

Forscher von DeepMind und der Stanford University haben einen KI-Agenten entwickelt, der LLMs auf Fakten prüft und ein Benchmarking der Faktizität von KI-Modellen ermöglicht.
Selbst die besten KI-Modelle neigen immer noch dazu halluzinieren zuweilen. Wenn Sie ChatGPT bitten, Ihnen die Fakten zu einem Thema zu nennen, ist es umso wahrscheinlicher, dass die Antwort einige Fakten enthält, die nicht wahr sind, je länger sie ist.
Welche Modelle sind bei der Erstellung längerer Antworten sachlich genauer als andere? Das ist schwer zu sagen, denn bis jetzt hatten wir keinen Maßstab, um die Sachlichkeit von LLM-Langzeitantworten zu messen.
DeepMind verwendete zunächst GPT-4, um LongFact zu erstellen, eine Reihe von 2.280 Aufforderungen in Form von Fragen zu 38 Themen. Diese Aufforderungen entlocken dem getesteten LLM Antworten in Langform.
Dann schufen sie einen KI-Agenten mit GPT-3.5-Turbo, um mit Hilfe von Google zu überprüfen, wie sachlich die vom LLM generierten Antworten waren. Sie nannten die Methode Search-Augmented Factuality Evaluator (SAFE).
SAFE zerlegt zunächst die Langform-Antwort des LLM in einzelne Fakten. Dann sendet es Suchanfragen an Google Search und entscheidet anhand der Informationen in den zurückgegebenen Suchergebnissen über den Wahrheitsgehalt des Sachverhalts.
Hier ist ein Beispiel aus dem Forschungsarbeit.
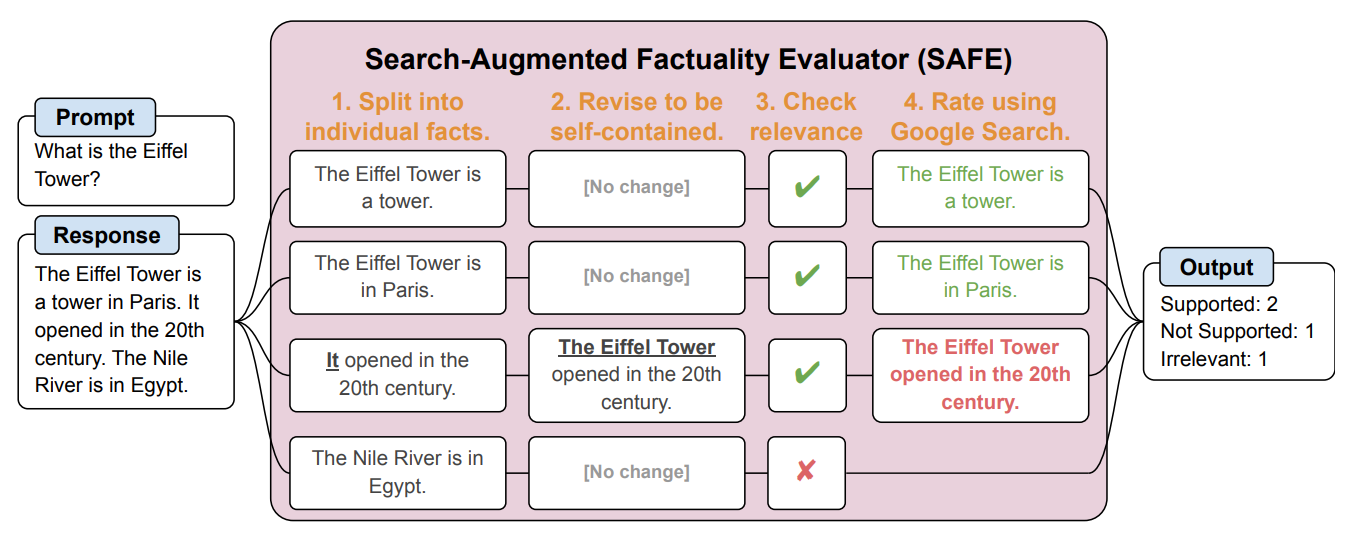
Die Forscher sagen, dass SAFE eine "übermenschliche Leistung" im Vergleich zu menschlichen Kommentatoren erreicht, die die Faktenüberprüfung durchführen.
SAFE stimmte in 72% der Fälle mit menschlichen Annotationen überein, und in 76% der Fälle, in denen es von den menschlichen Annotationen abwich, lag es richtig. Außerdem war es 20-mal billiger als menschliche Annotatoren, die von einer Crowd gestellt wurden. LLMs sind also bessere und billigere Faktenüberprüfer als Menschen.
Die Qualität der Antworten der getesteten LLMs wurde anhand der Anzahl der Fakten in ihrer Antwort in Kombination mit der Sachlichkeit der einzelnen Fakten gemessen.
