
Das Screening von Patienten, um geeignete Teilnehmer für klinische Studien zu finden, ist eine arbeitsintensive, teure und fehleranfällige Aufgabe, aber KI könnte das bald ändern.
Ein Forscherteam des Brigham and Women's Hospital, der Harvard Medical School und des Mass General Brigham Personalized Medicine führte eine Studie durch, um herauszufinden, ob ein KI-Modell medizinische Daten verarbeiten kann, um geeignete Kandidaten für klinische Studien zu finden.
Sie nutzten GPT-4V, OpenAIs LLM mit Bildverarbeitung, die durch Retrieval-Augmented Generation (RAG) ermöglicht wird, um die elektronischen Gesundheitsakten (EHR) und klinischen Notizen potenzieller Kandidaten zu verarbeiten.
LLMs werden anhand eines festen Datensatzes trainiert und können nur auf der Grundlage dieser Daten Fragen beantworten. RAG ist eine Technik, die es einem LLM ermöglicht, Daten aus externen Datenquellen wie dem Internet oder den internen Dokumenten einer Organisation abzurufen.
Wenn Teilnehmer für eine klinische Studie ausgewählt werden, wird ihre Eignung anhand einer Liste von Ein- und Ausschlusskriterien bestimmt. Dazu müssen geschulte Mitarbeiter in der Regel die elektronischen Patientenakten von Hunderten oder Tausenden von Patienten durchforsten, um diejenigen zu finden, die den Kriterien entsprechen.
Die Forscher sammelten Daten aus einer Studie, die darauf abzielte, Patienten mit symptomatischer Herzinsuffizienz zu rekrutieren. Sie nutzten diese Daten, um herauszufinden, ob GPT-4V mit RAG die Aufgabe effizienter erledigen kann als das Studienpersonal, ohne die Genauigkeit zu beeinträchtigen.
Anhand der strukturierten Daten in den elektronischen Patientenakten potenzieller Kandidaten könnten 5 von 6 Einschluss- und 5 von 17 Ausschlusskriterien für die klinische Studie festgelegt werden. Das ist der einfache Teil.
Die verbleibenden 13 Kriterien mussten durch die Abfrage unstrukturierter Daten in den klinischen Aufzeichnungen der einzelnen Patienten ermittelt werden, was der arbeitsintensive Teil ist, bei dem die Forscher hofften, dass die KI sie unterstützen könnte.
🔍Kann @Microsoft @Azure @OpenAI's #GPT4 besser als ein Mensch für das Screening in klinischen Studien geeignet? Diese Frage haben wir uns in unserer jüngsten Studie gestellt, und ich freue mich sehr, dass wir unsere Ergebnisse im Preprint veröffentlichen können:https://t.co/lhOPKCcudP
Die Einbeziehung von GPT4 in klinische Studien ist nicht...- Ozan Unlu (@OzanUnluMD) 9. Februar 2024
Ergebnisse
Die Forscher erhielten zunächst strukturierte Beurteilungen, die vom Studienpersonal durchgeführt wurden, sowie klinische Aufzeichnungen der letzten zwei Jahre.
Sie entwickelten einen Workflow für ein auf klinischen Notizen basierendes Frage-Antwort-System, das auf der RAG-Architektur und GPT-4V basiert, und nannten diesen Workflow RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review).
Die Notizen von 100 Patienten wurden als Entwicklungsdatensatz, 282 Patienten als Validierungsdatensatz und 1894 Patienten als Testdatensatz verwendet.
Ein Klinikexperte führte eine verblindete Überprüfung der Patientenkarteien durch, um die Fragen zur Eignung zu beantworten und die "Goldstandard"-Antworten zu bestimmen. Diese wurden dann anhand der folgenden Kriterien mit den Antworten des Studienpersonals und des RECTIFIER verglichen:
- Sensitivität - Die Fähigkeit eines Tests, Patienten, die für die Studie in Frage kommen, korrekt zu identifizieren (echt positive Ergebnisse).
- Spezifität - Die Fähigkeit eines Tests, Patienten korrekt zu identifizieren, die für die Studie nicht in Frage kommen (echte Negative).
- Genauigkeit - Der Gesamtanteil der korrekten Klassifizierungen (sowohl wahr-positive als auch wahr-negative).
- Matthews-Korrelationskoeffizient (MCC) - Eine Metrik, mit der gemessen wird, wie gut das Modell bei der Auswahl oder dem Ausschluss einer Person war. Ein Wert von 0 entspricht einem Münzwurf und 1 bedeutet, dass das Modell in 100% der Fälle richtig liegt.
