
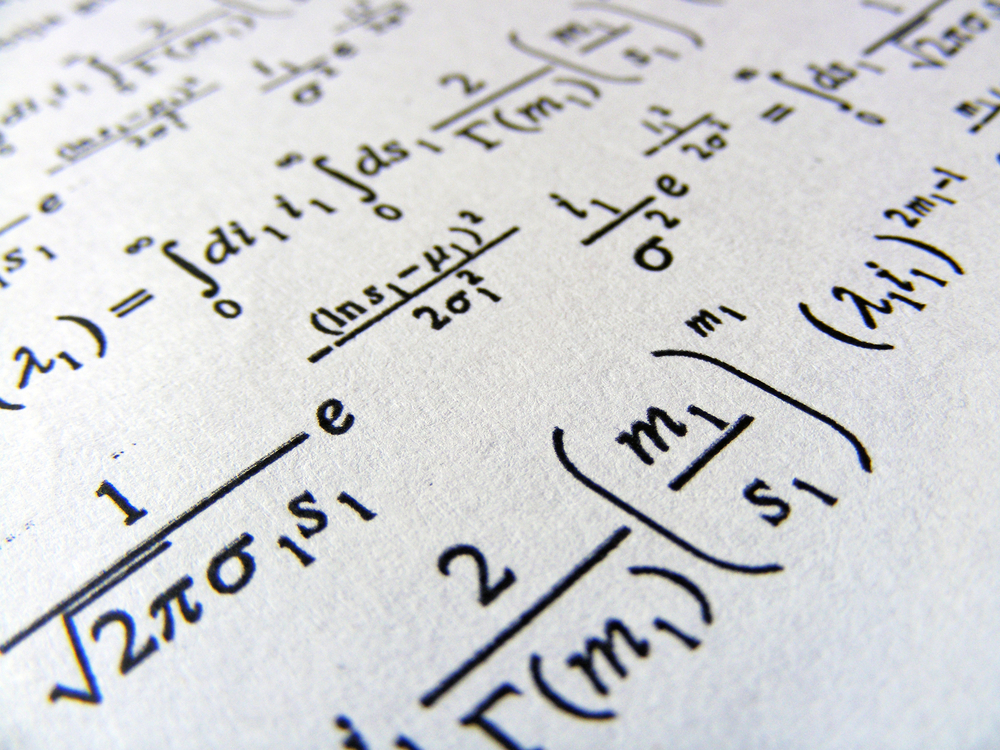
Meta hat ein neues KI-Modell namens Nougat entwickelt, das wissenschaftliche Texte zuverlässig in maschinenlesbare Texte umwandeln kann.
Wenn Sie schon einmal versucht haben, eine wissenschaftliche Forschungsarbeit zu lesen, dann werden Sie verstehen, warum es schwierig ist, sie elektronisch zu verarbeiten. Aktuelle OCR-Tools (Optical Character Recognition) analysieren den Text Zeile für Zeile.
Bei rein textbasierten Dokumenten ist das in Ordnung, aber bei wissenschaftlichen Dokumenten kommt eine Komplexität hinzu, die mit diesen Standardwerkzeugen nicht bewältigt werden kann.
Wissenschaftliche Arbeiten enthalten mathematische und wissenschaftliche Symbole und Formeln, die oft als tiefgestellte oder hochgestellte Zeichen hinzugefügt werden. Selbst die besten OCR-Programme haben Probleme, diese richtig zu erfassen.
Was die Sache noch schwieriger macht, ist die Tatsache, dass viele dieser Forschungsarbeiten schlecht eingescannt sind und die Originale nicht mehr verfügbar sind. Nougat, die Abkürzung für Neural Optical Understanding for Academic Documents, stellt sich dieser Herausforderung.
Anstatt Zeile für Zeile zu scannen, verarbeitet Nougat die gesamte Seite mit einer Variante von Metas Vision Transformer zur Bildanalyse. Das Modell wurde anhand eines Datensatzes von Artikeln trainiert, die auf PubMed Central und arXiv veröffentlicht wurden und über entsprechenden LaTeX-Quellcode verfügten.
LaTeX ist eine Software, die zum Verfassen wissenschaftlicher Arbeiten verwendet wird, die komplexe Formeln und mathematische Symbole erfordern. Das Modell wurde trainiert, indem das Bild des Papiers betrachtet und mit dem Code verglichen wurde, der den komplexen Text erzeugte.
Hier ist ein Beispiel für eines von Metas Experimenten zur Digitalisierung eines alten Forschungspapiers.

Quelle: Meta
Weitere beeindruckende Beispiele finden sich auf der Website Facebook Forschungsseite.
Nougat ist nicht perfekt, erreicht aber dennoch einen BLEU-Score von über 91% und eine Genauigkeit von über 96% bei Fließtext. Der BLEU-Score misst die Ähnlichkeit des maschinell übersetzten Textes mit einer Reihe von hochwertigen Referenzübersetzungen.
Bei Formeln und Tabellen schnitt es mit einer Genauigkeit von knapp über 75% etwas schlechter ab. Das ist immer noch viel besser als konkurrierende Modelle wie GROBID, die es nur in 11% der Fälle schaffen, richtig zu liegen.
Es gibt Millionen von Forschungsseiten, die nicht indizierbar oder durchsuchbar sind, weil sie nur von Menschen gelesen werden können. Nougat ändert das, indem es ermöglicht, selbst schlecht gescannte Forschungs-PDFs in maschinenlesbaren Text zu konvertieren.
Wie bei so vielen anderen neuen Tools hat Meta auch dieses frei zugänglich gemacht verfügbar auf GitHub. Allerdings könnte diese Entwicklung auch ein gewisses Eigeninteresse beinhalten. Sobald alte Forschungsarbeiten maschinenlesbar sind, stehen sie für das Training anderer KI-Modelle zur Verfügung.
Es wird interessant sein zu sehen, welche lange verschollenen Forschungsperlen mit Nougat wiederentdeckt werden.



