

Apple-Ingenieure haben ein KI-System entwickelt, das komplexe Verweise auf Bildschirmelemente und Benutzergespräche auflöst. Das leichtgewichtige Modell könnte eine ideale Lösung für virtuelle Assistenten auf Geräten sein.
Menschen sind gut darin, Bezüge in Gesprächen untereinander aufzulösen. Wenn wir Begriffe wie "der untere" oder "er" verwenden, verstehen wir, worauf sich die Person bezieht, basierend auf dem Kontext des Gesprächs und den Dingen, die wir sehen können.
Für ein KI-Modell ist das viel schwieriger. Multimodale LLMs wie GPT-4 sind gut bei der Beantwortung von Fragen zu Bildern, aber sie sind teuer zu trainieren und erfordern eine Menge Rechenaufwand, um jede Anfrage zu einem Bild zu verarbeiten.
Die Apple-Ingenieure verfolgten mit ihrem System, das sie ReALM (Reference Resolution As Language Modeling) nannten, einen anderen Ansatz. Das Papier ist es wert, gelesen zu werden, um mehr über den Entwicklungs- und Testprozess zu erfahren.
ReALM verwendet ein LLM zur Verarbeitung von Konversations-, Bildschirm- und Hintergrundinformationen (Alarme, Hintergrundmusik), die die Interaktion eines Benutzers mit einem virtuellen KI-Agenten ausmachen.
Hier ein Beispiel für die Art der Interaktion, die ein Nutzer mit einem KI-Agenten haben könnte.
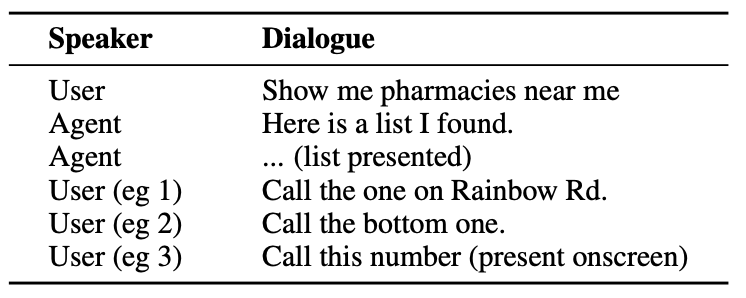
Der Agent muss Konversationseinheiten verstehen, wie z. B. die Tatsache, dass sich der Benutzer, wenn er "die" sagt, auf die Telefonnummer der Apotheke bezieht.
Es muss auch den visuellen Kontext verstehen, wenn der Benutzer "das untere" sagt, und hier unterscheidet sich der Ansatz von ReALM von Modellen wie GPT-4.
ReALM stützt sich auf vorgelagerte Encoder, die zunächst die Bildschirmelemente und deren Positionen analysieren. Anschließend rekonstruiert ReALM den Bildschirm in rein textuellen Darstellungen von links nach rechts und von oben nach unten.
Vereinfacht ausgedrückt, verwendet es natürliche Sprache, um den Bildschirm des Benutzers zusammenzufassen.
Wenn nun ein Benutzer eine Frage zu etwas auf dem Bildschirm stellt, verarbeitet das Sprachmodell die Textbeschreibung des Bildschirms, anstatt ein Bildmodell zur Verarbeitung des Bildes auf dem Bildschirm zu verwenden.
Die Forscher erstellten synthetische Datensätze von Gesprächs-, Bildschirm- und Hintergrundentitäten und testeten ReALM und andere Modelle, um ihre Effektivität bei der Auflösung von Referenzen in Gesprächssystemen zu prüfen.
Die kleinere Version von ReALM (80M Parameter) schneidet vergleichbar mit GPT-4 ab und die größere Version (3B Parameter) übertrifft GPT-4 deutlich.
ReALM ist im Vergleich zum GPT-4 ein winziges Modell. Seine überlegene Referenzauflösung macht ihn zur idealen Wahl für einen virtuellen Assistenten, der ohne Leistungseinbußen auf dem Gerät betrieben werden kann.
ReALM funktioniert nicht so gut bei komplexeren Bildern oder nuancierten Benutzeranfragen, aber es könnte gut als virtueller Assistent im Auto oder auf dem Gerät funktionieren. Stellen Sie sich vor, Siri könnte Ihren iPhone-Bildschirm "sehen" und auf Verweise auf Bildschirmelemente reagieren.
Apple ist ein wenig langsam aus den Startlöchern gekommen, aber die jüngsten Entwicklungen wie die Modell MM1 und ReALM zeigen, dass sich vieles hinter verschlossenen Türen abspielt.



