

OpenAI släppte inga nya modeller vid sitt Dev Day-evenemang, men nya API-funktioner kommer att locka utvecklare som vill använda sina modeller för att bygga kraftfulla appar.
OpenAI har haft några tuffa veckor med sin CTO, Mira Murati, och andra chefsforskare som ansluter sig till den ständigt växande listan över tidigare anställda. Företaget är under allt större press från andra flaggskeppsmodeller, inklusive modeller med öppen källkod som erbjuder utvecklare billigare och mycket kapabla alternativ.
De nya funktionerna som OpenAI presenterade var Realtime API (i beta), finjustering av visionen och effektivitetshöjande verktyg som snabbcaching och modelldestillation.
API i realtid
Realtids-API:t är den mest spännande nya funktionen, om än i betaversion. Det gör det möjligt för utvecklare att bygga tal-till-tal-upplevelser med låg latens i sina appar utan att använda separata modeller för taligenkänning och text-till-tal-konvertering.
Med detta API kan utvecklare nu skapa appar som möjliggör realtidskonversationer med AI, till exempel röstassistenter eller språkinlärningsverktyg, allt genom ett enda API-anrop. Det är inte riktigt den sömlösa upplevelse som GPT-4os Advanced Voice Mode erbjuder, men det är nära.
Det är dock inte billigt, med cirka $0,06 per minut för ljudinmatning och $0,24 per minut för ljudutmatning.
Det nya Realtime API från OpenAI är otrolig...
Se den beställa 400 jordgubbar genom att faktiskt RINGA till butiken med twillio. Allt med röst. 🍓🎤 pic.twitter.com/J2BBoL9yFv
- Ty (@FieroTy) 1 oktober 2024
Finjustering av visionen
Med hjälp av finjustering av bilder i API:et kan utvecklare förbättra sina modellers förmåga att förstå och interagera med bilder. Genom att finjustera GPT-4o med hjälp av bilder kan utvecklare skapa applikationer som utmärker sig i uppgifter som visuell sökning eller objektdetektering.
Den här funktionen utnyttjas redan av företag som Grab, som förbättrade noggrannheten i sin karttjänst genom att finjustera modellen för att känna igen trafikskyltar från bilder på gatunivå.
