

Google's DeepMind hat Gecko veröffentlicht, einen neuen Benchmark für die umfassende Bewertung von KI-Modellen für die Text-Bild-Erkennung (T2I).
In den letzten zwei Jahren haben wir KI-Bildgeneratoren wie DALL-E und Midjourney werden mit jeder neuen Version immer besser.
Die Entscheidung, welches der diesen Plattformen zugrundeliegenden Modelle das beste ist, war jedoch weitgehend subjektiv und schwer zu bewerten.
Die pauschale Behauptung, dass ein Modell "besser" ist als ein anderes, ist nicht so einfach zu treffen. Verschiedene Modelle zeichnen sich durch unterschiedliche Aspekte der Bilderzeugung aus. Ein Modell kann gut bei der Textdarstellung sein, während ein anderes besser bei der Objektinteraktion ist.
Eine zentrale Herausforderung für T2I-Modelle besteht darin, jedes Detail in der Eingabeaufforderung zu verfolgen und diese im generierten Bild genau wiederzugeben.
Mit Gecko, dem DeepMind Forscher haben ein Benchmark das die Fähigkeiten von T2I-Modellen ähnlich wie beim Menschen bewertet.
Fertigkeiten
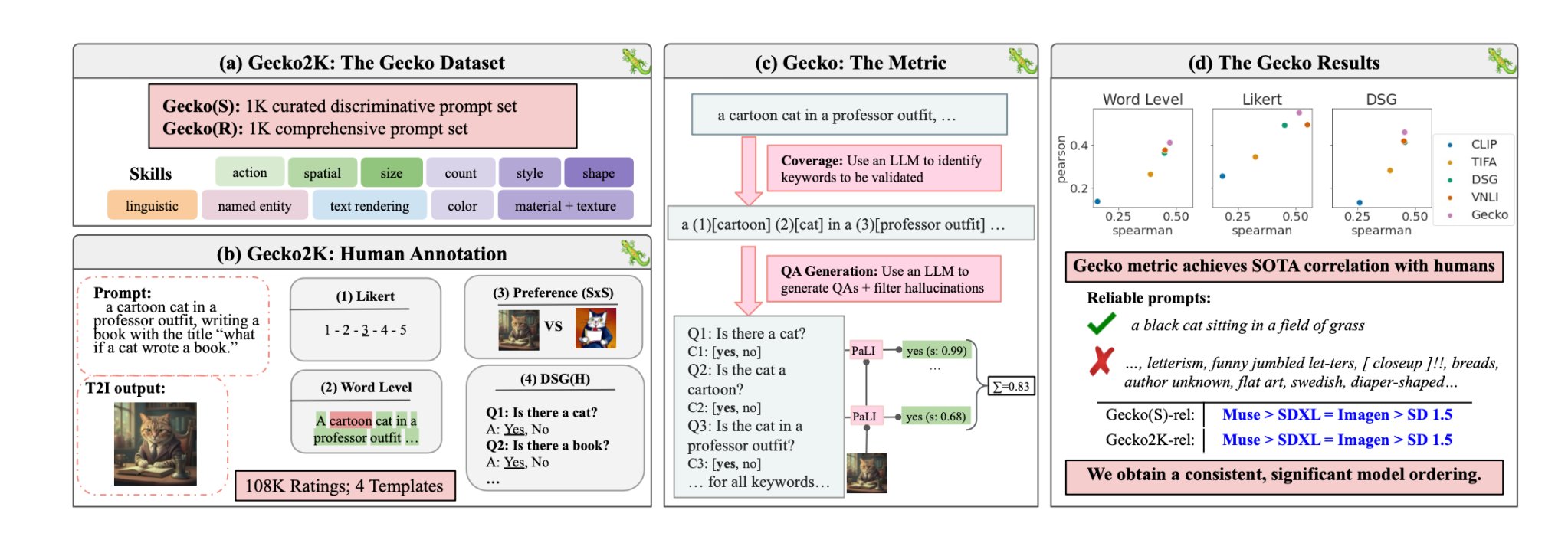
Die Forscher definierten zunächst einen umfassenden Datensatz von Fähigkeiten, die für die T2I-Generierung relevant sind. Dazu gehören räumliches Verständnis, Handlungserkennung, Textwiedergabe und andere. Anschließend unterteilten sie diese in spezifischere Teilkompetenzen.
Zum Beispiel könnten die Teilfertigkeiten im Bereich Textwiedergabe die Wiedergabe verschiedener Schriftarten, Farben oder Textgrößen umfassen.
Ein LLM wurde dann verwendet, um Prompts zu generieren, mit denen die Fähigkeit des T2I-Modells für eine bestimmte Fertigkeit oder Teilfertigkeit getestet werden konnte.
Auf diese Weise können die Entwickler eines T2I-Modells nicht nur feststellen, welche Fertigkeiten schwierig sind, sondern auch, ab welchem Komplexitätsgrad eine Fertigkeit für ihr Modell eine Herausforderung darstellt.
Menschliche Bewertung vs. automatische Bewertung
Gecko misst auch, wie genau ein T2I-Modell alle Details in einer Aufforderung verfolgt. Auch hier wurde ein LLM verwendet, um Schlüsseldetails in jeder Eingabeaufforderung zu isolieren und dann eine Reihe von Fragen zu diesen Details zu generieren.
Bei diesen Fragen kann es sich sowohl um einfache, direkte Fragen zu sichtbaren Elementen im Bild handeln (z. B. "Ist eine Katze auf dem Bild?") als auch um komplexere Fragen, die das Verständnis der Szene oder die Beziehungen zwischen Objekten testen (z. B. "Sitzt die Katze über dem Buch?").
Ein Visual Question Answering (VQA)-Modell analysiert dann das erzeugte Bild und beantwortet die Fragen, um zu sehen, wie genau das T2I-Modell sein Ausgabebild mit einer Eingabeaufforderung abgleicht.
Die Forscher sammelten über 100.000 menschliche Kommentare, bei denen die Teilnehmer ein generiertes Bild danach bewerteten, wie gut es bestimmten Kriterien entsprach.
Die Menschen wurden gebeten, einen bestimmten Aspekt der Eingabeaufforderung zu berücksichtigen und das Bild auf einer Skala von 1 bis 5 zu bewerten, je nachdem, wie gut es der Aufforderung entsprach.
Unter Verwendung der von Menschen kommentierten Bewertungen als Goldstandard konnten die Forscher bestätigen, dass ihre Auto-Eval-Metrik "besser mit menschlichen Bewertungen korreliert als bestehende Metriken für unseren neuen Datensatz".
Das Ergebnis ist ein Benchmarking-System, das in der Lage ist, bestimmte Faktoren zu beziffern, die ein generiertes Bild gut oder schlecht machen.
Gecko bewertet das ausgegebene Bild im Wesentlichen so, wie wir intuitiv entscheiden, ob wir mit dem erzeugten Bild zufrieden sind oder nicht.
Welches ist also das beste Text-Bild-Modell?
Unter ihr Papierkamen die Forscher zu dem Schluss, dass das Muse-Modell von Google beim Gecko-Benchmark Stable Diffusion 1.5 und SDXL übertrifft. Sie mögen voreingenommen sein, aber die Zahlen lügen nicht.