Die von ihnen verwendete Metrik (F1@K) schätzt die vom Menschen bevorzugte "ideale" Anzahl von Fakten in einer Antwort. Bei den Benchmark-Tests wurden 64 als Medianwert für K und 178 als Höchstwert verwendet.
Einfach ausgedrückt ist F1@K ein Maß für die Frage "Hat mir die Antwort so viele Fakten geliefert, wie ich wollte?" in Kombination mit der Frage "Wie viele dieser Fakten waren wahr?".
Welcher LLM ist am sachlichsten?
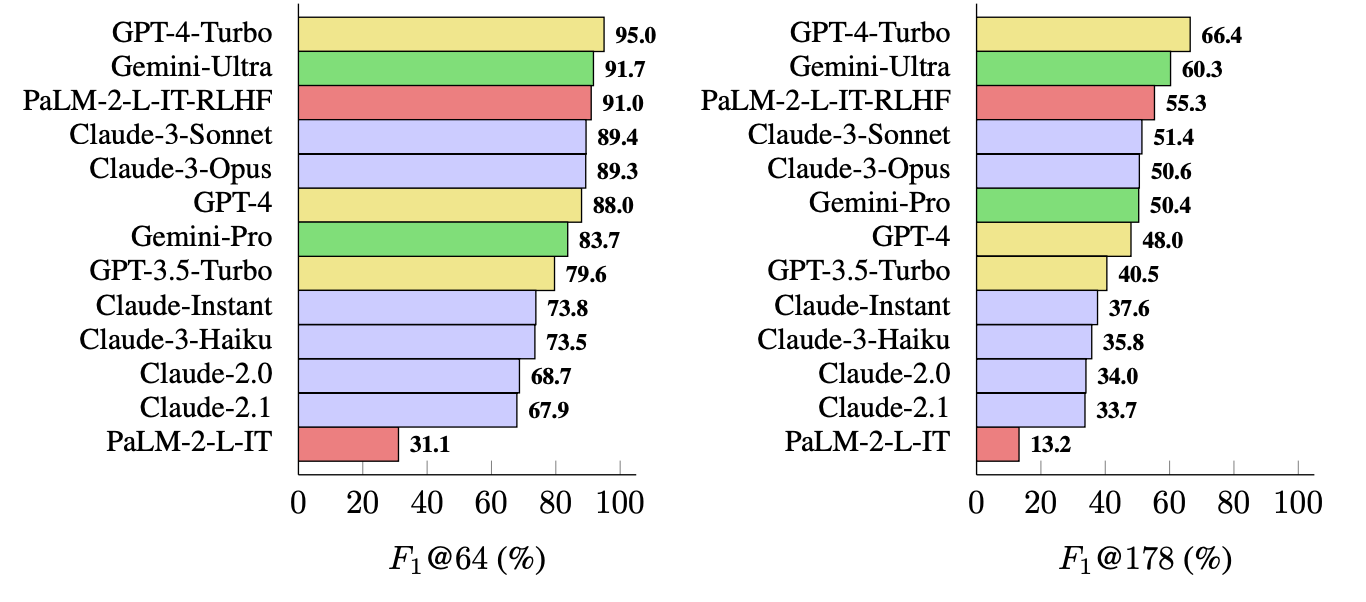
Die Forscher verwendeten LongFact, um 13 LLMs aus den Familien Gemini, GPT, Claude und PaLM-2 zu befragen. Anschließend bewerteten sie mit SAFE die Sachbezogenheit ihrer Antworten.
GPT-4-Turbo führt die Liste der sachlichsten Modelle bei der Erstellung von Langformantworten an. Es wurde dicht gefolgt von Gemini-Ultra und PaLM-2-L-IT-RLHF. Die Ergebnisse zeigen, dass größere LLMs sachlicher sind als kleinere.
Die F1@K-Berechnung würde Datenwissenschaftler wahrscheinlich begeistern, aber der Einfachheit halber zeigen diese Benchmark-Ergebnisse, wie faktisch jedes Modell bei der Rückgabe von durchschnittlich langen und längeren Antworten auf die Fragen ist.
SAFE ist eine kostengünstige und wirksame Methode zur Quantifizierung der Faktizität von LLM-Langzeitstudien. Es ist schneller und billiger als menschliche Faktenüberprüfung, aber es hängt immer noch von der Wahrhaftigkeit der Informationen ab, die Google in den Suchergebnissen ausgibt.
DeepMind gab SAFE zur öffentlichen Nutzung frei und schlug vor, dass es helfen könnte, die Faktizität von LLMs durch besseres Vortraining und Feinabstimmung zu verbessern. Es könnte auch einen LLM in die Lage versetzen, seine Fakten zu überprüfen, bevor er einem Nutzer die Ausgabe präsentiert.
OpenAI wird sich freuen zu sehen, dass die Forschung von Google zeigt, dass GPT-4 Gemini in einem weiteren Benchmark schlägt.



