

Die Stanford University hat ihren AI Index Report 2024 veröffentlicht, in dem festgestellt wird, dass die rasanten Fortschritte der KI Vergleiche mit dem Menschen immer weniger relevant machen.
Die Jahresbericht bietet einen umfassenden Einblick in die Trends und den Stand der KI-Entwicklungen. Der Bericht besagt, dass sich KI-Modelle inzwischen so schnell verbessern, dass die Benchmarks, mit denen wir sie messen, zunehmend irrelevant werden.
In vielen Benchmarks der Industrie werden KI-Modelle damit verglichen, wie gut Menschen bei der Ausführung von Aufgaben sind. Der Massive Multitask Language Understanding (MMLU)-Benchmark ist ein gutes Beispiel dafür.
Anhand von Multiple-Choice-Fragen werden LLMs in 57 Fächern bewertet, darunter Mathematik, Geschichte, Recht und Ethik. Der MMLU ist seit 2019 der wichtigste AI-Benchmark.
Der menschliche Basiswert beim MMLU liegt bei 89,8%, und im Jahr 2019 erzielte das durchschnittliche KI-Modell knapp über 30%. Nur 5 Jahre später war Gemini Ultra das erste Modell, das mit einem Wert von 90,04% den menschlichen Ausgangswert übertraf.
Der Bericht stellt fest, dass aktuelle "KI-Systeme routinemäßig die menschliche Leistung bei Standard-Benchmarks übertreffen". Die Trends in der nachstehenden Grafik scheinen darauf hinzudeuten, dass die MMLU und andere Benchmarks ersetzt werden müssen.
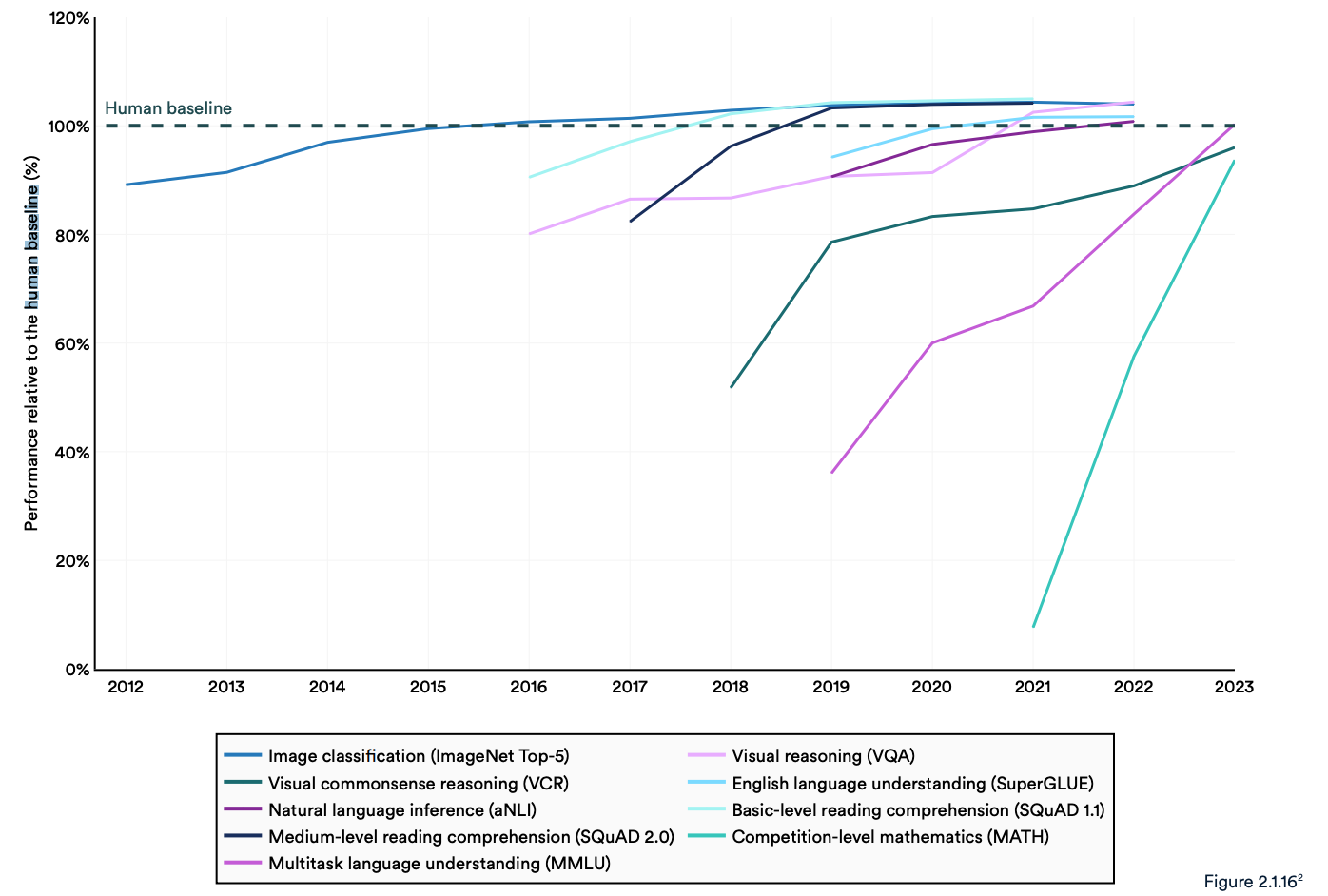
KI-Modelle haben bei etablierten Benchmarks wie ImageNet, SQuAD und SuperGLUE eine Leistungssättigung erreicht, so dass die Forscher anspruchsvollere Tests entwickeln.
