

Elon Musk kündigte den Beta-Start des Chatbots Grok von xAI an, und die ersten Statistiken geben uns einen Eindruck davon, wie er im Vergleich zu anderen Modellen abschneidet.
Die Grok-Chatbot basiert auf xAIs Frontier-Modell namens Grok-1, das das Unternehmen in den letzten vier Monaten entwickelt hat. xAI hat nicht gesagt, mit wie vielen Parametern es trainiert wurde, hat aber einige Zahlen für seinen Vorgänger genannt.
Grok-0, der Prototyp des aktuellen Modells, wurde mit 33 Milliarden Parametern trainiert, so dass wir wahrscheinlich davon ausgehen können, dass Grok-1 mit mindestens ebenso vielen Parametern trainiert wurde.
Das klingt nicht nach viel, aber xAI behauptet, dass die Leistung von Grok-0 "an die Fähigkeiten von LLaMA 2 (70B) bei Standard-LM-Benchmarks heranreicht", obwohl nur die Hälfte der Trainingsressourcen verwendet wurde.
In Ermangelung einer Parameterangabe müssen wir uns auf das Wort des Unternehmens verlassen, wenn es Grok-1 als "hochmodern" und "deutlich leistungsfähiger" als Grok-0 bezeichnet.
Grok-1 wurde auf Herz und Nieren geprüft, indem es mit diesen Standard-Benchmarks für maschinelles Lernen bewertet wurde:
- GSM8k: Mathe-Wortaufgaben für die Mittelstufe
- MMLU: Multidisziplinäre Multiple-Choice-Fragen
- HumanEval: Aufgabe zur Vervollständigung von Python-Code
- MATH: In LaTeX geschriebene Mathematikaufgaben für die Mittel- und Oberstufe
Hier ist eine Zusammenfassung der Ergebnisse.
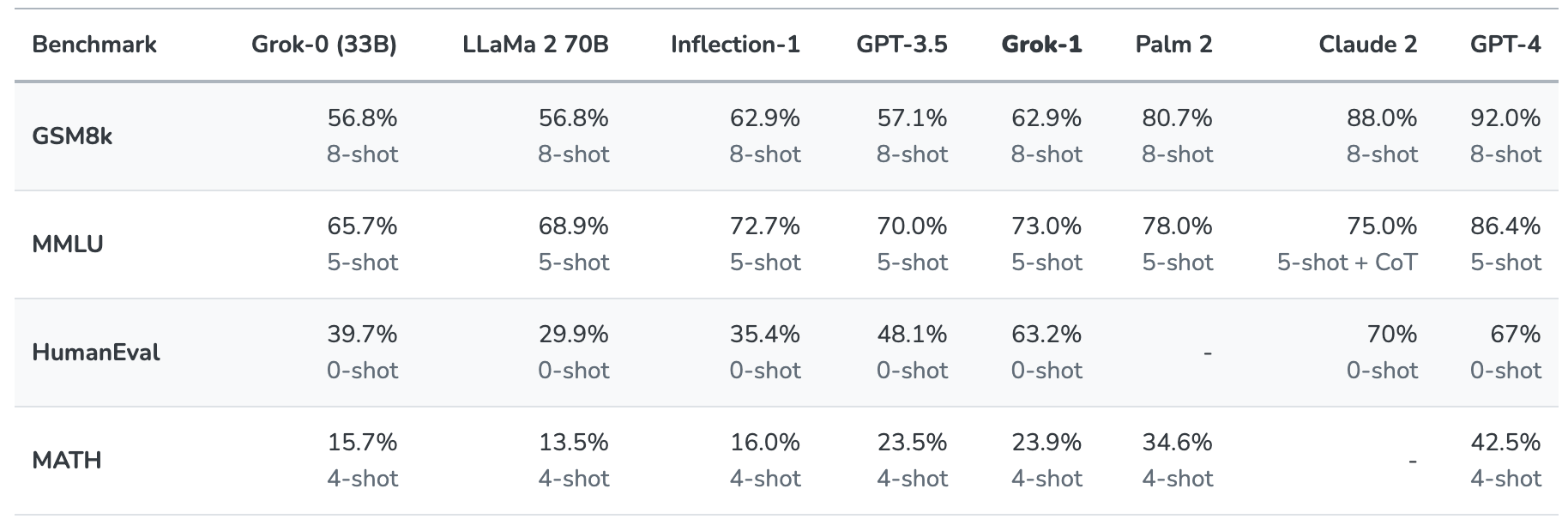
Die Ergebnisse sind insofern interessant, als sie uns zumindest eine Vorstellung davon vermitteln, wie Grok im Vergleich zu anderen Grenzmodellen abschneidet.
xAI sagt, dass diese Zahlen zeigen, dass Grok-1 "alle anderen Modelle in seiner Rechenklasse" übertrifft und nur von Modellen geschlagen wurde, die mit einer "deutlich größeren Menge an Trainingsdaten und Rechenressourcen" trainiert wurden.
GPT-3.5 hat 175 Milliarden Parameter, so dass wir davon ausgehen können, dass Grok-1 weniger als das hat, aber wahrscheinlich mehr als die 33 Milliarden des Prototyps.
Der Grok-Chatbot ist für Aufgaben wie die Beantwortung von Fragen, Informationsbeschaffung, kreatives Schreiben und Unterstützung bei der Programmierung vorgesehen. Aufgrund seines kleineren Kontextfensters wird er wahrscheinlich eher für kürzere Interaktionen als für superschnelle Anwendungsfälle verwendet.
Mit einer Kontextlänge von 8.192 hat Grok-1 nur die Hälfte des Kontexts, den GPT-3.5 hat. Dies ist ein Hinweis darauf, dass xAI wahrscheinlich beabsichtigte, dass Grok-1 einen längeren Kontext gegen eine bessere Effizienz eintauscht.
Das Unternehmen sagt, dass sich einige seiner aktuellen Forschungen auf das "Verstehen und Abrufen von langen Kontexten" konzentrieren, so dass die nächste Version von Grok möglicherweise ein größeres Kontextfenster haben wird.
Der genaue Datensatz, der für das Training von Grok-1 verwendet wurde, ist nicht klar, aber er enthält mit ziemlicher Sicherheit Ihre Tweets über X, und der Grok-Chatbot hat auch Echtzeit-Zugang zum Internet.
Wir müssen auf weitere Rückmeldungen von Betatestern warten, um ein reales Gefühl dafür zu bekommen, wie gut das Modell tatsächlich ist.
Wird Grok uns helfen, die Geheimnisse des Lebens, des Universums und von allem anderen zu enträtseln? Vielleicht noch nicht ganz, aber es ist ein unterhaltsamer Anfang.



