

Google DeepMind hat eine Reihe neuer Tools veröffentlicht, die Robotern helfen sollen, schneller und effizienter in neuen Umgebungen autonom zu lernen.
Die Ausbildung eines Roboters für eine bestimmte Aufgabe in einer bestimmten Umgebung ist eine relativ einfache technische Aufgabe. Wenn Roboter in Zukunft wirklich nützlich für uns sein sollen, müssen sie in der Lage sein, eine Reihe allgemeiner Aufgaben auszuführen und lernen, diese in Umgebungen auszuführen, die sie vorher nicht kannten.
Letztes Jahr veröffentlichte DeepMind seine RT-2 Robotik-Steuerungsmodell und RT-X-Roboterdatensätze. RT-2 setzt Sprach- oder Textbefehle in Roboteraktionen um.
Die von DeepMind angekündigten neuen Werkzeuge bauen auf RT-2 auf und bringen uns autonomen Robotern näher, die verschiedene Umgebungen erkunden und neue Fähigkeiten erlernen.
In den letzten zwei Jahren haben große Basismodelle bewiesen, dass sie in der Lage sind, die Welt um uns herum wahrzunehmen und zu verstehen, was eine wichtige Möglichkeit für die Skalierung der Robotik darstellt.
Wir stellen AutoRT vor, ein Framework für die Orchestrierung von Roboteragenten in der freien Wildbahn unter Verwendung von Basismodellen! pic.twitter.com/x3YdO10kqq
- Keerthana Gopalakrishnan (@keerthanpg) 4. Januar 2024
AutoRT
AutoRT kombiniert ein grundlegendes Large Language Model (LLM) mit einem Visual Language Model (VLM) und einem Robotersteuerungsmodell wie RT-2.
Der VLM ermöglicht es dem Roboter, die vor ihm liegende Szene zu bewerten und die Beschreibung an den LLM weiterzugeben. Der LLM wertet die identifizierten Objekte und die Szene aus und erstellt dann eine Liste möglicher Aufgaben, die der Roboter ausführen könnte.
Die Aufgaben werden auf der Grundlage ihrer Sicherheit, der Fähigkeiten des Roboters und der Frage bewertet, ob der Versuch, die Aufgabe zu lösen, der AutoRT-Wissensbasis neue Fähigkeiten oder eine größere Vielfalt hinzufügen würde.
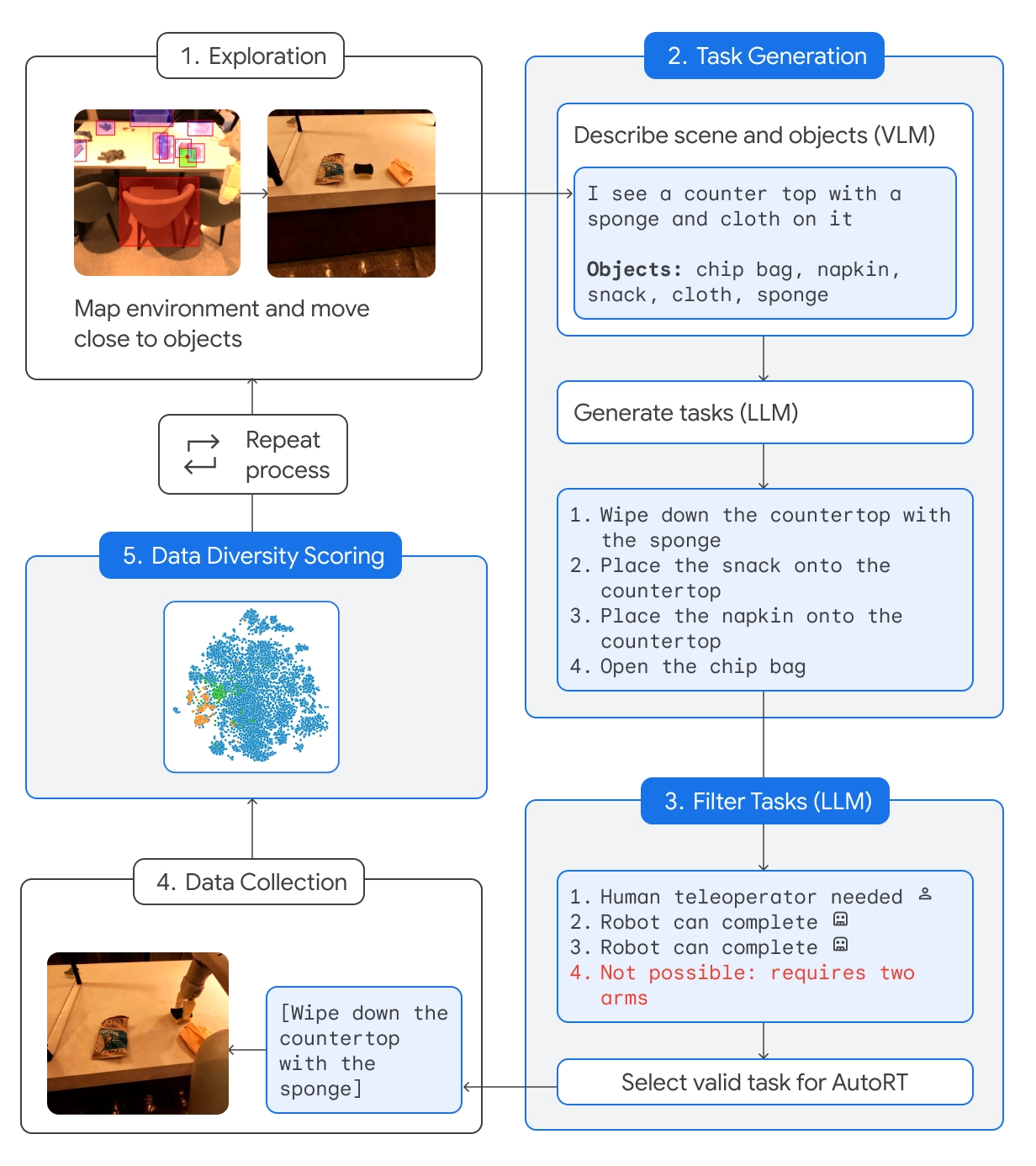
DeepMind sagt, dass sie mit AutoRT "bis zu 20 Roboter gleichzeitig und insgesamt bis zu 52 einzelne Roboter in einer Vielzahl von Bürogebäuden sicher orchestriert haben, wobei sie einen vielfältigen Datensatz mit 77.000 Roboterversuchen für 6.650 einzelne Aufgaben gesammelt haben".
