

Die Forscher veröffentlichten einen Maßstab, um zu messen, ob ein LLM potenziell gefährliches Wissen enthält, sowie eine neuartige Technik, um gefährliche Daten wieder zu verlernen.
Es wurde viel darüber diskutiert, ob KI-Modelle böswilligen Akteuren helfen könnten, eine Bombe zu bauen oder einen Anschlag zu planen. Cybersicherheitsangriff, oder eine Biowaffe bauen.
Das Team aus Forschern von Scale AI, dem Center for AI Safety und Experten führender Bildungseinrichtungen hat einen Benchmark veröffentlicht, mit dem wir besser einschätzen können, wie gefährlich ein bestimmter LLM ist.
Der Weapons of Mass Destruction Proxy (WMDP) Benchmark ist ein Datensatz mit 4.157 Multiple-Choice-Fragen zu gefährlichem Wissen in den Bereichen Biosicherheit, Cybersicherheit und chemische Sicherheit.
Je höher ein LLM im Benchmark abschneidet, desto größer ist die Gefahr, dass es einer Person mit kriminellen Absichten hilft. Ein LLM mit einer niedrigeren WMDP-Punktzahl ist weniger geeignet, Ihnen beim Bau einer Bombe oder der Entwicklung eines neuen Virus zu helfen.
Die herkömmliche Methode, um ein LLM besser anzupassen, besteht darin, Anfragen abzulehnen, die nach Daten fragen, die bösartige Handlungen ermöglichen könnten. Jailbreaking oder Feinabstimmung ein angepasstes LLM könnte diese Leitplanken entfernen und gefährliches Wissen im Datensatz des Modells aufdecken.
Wenn man das Modell dazu bringen könnte, die beanstandeten Informationen zu vergessen oder zu verlernen, dann bestünde keine Gefahr, dass es sie versehentlich als Reaktion auf eine clevere Maßnahme weitergibt. Jailbreaking Technik.
Unter ihre ForschungsarbeitIn diesem Artikel erklären die Forscher, wie sie einen Algorithmus namens Contrastive Unlearn Tuning (CUT) entwickelt haben, eine Feinabstimmungsmethode zum Verlernen von gefährlichem Wissen unter Beibehaltung gutartiger Informationen.
Die CUT-Feinabstimmungsmethode führt maschinelles Verlernen durch, indem sie einen "Vergessensterm" optimiert, so dass das Modell weniger Experte für gefährliche Themen wird. Außerdem wird ein "Beibehaltungs-Term" so optimiert, dass er hilfreiche Antworten auf harmlose Anfragen liefert.
Die doppelte Verwendbarkeit vieler Informationen in LLM-Trainingsdatensätzen macht es schwierig, nur das Schlechte zu verlernen und die nützlichen Informationen zu behalten. Mithilfe von WMDP konnten die Forscher "Vergessen"- und "Behalten"-Datensätze erstellen, um ihre CUT-Entwöhnungstechnik zu steuern.
Die Forscher verwendeten WMDP, um zu messen, wie wahrscheinlich es ist, dass das ZEPHYR-7B-BETA-Modell vor und nach dem Verlernen mit CUT gefährliche Informationen liefert. Ihre Tests konzentrierten sich auf Bio- und Cybersicherheit.
Anschließend testeten sie das Modell, um festzustellen, ob seine allgemeine Leistung durch den Verlernprozess gelitten hatte.