Ein Beispiel ist der Graduate-Level Google-Proof Q&A Benchmark (GPQA), der es ermöglicht, KI-Modelle mit wirklich intelligenten Menschen zu vergleichen, anstatt mit der durchschnittlichen menschlichen Intelligenz.
Der GPQA-Test besteht aus 400 anspruchsvollen Multiple-Choice-Fragen für Hochschulabsolventen. Experten, die promoviert haben oder promovieren, beantworten die Fragen in 65% der Fälle richtig.
In dem GPQA-Papier heißt es, dass "hochqualifizierte, nicht fachkundige Validierer bei Fragen außerhalb ihres Fachgebiets nur eine Genauigkeit von 34% erreichen, obwohl sie im Durchschnitt über 30 Minuten mit uneingeschränktem Zugang zum Internet verbringen".
Letzten Monat gab Anthropic bekannt, dass Claude 3 knapp unter 60% mit 5-Schuss-CoT-Eingabeaufforderung erzielt. Wir werden einen größeren Benchmark brauchen.
Claude 3 erreicht ~60% Genauigkeit bei GPQA. Es fällt mir schwer, zu betonen, wie schwer diese Fragen sind - echte Doktoranden (in anderen Bereichen als den Fragen) mit Internetzugang erreichen 34%.
Doktoranden *im gleichen Bereich* (auch mit Internetzugang!) erhalten 65% - 75% Genauigkeit. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4. März 2024
Menschliche Bewertungen und Sicherheit
In dem Bericht wird festgestellt, dass die KI noch mit erheblichen Problemen zu kämpfen hat: "Sie kann nicht zuverlässig mit Fakten umgehen, komplexe Überlegungen anstellen oder ihre Schlussfolgerungen erklären."
Diese Einschränkungen tragen zu einem weiteren Merkmal des KI-Systems bei, das dem Bericht zufolge nur unzureichend gemessen wird; AI-Sicherheit. Wir haben keine effektiven Benchmarks, die es uns erlauben zu sagen: "Dieses Modell ist sicherer als jenes".
Das liegt zum einen daran, dass sie schwer zu messen ist, und zum anderen daran, dass es den KI-Entwicklern an Transparenz mangelt, insbesondere was die Offenlegung von Trainingsdaten und -methoden angeht.
In dem Bericht wird festgestellt, dass ein interessanter Trend in der Branche darin besteht, menschliche Bewertungen der KI-Leistung anstelle von Benchmark-Tests vorzunehmen.
Die Bewertung der Bildästhetik oder der Prosa eines Modells lässt sich nur schwer mit einem Test durchführen. Daher heißt es in dem Bericht, dass "das Benchmarking langsam dazu übergeht, menschliche Bewertungen wie das Chatbot Arena Leaderboard anstelle von computerisierten Rankings wie ImageNet oder SQuAD einzubeziehen".
Da die KI-Modelle die menschliche Basislinie im Rückspiegel verschwinden sehen, könnte die Stimmung letztendlich bestimmen, welches Modell wir verwenden werden.
Die Trends deuten darauf hin, dass KI-Modelle irgendwann schlauer sein werden als wir und schwieriger zu messen. Vielleicht werden wir bald sagen: "Ich weiß nicht, warum, aber dieses Modell gefällt mir einfach besser".



