

Microsoft hat Phi-3 Mini vorgestellt, ein winziges Sprachmodell, das Teil der Strategie des Unternehmens ist, leichtgewichtige, funktionsspezifische KI-Modelle zu entwickeln.
Die Entwicklung von Sprachmodellen hat zu immer größeren Parametern, Trainingsdatensätzen und Kontextfenstern geführt. Die Skalierung der Größe dieser Modelle lieferte immer leistungsfähigere Funktionen, allerdings zu einem gewissen Preis.
Der herkömmliche Ansatz für die Ausbildung eines LLM besteht darin, dass es riesige Datenmengen verbraucht, was enorme Rechenressourcen erfordert. Die Ausbildung eines LLM wie z.B. GPT-4 hat schätzungsweise etwa 3 Monate gedauert und über $21 Mio. gekostet.
GPT-4 ist eine großartige Lösung für Aufgaben, die komplexes Denken erfordern, aber ein Overkill für einfachere Aufgaben wie die Erstellung von Inhalten oder einen Vertriebs-Chatbot. Es ist, als würde man ein Schweizer Armeemesser verwenden, wenn man nur einen einfachen Brieföffner braucht.
Mit nur 3,8B Parametern ist der Phi-3 Mini winzig. Dennoch ist er laut Microsoft eine ideale, leichtgewichtige und kostengünstige Lösung für Aufgaben wie die Zusammenfassung eines Dokuments, die Extraktion von Erkenntnissen aus Berichten und das Schreiben von Produktbeschreibungen oder Beiträgen für soziale Medien.
Die MMLU-Benchmark-Zahlen zeigen, dass der Phi-3 Mini und die noch zu veröffentlichenden größeren Phi-Modelle die größeren Modelle wie Mistral 7B und Gemma 7B.
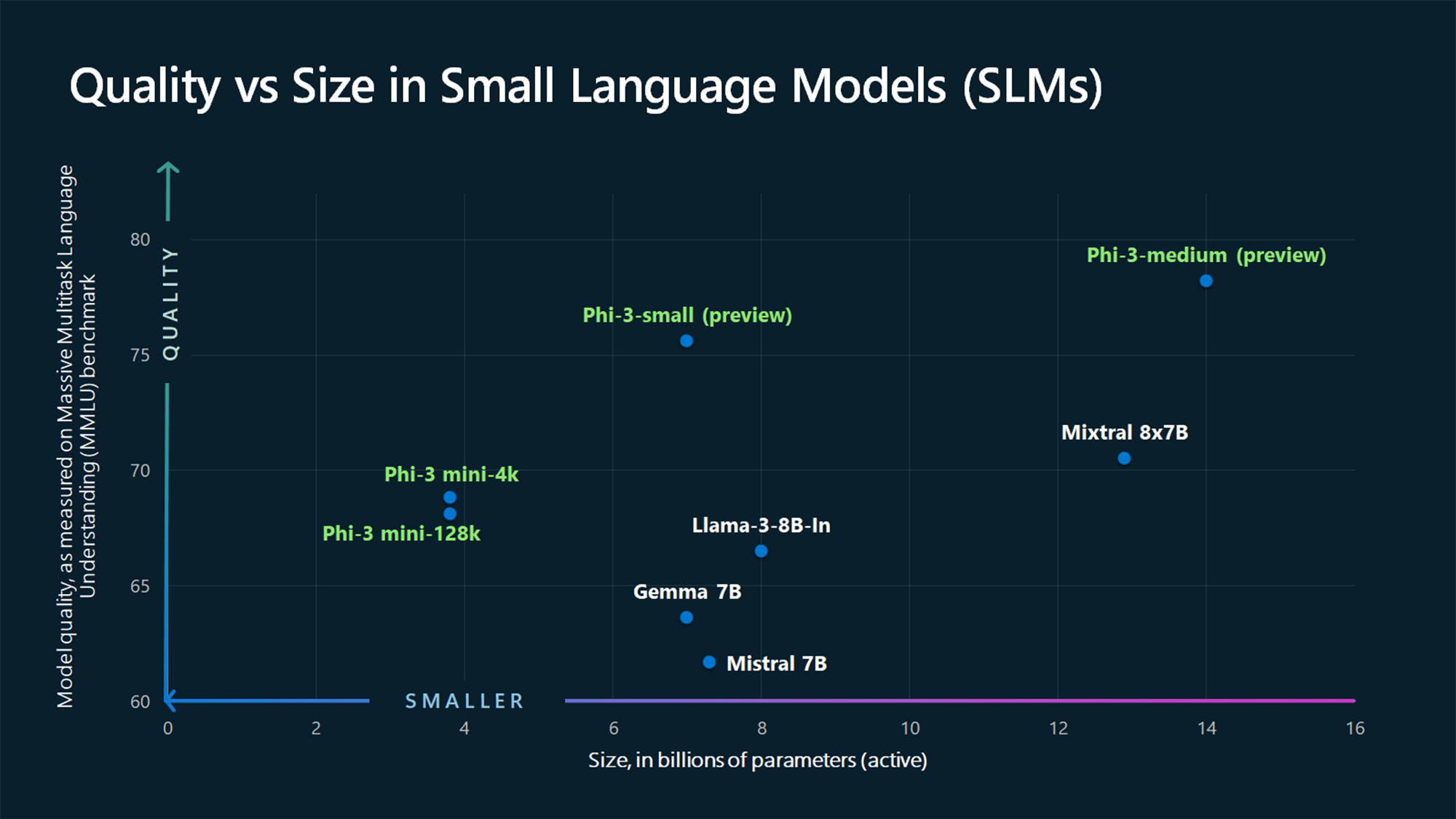
Microsoft sagt, dass Phi-3-small (7B Parameter) und Phi-3-medium (14B Parameter) in Kürze im Azure AI Model Catalog verfügbar sein werden.
