

Stanford University released its AI Index Report 2024 which noted that AI’s rapid advancement makes benchmark comparisons with humans increasingly less relevant.
The annual report provides a comprehensive insight into the trends and state of AI developments. The report says that AI models are improving so fast now that the benchmarks we use to measure them are increasingly becoming irrelevant.
A lot of industry benchmarks compare AI models to how good humans are at performing tasks. The Massive Multitask Language Understanding (MMLU) benchmark is a good example.
It uses multiple-choice questions to evaluate LLMs across 57 subjects, including math, history, law, and ethics. The MMLU has been the go-to AI benchmark since 2019.
The human baseline score on the MMLU is 89.8%, and back in 2019, the average AI model scored just over 30%. Just 5 years later, Gemini Ultra became the first model to beat the human baseline with a score of 90.04%.
The report notes that current “AI systems routinely exceed human performance on standard benchmarks.” The trends in the graph below seem to indicate that the MMLU and other benchmarks need replacing.
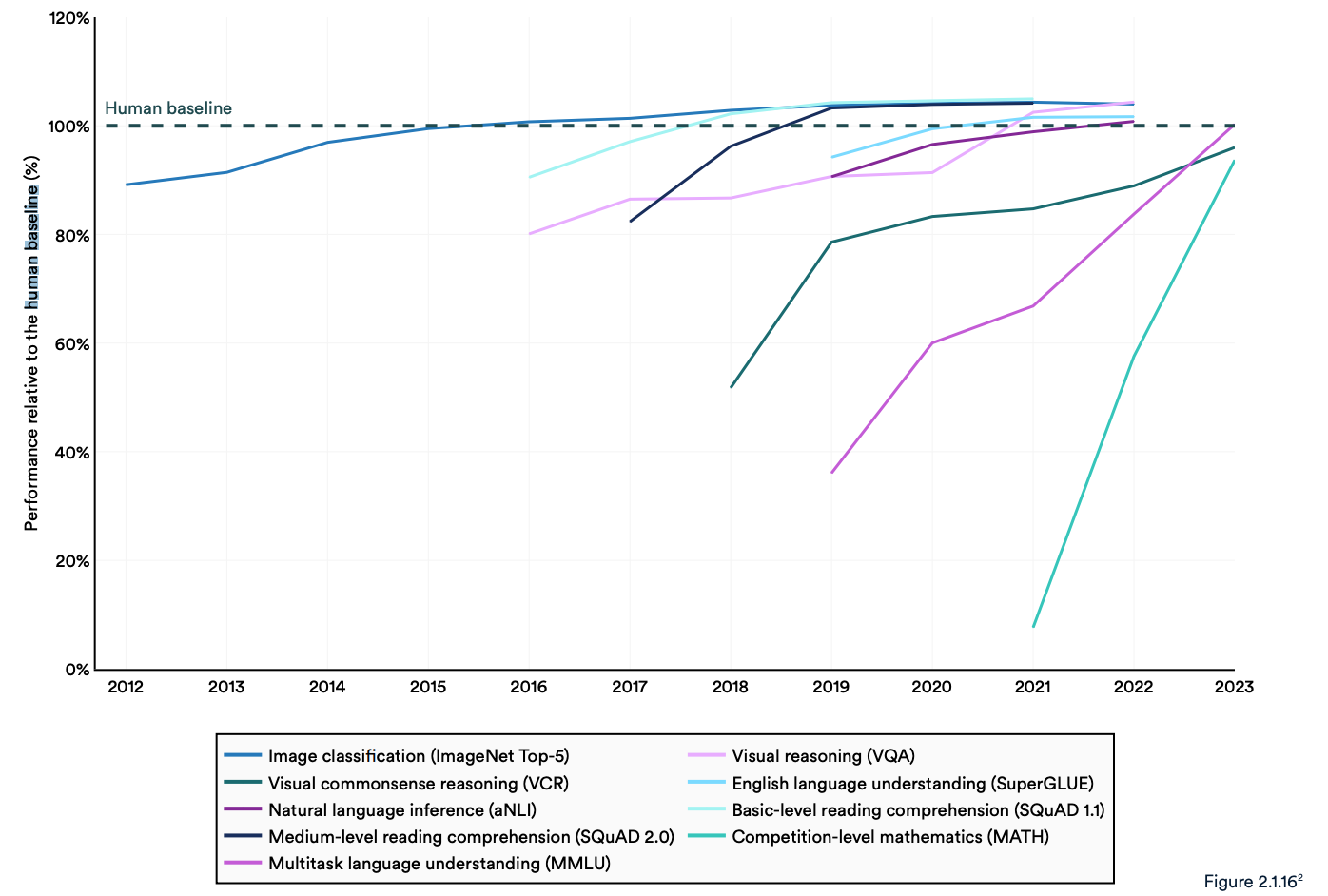
AI models have reached performance saturation on established benchmarks such as ImageNet, SQuAD, and SuperGLUE so researchers are developing more challenging tests.
One example is the Graduate-Level Google-Proof Q&A Benchmark (GPQA), which allows AI models to be benchmarked against really smart people, rather than average human intelligence.
The GPQA test consists of 400 tough graduate-level multiple-choice questions. Experts who have or are pursuing their PhDs correctly answer the questions 65% of the time.
The GPQA paper says that when asked questions outside their field, “highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web.”
Last month Anthropic announced that Claude 3 scored just under 60% with 5-shot CoT prompting. We’re going to need a bigger benchmark.
Claude 3 gets ~60% accuracy on GPQA. It’s hard for me to understate how hard these questions are—literal PhDs (in different domains from the questions) with access to the internet get 34%.
PhDs *in the same domain* (also with internet access!) get 65% – 75% accuracy. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
— david rein (@idavidrein) March 4, 2024
Human evaluations and safety
The report noted that AI still faces significant problems: “It cannot reliably deal with facts, perform complex reasoning, or explain its conclusions.”
Those limitations contribute to another AI system characteristic that the report says is poorly measured; AI safety. We don’t have effective benchmarks that allow us to say, “This model is safer than that one.”
That’s partly because it’s difficult to measure, and partly because “AI developers lack transparency, especially regarding the disclosure of training data and methodologies.”
The report noted that an interesting trend in the industry is to crowd-source human evaluations of AI performance, rather than benchmark tests.
Ranking a model’s image aesthetics or prose is difficult to do with a test. As a result, the report says that “benchmarking has slowly started shifting toward incorporating human evaluations like the Chatbot Arena Leaderboard rather than computerized rankings like ImageNet or SQuAD.”
As AI models watch the human baseline disappear in the rear-view mirror, sentiment may eventually determine which model we choose to use.
The trends indicate that AI models will eventually be smarter than us and harder to measure. We may soon find ourselves saying, “I don’t know why, but I just like this one better.”