Robotische Verfassung
Wenn man einen Roboter in neue Umgebungen schickt, wird er mit potenziell gefährlichen Situationen konfrontiert, die nicht im Voraus geplant werden können. Durch die Verwendung einer Roboterverfassung als Leitfaden werden den Robotern allgemeine Sicherheitsleitplanken an die Hand gegeben.
Der Aufbau des Roboters ist von Isaac Asimovs 3 Gesetzen der Robotik inspiriert:
- Ein Roboter darf einen Menschen nicht verletzen.
- Dieser Roboter darf keine Aufgaben ausführen, die Menschen, Tiere oder Lebewesen betreffen. Dieser Roboter darf nicht mit scharfen Gegenständen, wie z. B. einem Messer, interagieren.
- Dieser Roboter hat nur einen Arm und kann daher keine Aufgaben ausführen, die zwei Arme erfordern. Er kann zum Beispiel keine Flasche öffnen.
Die Einhaltung dieser Richtlinien verhindert, dass der Roboter eine Aufgabe aus der Liste der Optionen auswählt, die jemanden verletzen oder sich selbst oder etwas anderes beschädigen könnte.
SARA-RT
Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT) nutzt Modelle wie RT-2 und macht sie effizienter.
Die Architektur des neuronalen Netzes von RT-2 stützt sich auf Aufmerksamkeitsmodule mit quadratischer Komplexität. Das bedeutet, dass bei einer Verdopplung des Inputs durch Hinzufügen eines neuen Sensors oder Erhöhung der Kameraauflösung die vierfachen Rechenressourcen benötigt werden.
SARA-RT verwendet ein lineares Aufmerksamkeitsmodell zur Feinabstimmung des Robotermodells. Dies führte zu einer Verbesserung der Geschwindigkeit um 14% und der Genauigkeit um 10%.
RT-Trajektorie
Eine einfache Aufgabe wie das Abwischen eines Tisches in Anweisungen umzuwandeln, denen ein Roboter folgen kann, ist kompliziert. Die Aufgabe muss von natürlicher Sprache in eine kodierte Abfolge von Motorbewegungen und Drehungen umgewandelt werden, um die beweglichen Teile des Roboters anzutreiben.
RT-Trajectory fügt ein visuelles 2D-Overlay zu einem Trainingsvideo hinzu, so dass der Roboter intuitiv lernen kann, welche Art von Bewegung zur Erfüllung der Aufgabe erforderlich ist.
Anstatt den Roboter nur anzuweisen, den Tisch zu reinigen", kann er durch die Demonstration und die Bewegungsüberlagerung die neue Fähigkeit schneller erlernen.
DeepMind sagt, dass ein von RT-Trajectory gesteuerter Arm "eine Aufgabenerfolgsrate von 63% erreichte, verglichen mit 29% für RT-2".
🔵 Es kann auch Flugbahnen erstellen, indem es menschliche Demonstrationen beobachtet, Skizzen versteht und sogar VLM-generierte Zeichnungen.
Bei der Prüfung von 41 Aufgaben, die in den Trainingsdaten nicht vorkamen, erreichte ein mit RT-Trajectory gesteuerter Arm eine Erfolgsquote von 63%. https://t.co/rqOnzDDMDI pic.twitter.com/bdhi9W5TWi
- Google DeepMind (@GoogleDeepMind) 4. Januar 2024
DeepMind stellt diese Modelle und Datensätze anderen Entwicklern zur Verfügung. Es wird interessant sein zu sehen, wie diese neuen Werkzeuge die Integration von KI-gesteuerten Robotern in den Alltag beschleunigen.



