

Mistral AI ist ein französisches KI-Startup, das mit seinen leichtgewichtigen Open-Source-Modellen für Schlagzeilen sorgt. Mit der Aufmerksamkeit kam auch eine neue Finanzierungsrunde, denn diese Woche sicherte sich das Unternehmen Investitionen in Höhe von 385 Mio. EUR bzw. $414 Mio. EUR.
Die zweite Finanzierungsrunde des Unternehmens wurde von den Risikokapitalfirmen Andreessen Horowitz und Lightspeed Venture Partners angeführt.
Die Diskussion über Open-Source-Modelle gegenüber proprietären Modellen ist noch nicht abgeschlossen, und Mistral AI steht fest auf der Open-Source-Seite.
Unternehmen wie OpenAI haben sich für ihre Angstmacherei kritisiert über die Sicherheit von Open-Source-Modellen. Viele sagen, dass es sich um einen Fall handelt, in dem Big Tech versucht, seine Vorherrschaft zu behalten.
Mistral AI sagt, dass es durch das Training seiner eigenen Modelle, "die Veröffentlichung dieser Modelle und die Förderung von Beiträgen der Community, eine glaubwürdige Alternative zum entstehenden KI-Oligopol aufbauen kann. Generative Modelle mit offener Gewichtung werden in der kommenden KI-Revolution eine zentrale Rolle spielen".
Mehrere große Investoren haben ihr Vertrauen in diese Strategie bestätigt. Mit der Finanzierung, die Mistral AI diese Woche erhalten hat, wird das Unternehmen mit $2 Milliarden bewertet. Das ist ein 7-facher Anstieg der Bewertung in den sechs Monaten seit dem Start des Unternehmens.
Mixtral 8x7B
Im September wurde Mistral 7B veröffentlicht, das kleine, aber leistungsstarke LLM von Mistral AI, das die größeren Open-Source-Modelle wie Meta's Llama 2 34B.
Die proprietären GPT-Modelle von OpenAI gelten zu Recht als Goldstandard für den Vergleich von Modellleistungen. Mit dem neuen Modell von Mistral AI, Mixtral 8x7Bhat sich das Unternehmen in dieser Hinsicht ein bedeutendes Angeberrecht gesichert.
