

Forscher der UC San Diego und der New York University haben V* entwickelt, einen LLM-geführten Suchalgorithmus, der wesentlich besser als GPT-4V in der Lage ist, den Kontext zu verstehen und bestimmte visuelle Elemente in Bildern präzise zu finden.
Multimodale Large Language Models (MLLM) wie OpenAIs GPT-4V haben uns letztes Jahr mit ihrer Fähigkeit, Fragen zu Bildern zu beantworten, umgehauen. So beeindruckend GPT-4V auch ist, es hat manchmal Probleme, wenn Bilder sehr komplex sind, und übersieht oft kleine Details.
Der V*-Algorithmus verwendet ein Visual Question Answering (VQA) LLM, um zu ermitteln, auf welchen Bereich des Bildes er sich konzentrieren muss, um eine visuelle Anfrage zu beantworten. Die Forscher nennen diese Kombination Show, sEArch, and telL (SEAL).
Wenn Ihnen jemand ein hochauflösendes Bild gibt und Ihnen eine Frage dazu stellt, würde Ihre Logik Sie dazu veranlassen, einen Bereich zu vergrößern, in dem Sie das fragliche Objekt am ehesten finden. SEAL verwendet V*, um Bilder auf ähnliche Weise zu analysieren.
Ein visuelles Suchmodell könnte ein Bild einfach in Blöcke unterteilen, in jeden Block hineinzoomen und ihn dann verarbeiten, um das betreffende Objekt zu finden, aber das ist rechnerisch sehr ineffizient.
Bei einer Textabfrage zu einem Bild versucht V* zunächst, das Bildziel direkt zu lokalisieren. Gelingt dies nicht, bittet es das MLLM, mit gesundem Menschenverstand zu ermitteln, in welchem Bereich des Bildes das Ziel am wahrscheinlichsten zu finden ist.
Die Suche konzentriert sich dann nur auf diesen Bereich, anstatt das gesamte Bild zu durchsuchen.

Wenn GPT-4V aufgefordert wird, Fragen zu einem Bild zu beantworten, das eine umfangreiche visuelle Verarbeitung von hochauflösenden Bildern erfordert, hat es Schwierigkeiten. SEAL mit V* schneidet viel besser ab.

