

Nvidia hat eine neue Open-Source-Software angekündigt, die die Inferenzleistung seiner H100-Grafikprozessoren verbessern soll.
Ein Großteil der aktuellen Nachfrage nach Nvidias Grafikprozessoren besteht darin, Rechenleistung für das Training neuer Modelle aufzubauen. Aber sobald diese Modelle trainiert sind, müssen sie auch genutzt werden. Inferenz in der KI bezieht sich auf die Fähigkeit eines LLM wie ChatGPT, Schlussfolgerungen zu ziehen oder Vorhersagen aus den Daten zu treffen, auf denen es trainiert wurde, und eine Ausgabe zu erzeugen.
Wenn Sie versuchen, ChatGPT zu benutzen und eine Meldung erscheint, dass die Server überlastet sind, liegt das daran, dass die Computerhardware mit der Nachfrage nach Schlussfolgerungen nicht Schritt halten kann.
Nvidia sagt, dass seine neue Software, TensorRT-LLM, seine bestehende Hardware viel schneller und energieeffizienter machen kann.
Die Software enthält optimierte Versionen der beliebtesten Modelle, darunter Meta Llama 2, OpenAI GPT-2 und GPT-3, Falcon, Mosaic MPT und BLOOM.
Es verwendet einige clevere Techniken wie eine effizientere Stapelung von Inferenzaufgaben und Quantisierungstechniken, um die Leistung zu steigern.
LLMs verwenden in der Regel 16-Bit-Gleitkommawerte zur Darstellung von Gewichten und Aktivierungen. Bei der Quantisierung werden diese Werte während der Inferenz auf 8-Bit-Gleitkommawerte reduziert. Den meisten Modellen gelingt es, ihre Genauigkeit mit dieser reduzierten Präzision beizubehalten.
Unternehmen, die über eine auf Nvidias H100-GPUs basierende Recheninfrastruktur verfügen, können durch den Einsatz von TensorRT-LLM eine enorme Verbesserung der Inferenzleistung erwarten, ohne einen Cent ausgeben zu müssen.
Nvidia verwendete ein Beispiel für die Ausführung eines kleinen Open-Source-Modells, GPT-J 6, um Artikel im CNN/Daily Mail-Datensatz zusammenzufassen. Sein älterer A100-Chip wird als Basisgeschwindigkeit verwendet und dann mit dem H100 ohne und dann mit TensorRT-LLM verglichen.
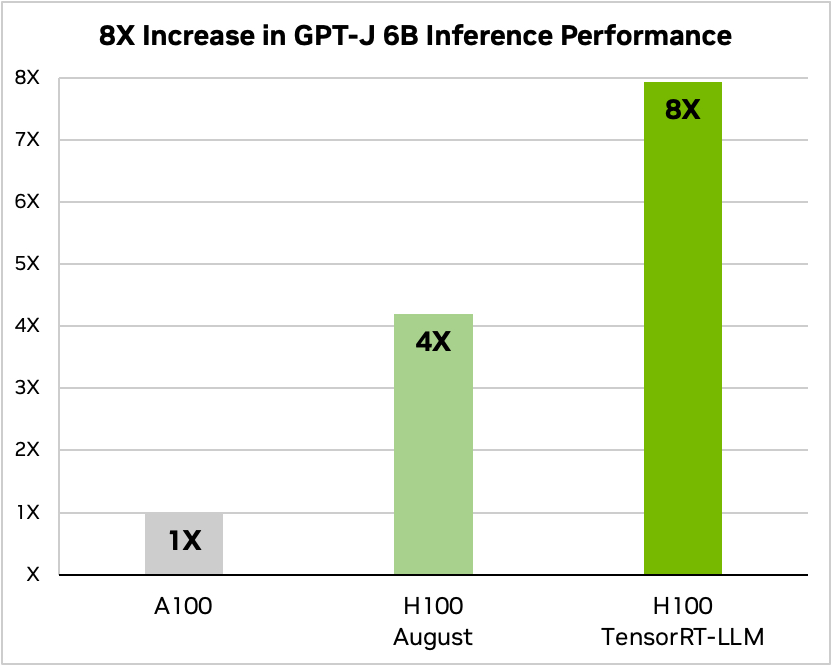
Quelle: Nvidia
Und hier ist ein Vergleich mit Meta's Llama 2
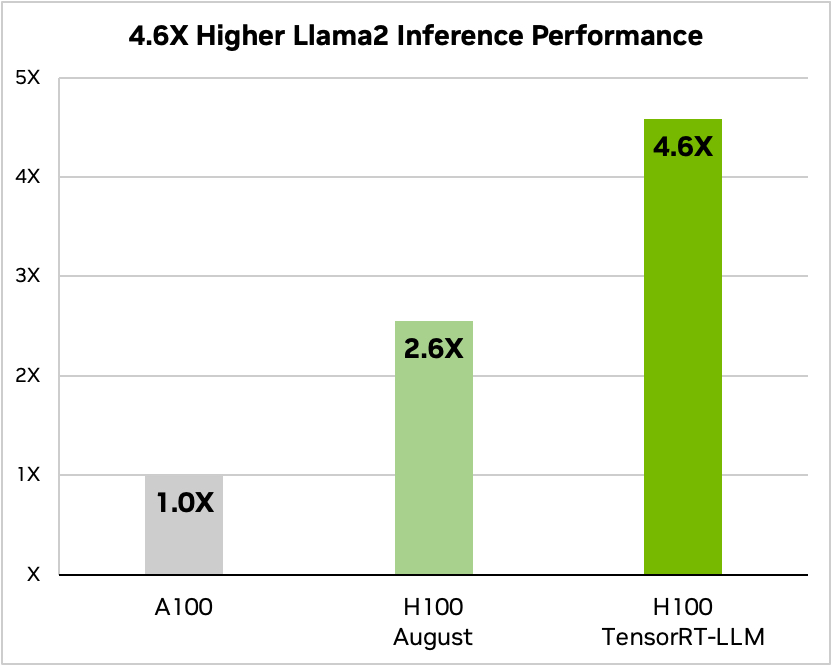
Quelle: Nvidia
Laut Nvidia haben die Tests gezeigt, dass ein H100 mit TensorRT-LLM je nach Modell zwischen 3,2 und 5,6 Mal weniger Energie verbraucht als ein A100 während der Inferenz.
Wenn Sie KI-Modelle auf H100-Hardware ausführen, bedeutet dies nicht nur, dass sich Ihre Inferenzleistung fast verdoppelt, sondern auch, dass Ihre Energierechnung nach der Installation dieser Software um ein Vielfaches niedriger ausfallen wird.
TensorRT-LLM wird auch für Nvidia's Grace Hopper Superchips aber das Unternehmen hat keine Leistungsdaten für das GH200 mit seiner neuen Software veröffentlicht.
Die neue Software war noch nicht fertig, als Nvidia seinen GH200 Superchip den branchenüblichen MLPerf AI-Leistungstests unterzog. Die Ergebnisse zeigten, dass der GH200 bis zu 17% besser abschnitt als ein Single-Chip H100 SXM.
Wenn Nvidia mit dem GH200 auch nur einen bescheidenen Anstieg der Inferenzleistung mit TensorRT-LLM erreicht, wird das Unternehmen seine nächsten Konkurrenten weit hinter sich lassen. Ein Vertriebsmitarbeiter für Nvidia zu sein, muss im Moment der einfachste Job der Welt sein.