Mixtral 8x7B ist ein sparse Mixture-of-Experts Modell mit einem 32k-Kontextfenster. Hier sehen Sie, wie es in Benchmark-Tests im Vergleich zu Llama 2 und GPT-3.5 abgeschnitten hat.
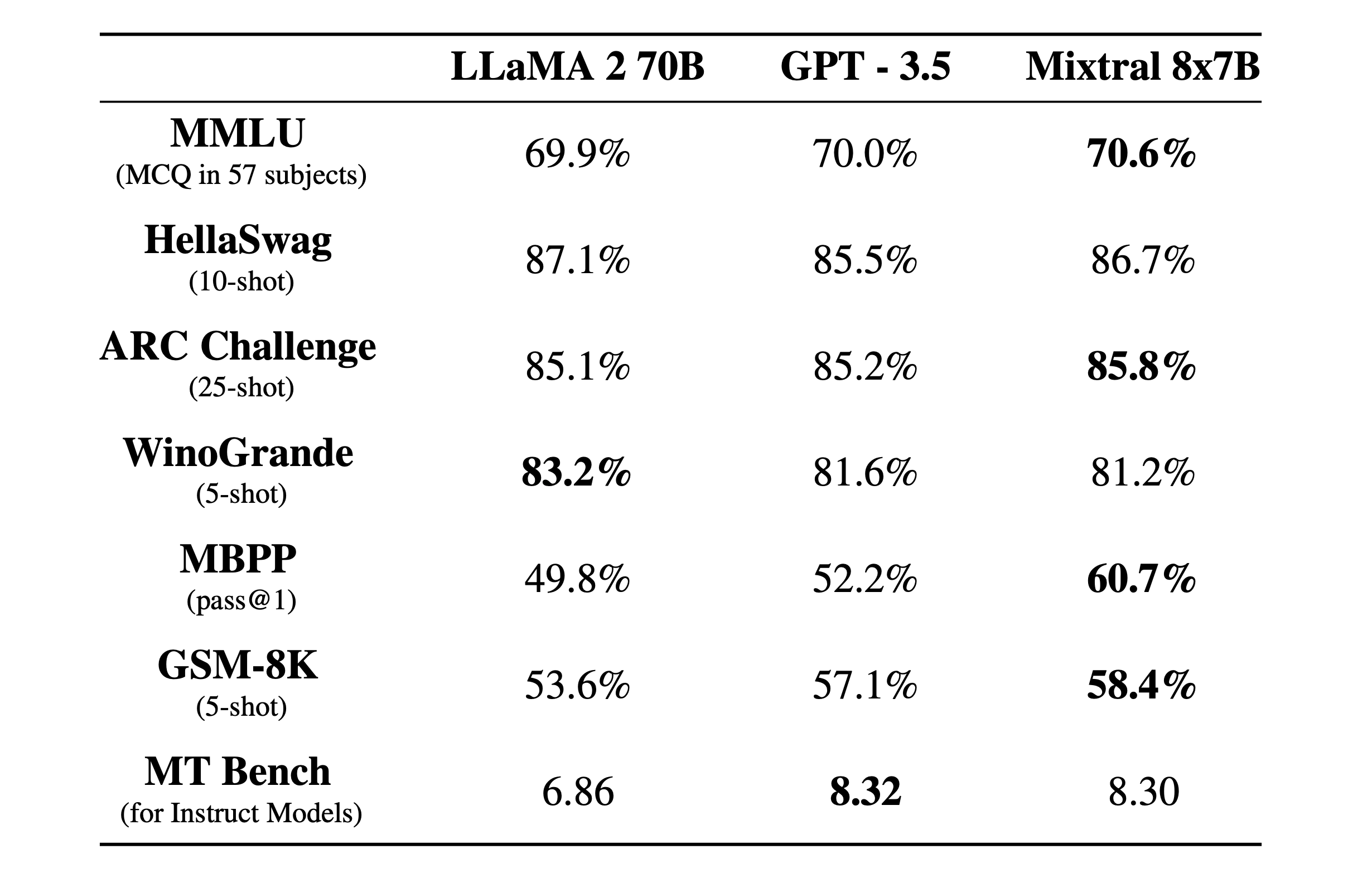
Die Benchmark-Tests sind eine gute Möglichkeit, sich einen Eindruck davon zu verschaffen, wie gut ein Modell verschiedene Funktionen ausführen kann. Die oben genannten Tests waren:
- MMLU (MCQ in 57 Fächern): Steht für Multiple-Choice-Fragen in 57 Fächern.
- HellaSwag (10-Schuss): Bewertet die Fähigkeit der KI, das Ende eines Szenarios vorherzusagen, nachdem ihr 10 Beispiele vorgegeben wurden.
- ARC-Herausforderung (25 Schüsse): Prüft das Verständnis der KI für wissenschaftliche Konzepte und logisches Denken, nachdem sie 25 Beispiele erhalten hat, aus denen sie lernen kann, bevor sie getestet wird.
- WinoGrande (5-Schuss): Testet den gesunden Menschenverstand auf der Grundlage der Auflösung von Mehrdeutigkeiten in Sätzen, mit 5 Beispielen, aus denen die KI lernen kann.
- MBPP (pass@1): Testet die Fähigkeit eines KI-Modells, korrekte Python-Code-Schnipsel zu erzeugen. Die pass@1-Kennzahl misst den Prozentsatz der Probleme, bei denen die erste Vervollständigung durch das Modell korrekt war.
- GSM-8K (5-Schuss): Der Grade School Math 8K Benchmark testet die Fähigkeit einer KI, mathematische Wortaufgaben auf dem Niveau zu lösen, das in der Grundschule erwartet wird, nachdem sie 5 Beispiele erhalten hat.
- MT Bench (für Instruct Models): Machine Translation Benchmark for Instruct Models misst, wie gut eine KI Anweisungen im Kontext von Übersetzungsaufgaben befolgen kann.
Noch beeindruckender als die Benchmark-Testergebnisse ist, wie klein und effizient der Mixtral 8x7B ist. Sie könnten dieses Modell lokal auf einem anständigen Laptop mit etwa 32 GB RAM betreiben.
Mit viel mehr Geld zur Verfügung, können wir einige spannende Entwicklungen von Mistral AI erwarten.