Auf die Frage "Welche Art von Getränk können wir aus diesem Automaten kaufen?" SEAL antwortete "Coca-Cola", während GPT-4V fälschlicherweise auf "Pepsi" tippte.
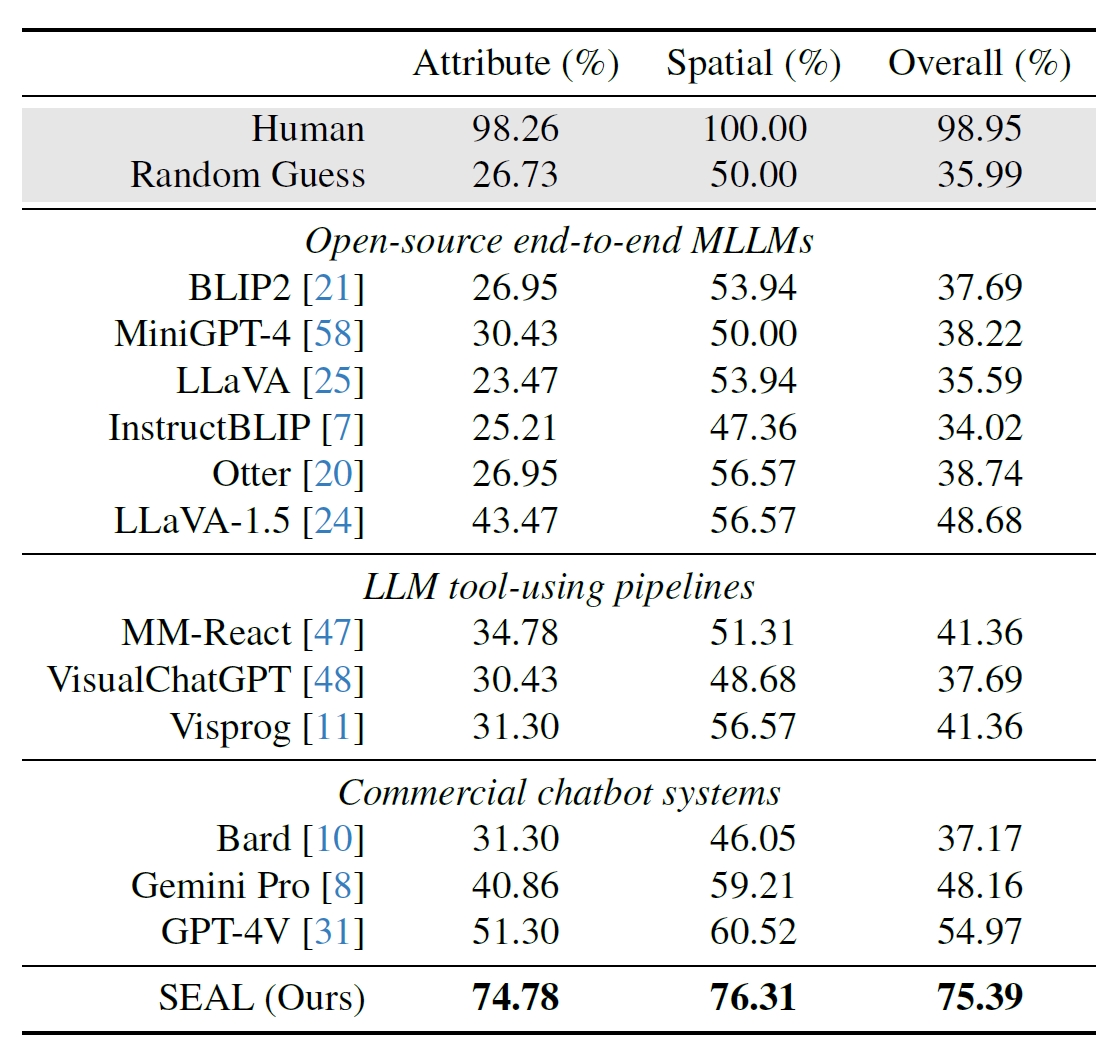
Die Forscher verwendeten 191 hochauflösende Bilder aus dem Segment Anything (SAM)-Datensatz von Meta und erstellten einen Benchmark, um zu sehen, wie die Leistung von SEAL im Vergleich zu anderen Modellen ist. Der V*Bench-Benchmark testet zwei Aufgaben: die Erkennung von Attributen und das Erkennen von räumlichen Beziehungen.
Die folgenden Abbildungen zeigen die menschliche Leistung im Vergleich zu Open-Source-Modellen, kommerziellen Modellen wie GPT-4V und SEAL. Der Anstieg der Leistung von SEAL durch V* ist besonders beeindruckend, weil die zugrunde liegende MLLM LLaVa-7b ist, die viel kleiner als GPT-4V ist.
Dieser intuitive Ansatz zur Analyse von Bildern scheint wirklich gut zu funktionieren, denn es gibt eine Reihe beeindruckender Beispiele auf der Website Zusammenfassung des Papiers auf GitHub.
Es wird interessant sein zu sehen, ob andere MLLMs wie die von OpenAI oder Google einen ähnlichen Ansatz verfolgen.
Auf die Frage, welches Getränk aus dem Automaten im obigen Bild verkauft wurde, antwortete Googles Bard: "Es gibt keinen Automaten im Vordergrund." Vielleicht wird Gemini Ultra es besser machen.
Im Moment sieht es so aus, als ob SEAL und sein neuartiger V*-Algorithmus einigen der größten multimodalen Modelle bei der visuellen Befragung um einiges voraus sind.



