Das Video von Google, in dem die Fähigkeiten des neuen Modells Gemini vorgestellt werden, war schlichtweg erstaunlich. Leider bleibt die Wahrheit darüber, wie gut Gemini ist und was es kann, hinter dem Marketing-Hype zurück.
Als wir zum ersten Mal das Demovideo sahen, in dem Gemini in Echtzeit mit dem Moderator interagiert, waren wir überwältigt. Wir waren so begeistert, dass wir einige wichtige Haftungsausschlüsse am Anfang übersehen und das Video für bare Münze genommen haben.
Im Text in den ersten Sekunden des Videos heißt es: "Wir haben Filmmaterial aufgenommen, um ihn bei einer Vielzahl von Herausforderungen zu testen, indem wir ihm eine Reihe von Bildern gezeigt und ihn gebeten haben, über das, was er sieht, nachzudenken."
Was wirklich hinter den Kulissen geschah, ist die Ursache für die Kritik an Google und die ethischen Fragen, die sich daraus ergeben.
Gemini sah sich kein Live-Video an, in dem der Moderator eine Ente zeichnete oder Tassen umherschob. Und Gemini reagierte auch nicht auf die Sprachanweisungen, die Sie hörten. Das Video war eine stilisierte Marketingpräsentation einer einfacheren Wahrheit.
In Wirklichkeit wurde Gemini mit Standbildern und Textaufforderungen präsentiert, die detaillierter waren als die Fragen, die Sie vom Moderator hören.
Ein Google-Sprecher bestätigte, dass es sich bei den Worten, die Sie im Video hören, um "echte Auszüge aus den tatsächlichen Eingabeaufforderungen handelt, die zur Erstellung der folgenden Gemini-Ausgabe verwendet wurden".
Also detaillierte Textaufforderungen, Standbilder und Textantworten. Was Google tatsächlich demonstrierte, war eine Funktionalität, die GPT-4 schon seit Monaten hat.
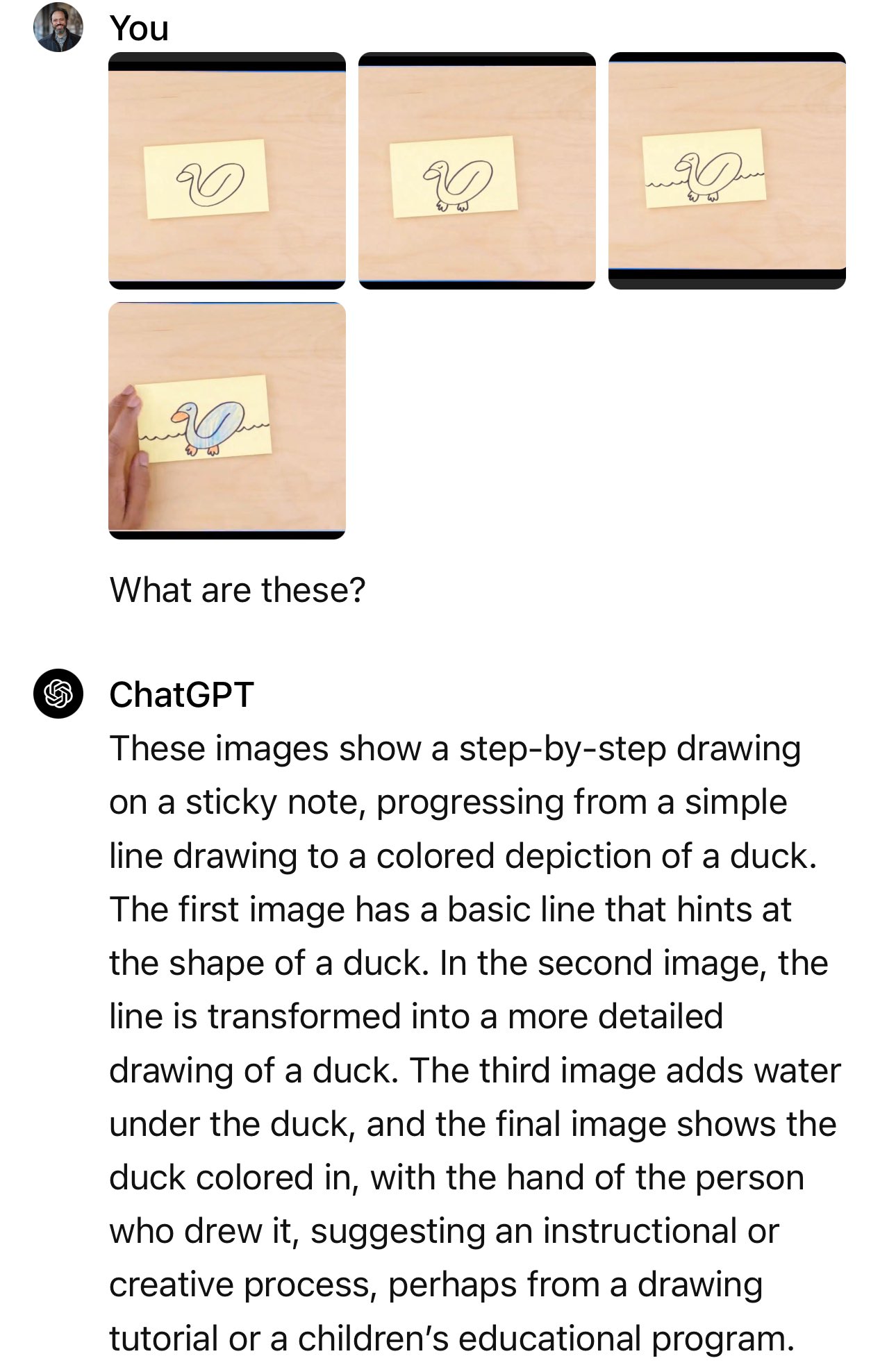
Google's Blog-Eintrag zeigt die tatsächlich verwendeten Standbilder und Texteinblendungen.
Im Beispiel des Autos fragt der Moderator: "Welches dieser Autos würde aufgrund seiner Konstruktion schneller fahren?"