OpenAI gav också ett exempel på hur GPT-4o kunde generera ytterligare innehåll för en webbplats efter att ha finjusterats för att stilistiskt matcha webbplatsens befintliga innehåll.
Cachelagring av uppmaningar
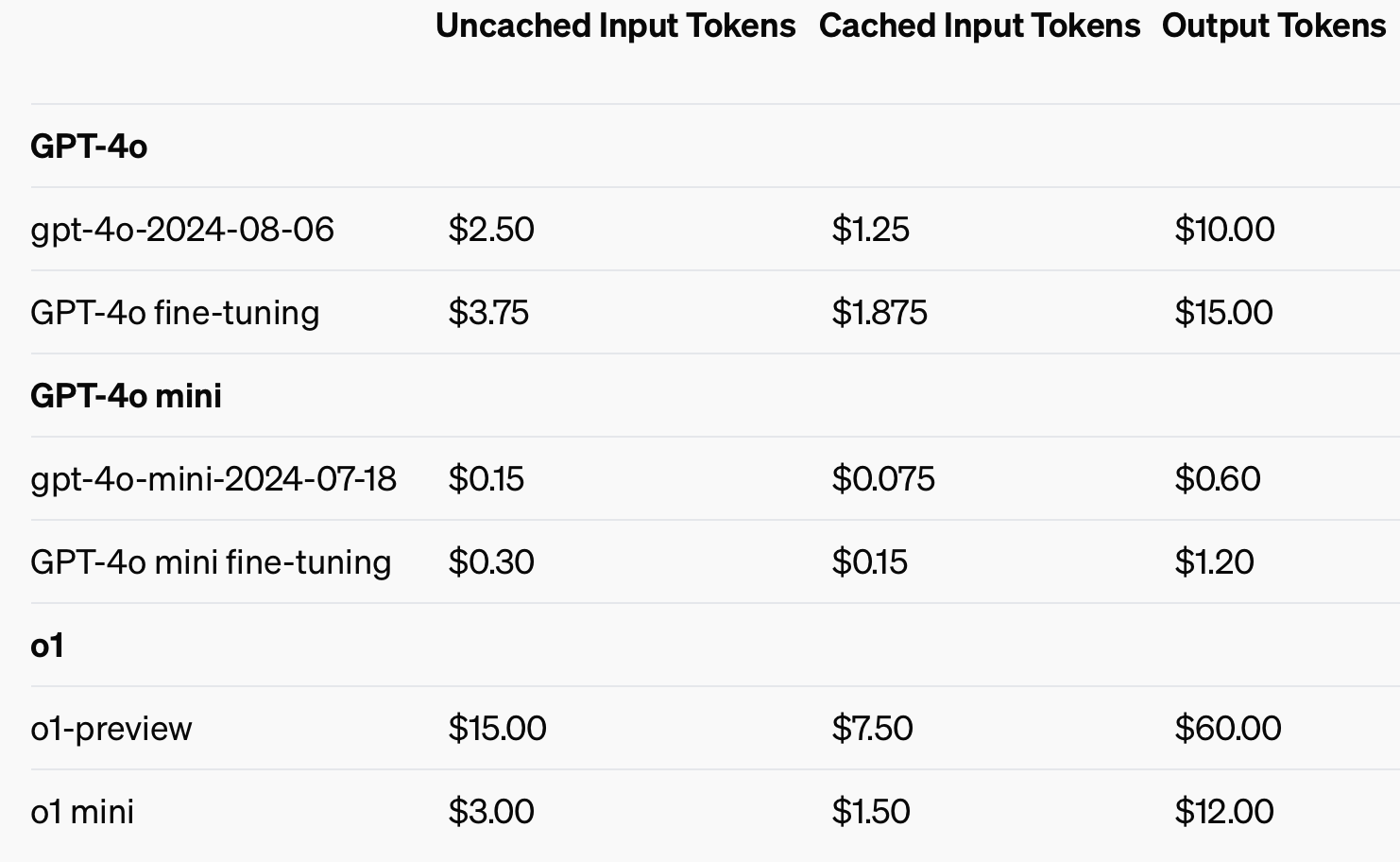
För att förbättra kostnadseffektiviteten introducerade OpenAI prompt caching, ett verktyg som minskar kostnaden och fördröjningen för ofta använda API-anrop. Genom att återanvända nyligen bearbetade inmatningar kan utvecklare sänka kostnaderna med 50% och minska svarstiderna. Denna funktion är särskilt användbar för applikationer som kräver långa konversationer eller upprepade sammanhang, som chatbots och kundtjänstverktyg.
Genom att använda cachade indata kan man spara upp till 50% i kostnader för indatatoken.
Modell destillation
Modelldestillation gör det möjligt för utvecklare att finjustera mindre, mer kostnadseffektiva modeller med hjälp av resultaten från större, mer kapabla modeller. Det här är en stor förändring eftersom destillering tidigare krävde flera separata steg och verktyg, vilket gjorde det till en tidskrävande och felbenägen process.
Innan OpenAI:s integrerade funktion för modelldestillation var utvecklarna tvungna att manuellt orkestrera olika delar av processen, som att generera data från större modeller, förbereda finjusterade dataset och mäta prestanda med olika verktyg.
Utvecklare kan nu automatiskt lagra utdatapar från större modeller som GPT-4o och använda dessa par för att finjustera mindre modeller som GPT-4o-mini. Hela processen med att skapa dataset, finjustera och utvärdera kan göras på ett mer strukturerat, automatiserat och effektivt sätt.
Den förenklade utvecklingsprocessen, den lägre latensen och de minskade kostnaderna kommer att göra OpenAI:s GPT-4o-modell till ett attraktivt alternativ för utvecklare som snabbt vill kunna distribuera kraftfulla appar. Det ska bli intressant att se vilka applikationer de multimodala funktionerna möjliggör.



