

Apple hat noch kein offizielles KI-Modell veröffentlicht, aber ein neues Forschungspapier gibt einen Einblick in die Fortschritte des Unternehmens bei der Entwicklung von Modellen mit modernen multimodalen Fähigkeiten.
Das Papiermit dem Titel "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training" (Methoden, Analysen und Erkenntnisse aus der multimodalen LLM-Vorschulung) wird die MLLM-Familie von Apple mit der Bezeichnung MM1 vorgestellt.
MM1 zeigt beeindruckende Fähigkeiten bei der Erfassung von Bildunterschriften, der Beantwortung visueller Fragen (VQA) und der Inferenz natürlicher Sprache. Die Forscher erklären, dass sie durch die sorgfältige Auswahl von Bild-Beschriftungspaaren hervorragende Ergebnisse erzielen konnten, insbesondere in Lernszenarien mit wenigen Aufnahmen.
Was das MM1 von anderen MLLMs unterscheidet, ist seine überragende Fähigkeit, Anweisungen über mehrere Bilder hinweg zu befolgen und die komplexen Szenen, die ihm vorgelegt werden, zu verstehen.
Die MM1-Modelle enthalten bis zu 30B Parameter, das ist dreimal so viel wie beim GPT-4V, der Komponente, die dem GPT-4 von OpenAI seine Vision-Fähigkeiten verleiht.
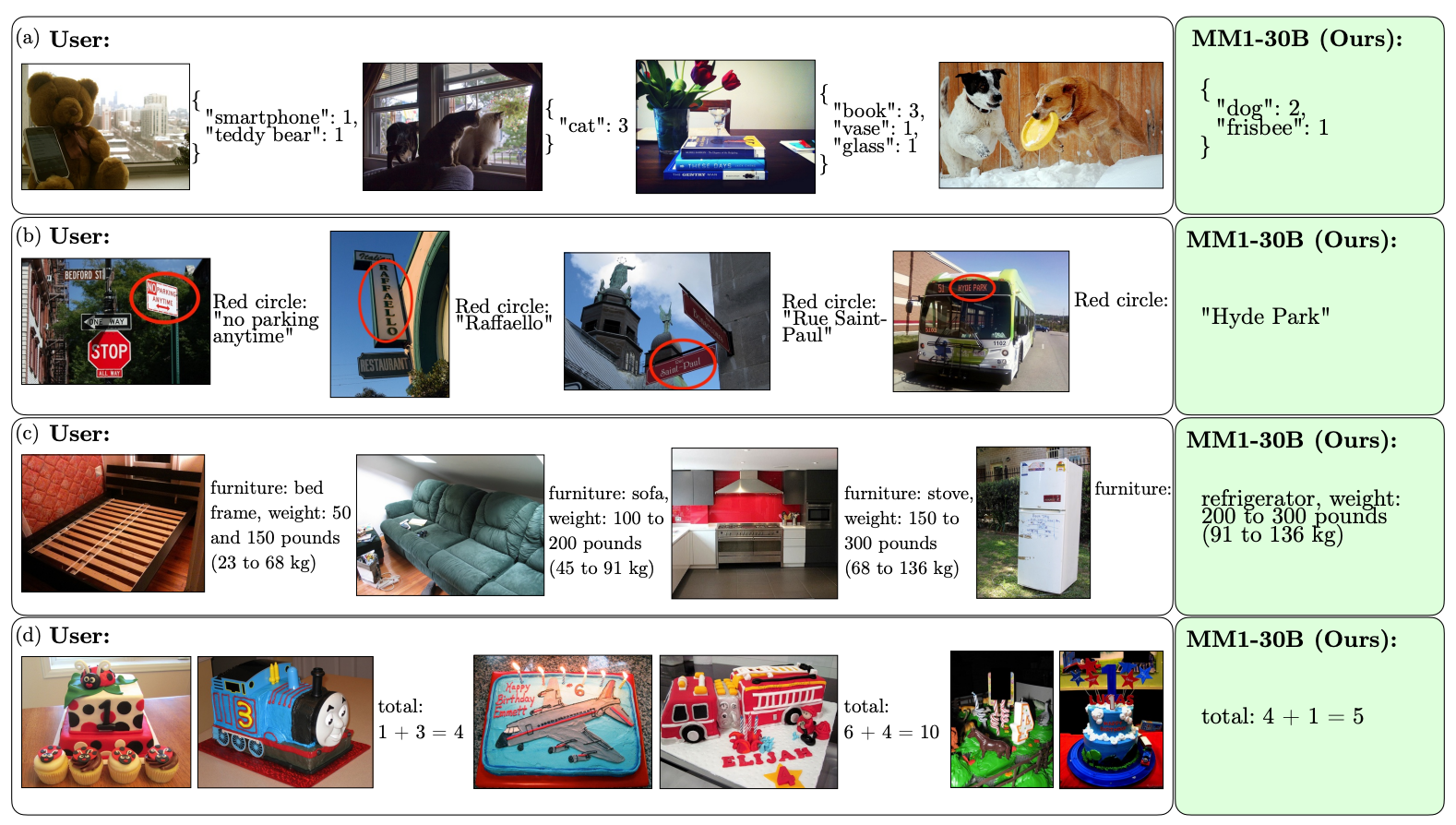
Hier sind einige Beispiele für die VQA-Fähigkeiten des MM1.

MM1 wurde einem umfangreichen multimodalen Vortraining mit "einem Datensatz von 500M verschachtelten Bild-Text-Dokumenten, die 1B Bilder und 500B Text-Token enthalten" unterzogen.
Dank des Umfangs und der Vielfalt seines Vortrainings ist MM1 in der Lage, beeindruckende kontextbezogene Vorhersagen zu treffen und benutzerdefinierte Formatierungen mit einer kleinen Anzahl von Beispielen mit wenigen Aufnahmen zu befolgen. Hier sind Beispiele dafür, wie MM1 die gewünschte Ausgabe und das Format aus nur 3 Beispielen erlernt.
Die Entwicklung von KI-Modellen, die "sehen" und denken können, erfordert eine Verbindung zwischen Bild und Sprache, die Bilder und Sprache in eine einheitliche Darstellung übersetzt, die das Modell für die weitere Verarbeitung nutzen kann.
Die Forscher fanden heraus, dass das Design des Bild-Sprache-Verbinders weniger ein Faktor für die Leistung von MM1 war. Interessanterweise waren es die Bildauflösung und die Anzahl der Bildtoken, die den größten Einfluss hatten.
Es ist interessant zu sehen, wie offen Apple seine Forschungsergebnisse mit der breiteren KI-Gemeinschaft teilt. Die Forscher erklären: "In diesem Papier dokumentieren wir den MLLM-Bauprozess und versuchen, Design-Lektionen zu formulieren, von denen wir hoffen, dass sie für die Gemeinschaft nützlich sind.
Die veröffentlichten Ergebnisse werden wahrscheinlich die Richtung vorgeben, die andere MMLM-Entwickler in Bezug auf die Architektur und die Auswahl der Pre-Training-Daten einschlagen.
Wie genau die MM1-Modelle in die Produkte von Apple implementiert werden, bleibt abzuwarten. Die veröffentlichten Beispiele für die Fähigkeiten von MM1 deuten darauf hin, dass Siri sehr viel intelligenter wird, wenn sie schließlich lernt, zu sehen.