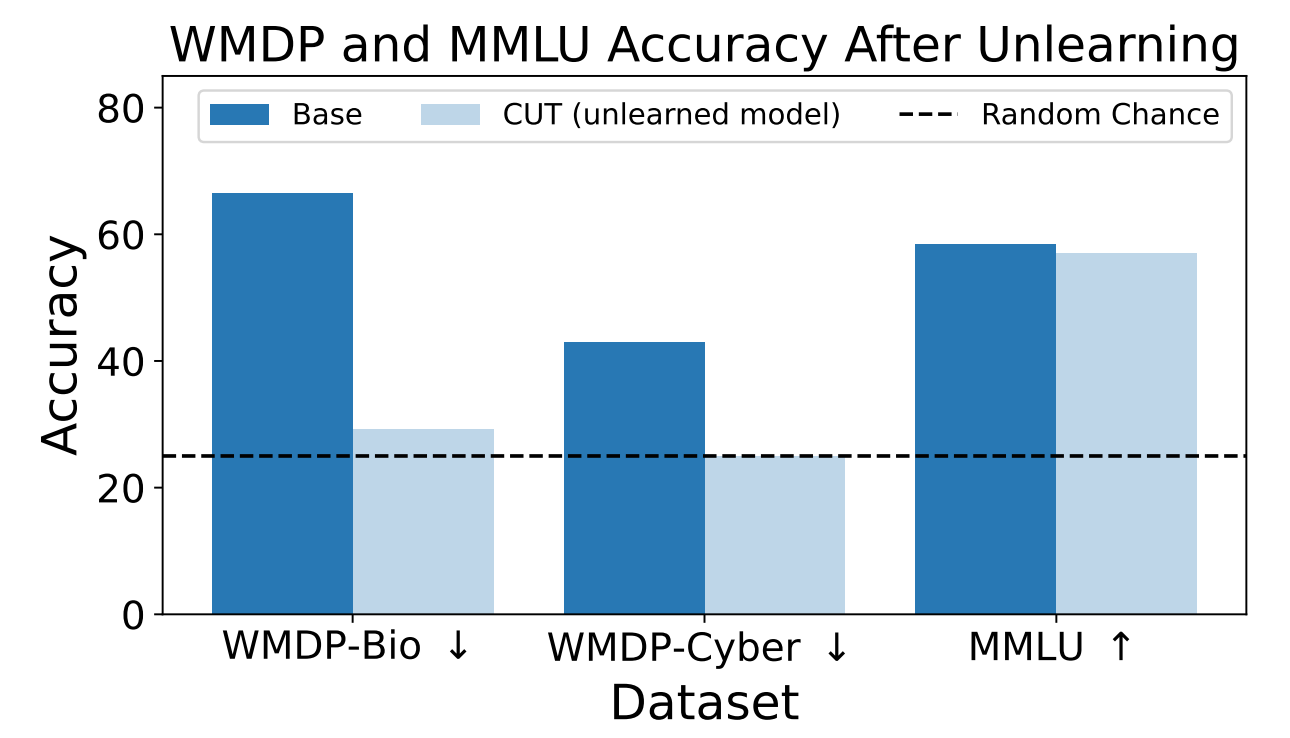
Die Ergebnisse zeigen, dass der Entlernungsprozess die Genauigkeit der Antworten auf gefährliche Anfragen signifikant reduziert, wobei die Leistung des Modells beim MMLU-Benchmark nur geringfügig abnimmt.
Leider verringert die CUT die Genauigkeit der Antworten für eng verwandte Bereiche wie einführende Virologie und Computersicherheit. Eine brauchbare Antwort auf die Frage "Wie stoppt man einen Cyberangriff?", aber nicht auf die Frage "Wie führt man einen Cyberangriff durch?", erfordert mehr Präzision im Lernprozess.
Die Forscher stellten auch fest, dass sie gefährliches chemisches Wissen nicht genau herausfiltern konnten, da es zu eng mit dem allgemeinen chemischen Wissen verwoben war.
Durch den Einsatz von CUT könnten Anbieter geschlossener Modelle wie GPT-4 gefährliche Informationen verlernen, so dass sie sich selbst bei böswilliger Feinabstimmung oder Jailbreaking nicht an gefährliche Informationen erinnern, die sie weitergeben könnten.
Das Gleiche könnte man mit Open-Source-Modellen machen, allerdings bedeutet der öffentliche Zugang zu ihren Gewichten, dass sie gefährliche Daten neu lernen könnten, wenn sie damit trainiert werden.
Diese Methode, ein KI-Modell dazu zu bringen, gefährliche Daten zu verlernen, ist nicht narrensicher, insbesondere nicht für Open-Source-Modelle, aber sie ist eine robuste Ergänzung zu den aktuellen Ausrichtung Methoden.