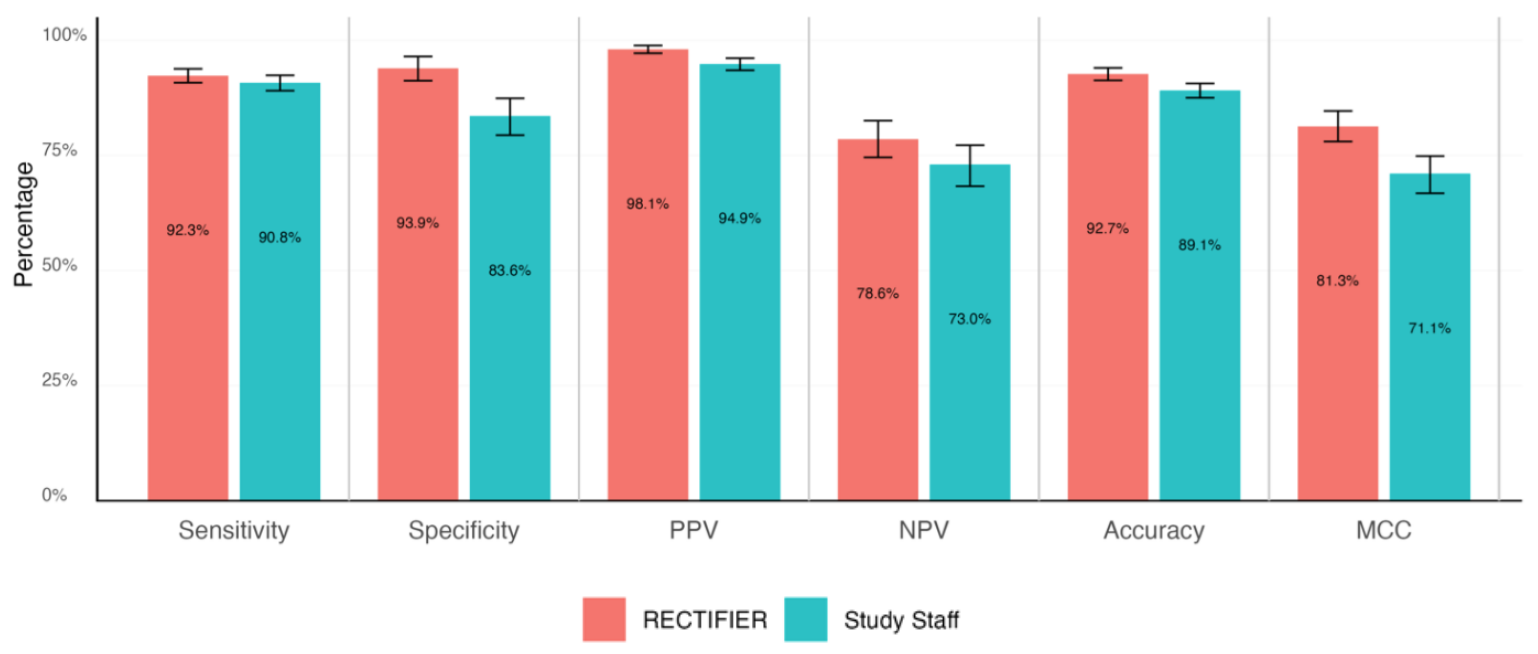
RECTIFIER schnitt genauso gut und in einigen Fällen sogar besser ab als die Mitarbeiter der Studie. Das wahrscheinlich wichtigste Ergebnis der Studie war der Kostenvergleich.
Es wurden zwar keine Zahlen für die Vergütung des Studienpersonals genannt, aber sie muss deutlich höher gewesen sein als die Kosten für die Verwendung von GPT-4V, die zwischen $0,02 und $0,10 pro Patient lagen. Die Bewertung eines Pools von 1.000 potenziellen Kandidaten durch KI würde nur wenige Minuten dauern und etwa $100 kosten.
Die Forscher kamen zu dem Schluss, dass die Verwendung eines KI-Modells wie GPT-4V mit RAG die Genauigkeit bei der Identifizierung von Kandidaten für klinische Studien beibehalten oder verbessern kann, und zwar effizienter und viel kostengünstiger als der Einsatz von menschlichem Personal.
Sie wiesen zwar darauf hin, dass bei der Übergabe der medizinischen Versorgung an automatisierte Systeme Vorsicht geboten ist, aber es scheint, dass die KI bei richtiger Anleitung bessere Arbeit leisten kann als wir.