Größere Modelle wie das GPT-4 sind nach wie vor der Goldstandard, und wir können wahrscheinlich davon ausgehen, dass das GPT-5 noch größer sein wird.
SLMs wie der Phi-3 Mini bieten einige wichtige Vorteile, die größere Modelle nicht haben. SLMs sind billiger in der Feinabstimmung, benötigen weniger Rechenleistung und können selbst in Situationen, in denen kein Internetzugang verfügbar ist, auf dem Gerät laufen.
Der Einsatz eines SLM am Netzwerkrand sorgt für geringere Latenzzeiten und maximalen Datenschutz, da keine Daten zur Cloud hin- und hergeschickt werden müssen.
Hier ist Sebastien Bubeck, VP der GenAI-Forschung bei Microsoft AI mit einer Demo des Phi-3 Mini. Er ist superschnell und beeindruckend für so ein kleines Modell.
phi-3 ist da, und es ist ... gut :-).
Ich habe eine kurze Demo erstellt, um euch ein Gefühl dafür zu geben, was phi-3-mini (3.8B) kann. Bleiben Sie dran für die Freigabe der Gewichte und weitere Ankündigungen morgen früh!
(Und natürlich wäre dies nicht vollständig ohne die übliche Tabelle mit den Benchmarks!) pic.twitter.com/AWA7Km59rp
- Sebastien Bubeck (@SebastienBubeck) 23. April 2024
Kuratierte synthetische Daten
Phi-3 Mini ist ein Ergebnis der Abkehr von der Vorstellung, dass große Datenmengen die einzige Möglichkeit sind, ein Modell zu trainieren.
Sébastien Bubeck, Vizepräsident für generative KI-Forschung bei Microsoft, fragte: "Warum trainiert man nicht einfach mit rohen Webdaten, sondern sucht nach Daten, die von extrem hoher Qualität sind?"
Ronen Eldan, Experte für maschinelles Lernen bei Microsoft Research, las seiner Tochter gerade Gutenachtgeschichten vor, als er sich fragte, ob ein Sprachmodell nur mit Wörtern lernen könnte, die eine Vierjährige versteht.
Dies führte zu einem Experiment, bei dem sie einen Datensatz mit zunächst 3.000 Wörtern erstellten. Unter Verwendung dieses begrenzten Vokabulars veranlassten sie einen LLM, Millionen von kurzen Kindergeschichten zu erstellen, die in einem Datensatz namens TinyStories zusammengefasst wurden.
Mit TinyStories trainierten die Forscher dann ein extrem kleines Modell mit 10 Millionen Parametern, das anschließend in der Lage war, "flüssige Erzählungen mit perfekter Grammatik" zu erzeugen.
Sie haben diesen Ansatz zur Generierung synthetischer Daten weiter verfeinert und skaliert, um fortschrittlichere, aber sorgfältig kuratierte und gefilterte synthetische Datensätze zu erstellen, die schließlich zum Training von Phi-3 Mini verwendet wurden.
Das Ergebnis ist ein winziges Modell, das erschwinglicher ist und eine vergleichbare Leistung wie GPT-3.5 bietet.
Kleinere, aber leistungsfähigere Modelle werden dazu führen, dass Unternehmen nicht mehr einfach große LLMs wie GPT-4 verwenden. Wir könnten auch bald Lösungen sehen, bei denen ein LLM die schweren Aufgaben übernimmt und einfachere Aufgaben an leichtgewichtige Modelle delegiert.



