

Anfang des Monats verkündete Google stolz, dass sein leistungsstärkstes Gemini-Modell den GPT-4 bei den MMLU-Benchmark-Tests (Massive Multitask Language Understanding) geschlagen hat. Microsofts neue Prompting-Technik sorgt dafür, dass GPT-4 den Spitzenplatz zurückerobert, wenn auch nur um einen Bruchteil eines Prozents.
Abgesehen von dem Drama um sein Marketingvideo ist Googles Gemini eine große Sache für das Unternehmen, und seine MMLU-Benchmark-Ergebnisse sind beeindruckend. Aber Microsoft, der größte Investor von OpenAI, hat nicht lange gewartet, um die Bemühungen von Google in den Schatten zu stellen.
Die Schlagzeile lautet, dass Microsoft mit GPT-4 die MMLU-Ergebnisse von Gemini Ultra übertreffen konnte. In Wirklichkeit hat es das Gemini-Ergebnis von 90,04% nur um 0,06% übertroffen.
Die Hintergründe, die dies möglich gemacht haben, sind spannender als die schrittweise Verbesserung, die wir auf diesen Ranglisten sehen. Microsofts neue Eingabeaufforderungstechniken könnten die Leistung älterer KI-Modelle steigern.
Erinnern Sie sich daran, wie Googles noch nicht veröffentlichtes Gemini Ultra gerade GPT-4 geschlagen hat, um die beste KI zu werden?
Nun, Microsoft hat soeben gezeigt, dass GPT-4 bei entsprechender Aufforderung Gemini in den Benchmarks tatsächlich schlägt.
Auch bei älteren Modellen gibt es noch viel Spielraum für Verbesserungen. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12. Dezember 2023
Medprompt
Wenn man von der "Steuerung" eines Modells spricht, meint man damit, dass man ein Modell durch sorgfältige Eingabe so lenken kann, dass es ein Ergebnis liefert, das besser mit dem gewünschten Ergebnis übereinstimmt.
Microsoft hat eine Kombination von Eingabeaufforderungstechniken entwickelt, die sich in dieser Hinsicht als sehr gut erwiesen haben. Medprompt begann als Projekt, um GPT-4 dazu zu bringen, bessere Ergebnisse bei medizinischen Benchmarks wie der MultiMedQA-Testsuite zu liefern.
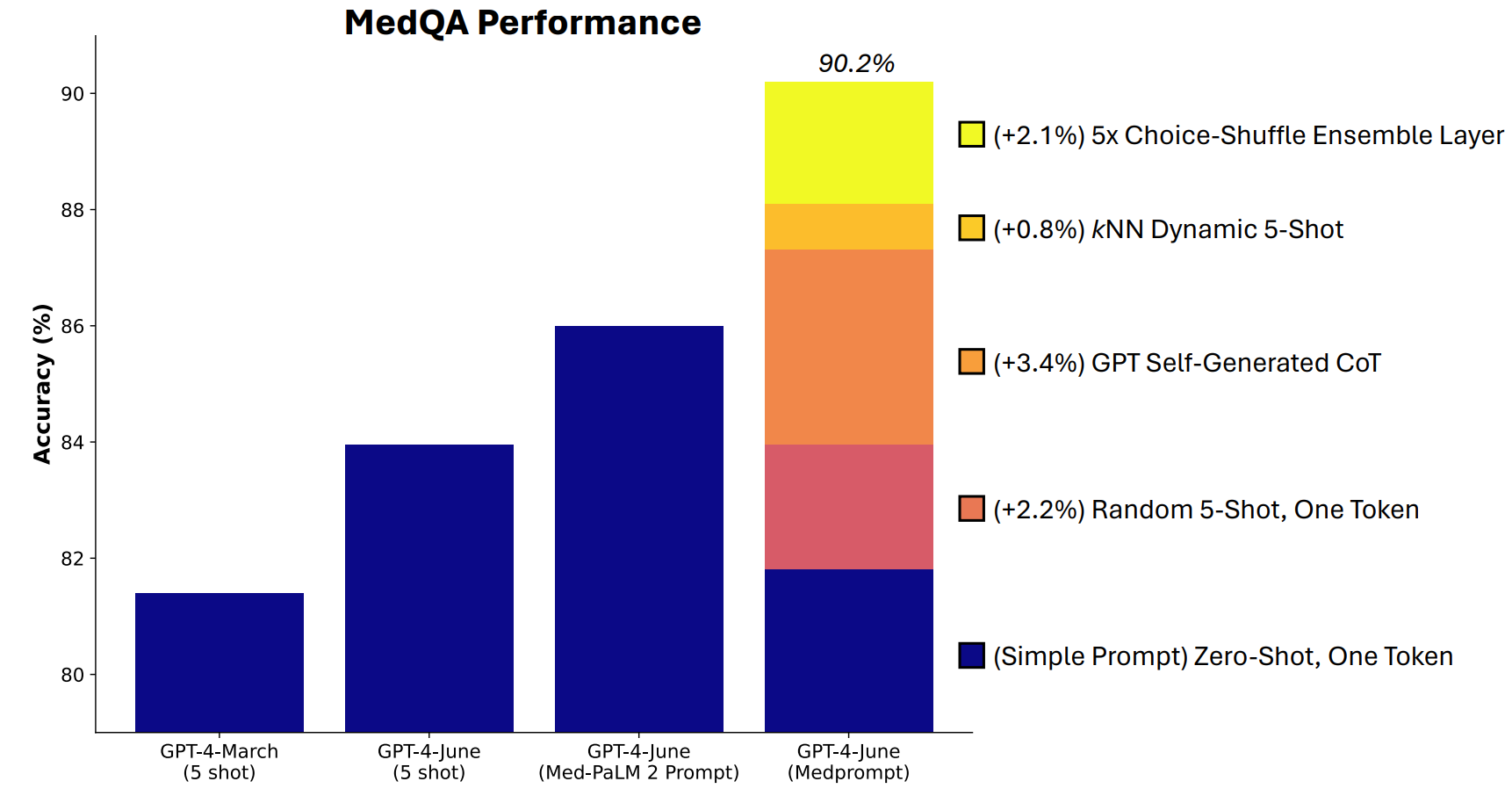
Die Microsoft-Forscher waren der Meinung, dass Medprompt, wenn es bei medizinischen Spezialtests gut funktioniert, auch die allgemeine Leistung von GPT-4 verbessern könnte. Und so gewannen Microsoft und OpenAI mit GPT-4 gegenüber Gemini Ultra wieder das Recht auf Prahlerei.
