

Große Sprachmodelle (Large Language Models, LLM) werden oft durch Verzerrungen oder irrelevanten Kontext in einer Eingabeaufforderung in die Irre geführt. Forscher von Meta haben einen scheinbar einfachen Weg gefunden, dies zu beheben.
Wenn die Kontextfenster größer werden, können die Aufforderungen, die wir in ein LLM eingeben, länger und immer detaillierter werden. LLMs sind besser darin geworden, die Nuancen oder kleineren Details in unseren Aufforderungen zu erkennen, aber manchmal kann sie das verwirren.
Frühe maschinelle Lernverfahren verwendeten einen "Hard-Attention"-Ansatz, bei dem der relevanteste Teil einer Eingabe herausgefiltert und nur auf diesen reagiert wurde. Das funktioniert gut, wenn Sie versuchen, ein Bild zu beschriften, aber schlecht, wenn Sie einen Satz übersetzen oder eine vielschichtige Frage beantworten wollen.
Die meisten LLMs verwenden heute einen "Soft-Attention"-Ansatz, bei dem der gesamte Prompt mit Token versehen und gewichtet wird.
Meta schlägt einen Ansatz vor, der System 2 Aufmerksamkeit (S2A), um das Beste aus beiden Welten zu erhalten. S2A nutzt die natürlichen Sprachverarbeitungsfähigkeiten eines LLM, um Ihre Eingabeaufforderung aufzugreifen und voreingenommene und irrelevante Informationen zu entfernen, bevor es an die Arbeit geht, eine Antwort zu geben.
Hier ist ein Beispiel.

S2A löscht die Informationen zu Max, da sie für die Frage irrelevant sind. S2A generiert eine optimierte Eingabeaufforderung neu, bevor es mit der Bearbeitung der Frage beginnt. LLMs sind notorisch schlecht in Mathe Daher ist es eine große Hilfe, die Aufforderung weniger verwirrend zu gestalten.
LLMs sind sehr menschenfreundlich und stimmen Ihnen gerne zu, selbst wenn Sie falsch liegen. S2A entfernt alle Verzerrungen in einer Eingabeaufforderung und verarbeitet dann nur die relevanten Teile der Aufforderung. Dies reduziert das, was KI-Forscher als "Kriecherei" bezeichnen, oder die Neigung eines KI-Modells zum Arschkriechen.

S2A ist eigentlich nur eine Systemaufforderung, die den LLM anweist, die ursprüngliche Aufforderung ein wenig zu verfeinern, bevor er sich an die Arbeit macht. Die Ergebnisse, die die Forscher mit Mathematik-, Sach- und Langformfragen erzielten, waren beeindruckend.
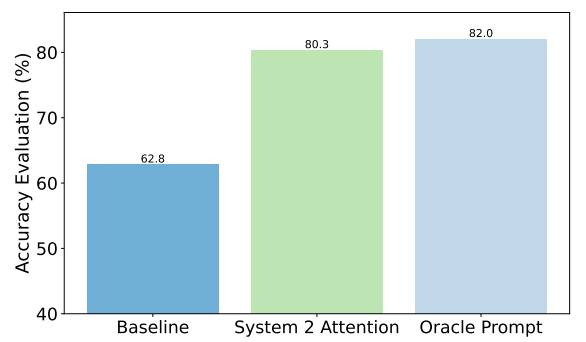
Hier ein Beispiel für die Verbesserungen, die S2A bei Sachfragen erzielte. Die Ausgangsbasis waren Antworten auf Fragen, die Verzerrungen enthielten, während die Oracle-Aufforderung eine von Menschen verfeinerte ideale Aufforderung war.
S2A kommt den Ergebnissen der Oracle-Eingabeaufforderung sehr nahe und bietet eine Verbesserung der Genauigkeit um fast 50% gegenüber der Grundeinstellung.
Wo ist also der Haken? Durch die Vorverarbeitung der ursprünglichen Eingabeaufforderung vor der Beantwortung entstehen zusätzliche Rechenanforderungen für den Prozess. Wenn die Eingabeaufforderung lang ist und viele relevante Informationen enthält, kann die Neuerstellung der Eingabeaufforderung erhebliche Kosten verursachen.
Es ist unwahrscheinlich, dass die Nutzer besser darin werden, gut formulierte Prompts zu schreiben, so dass S2A ein guter Weg sein könnte, dies zu umgehen.
Wird Meta S2A in sein Programm aufnehmen? Lama Modell? Wir wissen es nicht, aber Sie können den S2A-Ansatz selbst nutzen.
Wenn Sie darauf achten, dass Sie in Ihren Aufforderungen keine Meinungen oder Vorschläge machen, ist es wahrscheinlicher, dass Sie genaue Antworten von diesen Modellen erhalten.



