehr Personen in den Test zur Planung eines Meetings einbezogen wurden.
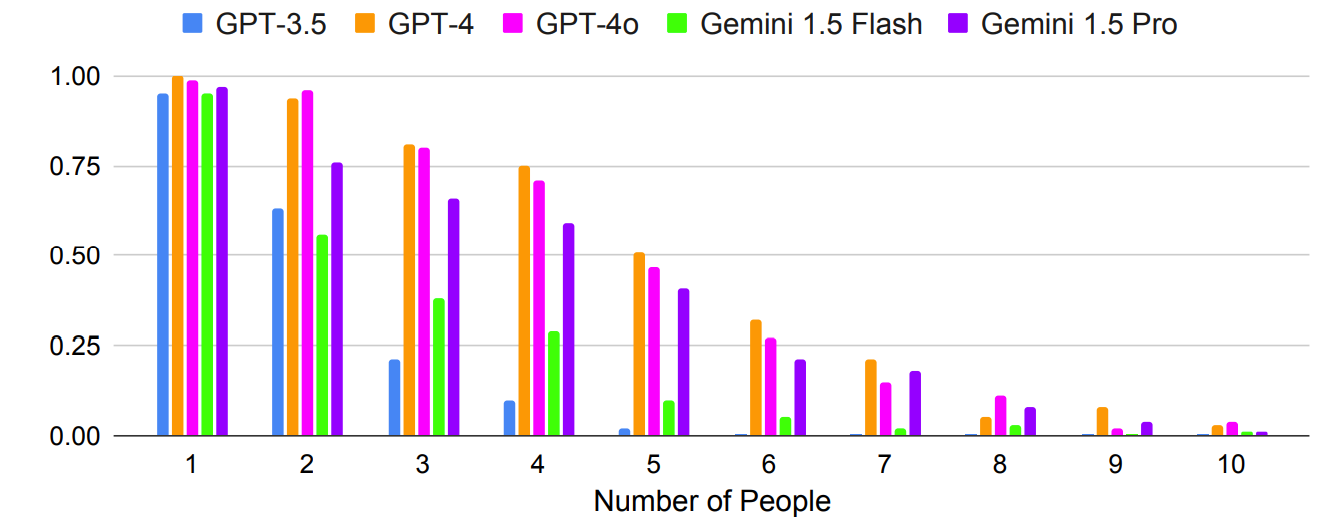
Könnte das Prompting mit mehreren Schüssen zu einer verbesserten Genauigkeit führen? Die Forschungsergebnisse deuten darauf hin, dass dies möglich ist, allerdings nur, wenn das Modell ein ausreichend großes Kontextfenster hat.
Das größere Kontextfenster von Gemini 1.5 Pro ermöglicht es, mehr In-Context-Beispiele zu nutzen als die GPT-Modelle.
Die Forscher fanden heraus, dass bei der Reiseplanung eine Erhöhung der Anzahl der Schüsse von 1 auf 800 die Genauigkeit von Gemini Pro 1.5 von 2,7% auf 39,9% verbessert.
Das Papier "Diese Ergebnisse zeigen, wie vielversprechend die kontextinterne Planung ist, bei der die LLMs dank der Langkontext-Fähigkeiten weitere Kontexte nutzen können, um die Planung zu verbessern."
Ein seltsames Ergebnis war, dass GPT-4o bei der Reiseplanung wirklich schlecht war. Die Forscher stellten fest, dass es Schwierigkeiten hatte, "die Flugverbindungen und Reisedaten zu verstehen und zu berücksichtigen".
Ein weiteres merkwürdiges Ergebnis war, dass die Selbstkorrektur bei allen Modellen zu einem deutlichen Leistungsabfall führte. Wenn die Modelle aufgefordert wurden, ihre Arbeit zu überprüfen und zu korrigieren, machten sie mehr Fehler.
Interessanterweise erlitten die stärkeren Modelle, wie GPT-4 und Gemini 1.5 Pro, bei der Selbstkorrektur größere Verluste als GPT-3.5.
Agentische KI ist eine spannende Perspektive, und wir sehen bereits einige praktische Anwendungsfälle in Microsoft Copilot Agenten.
Die Ergebnisse der NATURAL PLAN-Benchmark-Tests zeigen jedoch, dass wir noch einen weiten Weg vor uns haben, bevor KI komplexere Planungen durchführen kann.
Die DeepMind-Forscher kamen zu dem Schluss, dass "NATURAL PLAN für moderne Modelle sehr schwer zu lösen ist."
Es scheint, dass KI Reisebüros und persönliche Assistenten noch nicht ersetzen wird.