Wie funktioniert Medprompt?
Medprompt ist eine Kombination cleverer Souffleurtechniken, die alle in einem Gerät vereint sind. Es stützt sich auf drei Haupttechniken.
Dynamisches Few-Shot-Lernen (DFSL)
"Few-shot learning" bedeutet, dass GPT-4 einige Beispiele erhält, bevor es ein ähnliches Problem lösen soll. Wenn Sie einen Hinweis wie "5-shot" sehen, bedeutet dies, dass dem Modell 5 Beispiele gegeben wurden. "Zero-shot" bedeutet, dass es ohne Beispiele antworten musste.
In der Medprompt-Veröffentlichung wird erklärt, dass "aus Gründen der Einfachheit und Effizienz die wenigen Beispiele, die bei der Eingabeaufforderung für eine bestimmte Aufgabe verwendet werden, in der Regel fest sind; sie bleiben bei allen Testbeispielen unverändert".
Dies führt dazu, dass die Beispiele, die den Modellen präsentiert werden, oft nur in groben Zügen relevant oder repräsentativ sind.
Wenn Ihre Trainingsmenge groß genug ist, können Sie das Modell dazu bringen, alle Beispiele durchzusehen und diejenigen auszuwählen, die dem zu lösenden Problem semantisch ähnlich sind. Das Ergebnis ist, dass die Beispiele, die in wenigen Schritten gelernt werden, spezifischer auf ein bestimmtes Problem ausgerichtet sind.
Selbsterzeugte Gedankenkette (CoT)
Gedankenketten (Chain of Thought, CoT) sind eine gute Möglichkeit, ein LLM zu steuern. Wenn Sie ihn mit "Denke sorgfältig nach" oder "Löse es Schritt für Schritt" auffordern, sind die Ergebnisse viel besser.
Sie können die Denkkette, der das Modell folgen soll, sehr viel spezifischer gestalten, aber das erfordert eine manuelle Eingabeaufforderung.
Die Forscher fanden heraus, dass sie "GPT-4 einfach auffordern konnten, eine Gedankenkette für die Trainingsbeispiele zu erstellen". Ihr Ansatz sagt GPT-4 im Grunde: "Hier ist eine Frage, die Antwortmöglichkeiten und die richtige Antwort. Welche CoT sollten wir in eine Aufforderung einbauen, die zu dieser Antwort führt?
Choice Shuffle Ensembling
Die meisten der MMLU-Benchmark-Tests sind Multiple-Choice-Fragen. Wenn ein KI-Modell diese Fragen beantwortet, kann es zu einer Verzerrung der Position kommen. Mit anderen Worten, es könnte im Laufe der Zeit Option B bevorzugen, obwohl dies nicht immer die richtige Antwort ist.
Choice Shuffle Ensembling mischt die Positionen der Antwortmöglichkeiten und lässt GPT-4 die Frage erneut beantworten. Dies geschieht mehrere Male, und dann wird die am häufigsten gewählte Antwort als endgültige Antwort ausgewählt.
Die Kombination dieser drei Souffleurtechniken gab Microsoft die Möglichkeit, die Ergebnisse von Gemini ein wenig in den Schatten zu stellen. Es wird interessant sein, zu sehen, welche Ergebnisse Gemini Ultra erzielen würde, wenn es einen ähnlichen Ansatz verwenden würde.
Medprompt ist spannend, weil es zeigt, dass ältere Modelle sogar noch mehr leisten können, als wir dachten, wenn wir sie auf clevere Weise anregen. Die zusätzliche Rechenleistung, die für diese zusätzlichen Schritte benötigt wird, macht diesen Ansatz in den meisten Fällen jedoch nicht praktikabel.