Die eigentliche Aufforderung lautete: "Welches dieser Autos ist aerodynamischer? Das auf der linken oder auf der rechten Seite? Erkläre, warum, und verwende dabei spezifische visuelle Details."
Und wenn man das Experiment auf Bard nachstellt, das jetzt von Gemini betrieben wird, klappt es nicht immer.

Ich wollte wirklich glauben, dass Zwillinge dem Ball folgen können, während die drei Becher herumgeschoben werden, aber leider stimmt auch das nicht.
Aus Googles Blogbeitrag geht hervor, dass für die Demo des Bechermischens eine Menge Aufforderungen und Erklärungen erforderlich waren.

Es ist immer noch beeindruckend, dass ein KI-Modell so etwas kann, aber es ist nicht das, was uns in dem Video verkauft wurde.
War's das, Google?
Wir spekulieren hier nur, aber die Demo zeigt höchstwahrscheinlich Ergebnisse, die Google mit Gemini Ultra erzielt hat, das noch nicht veröffentlicht wurde.
Wenn Gemini Ultra schließlich auf den Markt kommt, wird es wohl in der Lage sein, das zu tun, was GPT-4 schon seit Monaten tut. Die Implikationen sind nicht großartig.
Stoßen wir in Bezug auf die KI-Fähigkeiten an eine Grenze? Denn wenn die besten KI-Köpfe bei Google arbeiten, dann treiben sie sicherlich bahnbrechende Innovationen voran.
Oder ist Google nicht nur langsam ins Rennen gegangen, sondern hat auch Mühe, mit den anderen mitzuhalten? Die Benchmark-Zahlen, die Google stolz präsentierte, zeigen, dass sein noch nicht veröffentlichtes Modell den GPT-4 in einigen Tests knapp übertrifft. Wie wird es sich gegen GPT-5 schlagen?
Oder vielleicht hat sich die Marketingabteilung von Google bei ihrem Video geirrt, aber Gemini Ultra wird trotzdem besser sein, als wir denken. Google sagt, dass Gemini wirklich multimodal ist und dass es Video versteht, was wirklich eine Premiere für LLMs sein wird.
Wir haben noch keinen LLM gesehen, der Videoverstehen demonstriert, aber wenn wir das tun, wird es sich lohnen, sich darauf zu freuen. Wird es Gemini Ultra oder GPT-5 sein, das es uns zuerst zeigt?